|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Прогнозирование в EViews по уравнению регрессии
Эконометрическая модель для прогнозирования будущих значений зависимой переменной обычно используется в предположении, что ситуация в будущем периоде не изменится по сравнению с анализируемым периодом. Кроме того, прогноз может осуществляться в двух вариантах: для проверки адекватности модели и для предсказания будущих значений зависимой переменной. В первом случае исследователь должен прогнозные расчёты обеспечить известными значениями независимых переменных, а во втором – спрогнозировать эти значения на перспективу. Рассмотрим первый случай. Это – так называемый безусловный прогноз. Применяется он, в основном, для проверки адекватности модели. В этом случае весь период наблюдений разбивается на две части. Первая служит для оценки параметров модели, а вторая – для оценки качества модели. Проиллюстрируем это на ранее рассмотренном примере (рисунок 3.4). В этом примере имеется 180 наблюдений (поквартальные данные с 1952г. по 1996г.). Пусть, например, последние 20 наблюдений используются для проверки качества модели (прогноз), а первые 160 наблюдений – для оценки параметров модели. C этой целью в окне «Equation» нужно выбрать «Proc/Forecast», после чего появится диалоговое окно (рисунок 3.45).
Рисунок 3.45 – Диалоговое окно прогноза
В этом окне в позиции «Forecast name» (имя прогноза) по умолчанию проставляется имя независимой переменной с добавлением буквы «f» в конце (у нас – gdpf). Если стандартные ошибки прогноза надо сохранить в рабочем файле для дальнейшего анализа, в позиции «S.E. (optional) – (стандартная ошибка (дополнительная))» нужно проставить имя для значений этих ошибок (у нас это sef). Если это поле оставить пустым, то стандартные ошибки сохранены не будут. В позиции «Forecast sample» – выборка для прогноза проставляется интервал, на котором будет осуществлён прогноз по оценённому уравнению регрессии. В позиции «Method» указано, что в уравнении нет элементов динамики (лаговых переменных), поэтому прогноз будет осуществлён по статическому варианту. Флажки в позиции «Output» указывают, что будет отражено в отчёте о прогнозе – график прогноза и значения прогнозных величин, сохранённых в Workfile под именем gdpf. После сделанного выбора получим (рисунок 3.46). 
Рисунок 3.46 – Окно прогноза На графике, показан интервальный прогноз на 20 периодов (на пять лет поквартально) с указанием интервала в виде gdpf ± 2*sef. Справа в окне отчёта указаны показатели точности прогноза. Остановимся кратко на них.
Здесь суммирование ведётся на интервале прогноза.
Значение этого коэффициента находится между нулём и единицей. Чем ближе это значение к нулю, тем точнее прогноз аппроксимирует реальные данные. Кроме того, в этом отчёте отражены ещё три характеристики точности прогноза: Bias Proportion, Variance Proportion и Covariance Proportion. По сути дела, это три составляющие квадрата RMSE и они отражают доли квадрата общей ошибки прогноза за счёт отклонения от центральной тенденции, различия в дисперсии и неполной ковариации. В сумме они всегда дают единицу. В нашем случае треть ошибки прогноза объясняется различием в дисперсии фактических и прогнозных значений зависимой переменной, а две трети – за счёт неполной ковариации этих значений. Рассчитываются эти характеристики из соотношений Bias: Variance: Covariance: Интересно сравнить фактические и прогнозные значения анализируемого признака (вычисленные по оцененному уравнению регрессии при известных значениях независимых переменных). Для этого надо сгенерировать ряды, представляющие верхнюю и нижнюю границы прогноза (se_u и se_l) и построить график четырёх рядов: gdp, gdpf, se_u и se_l. Введём в окно команд genr se_u = gdpf + 2*sef genr se_l = gdpf - 2*sef. После каждой команды щёлкнуть «Enter», тем самым будут сгенерированы нужные ряды границ прогноза и сохранены в Workfile. Затем нужно создать группу переменных gdp, gdpf, se_u и se_l (Open/as Group), скопировать нужную часть этих переменных (последние 20 наблюдений), вставить их в окно «New page» рабочего файла. Для этого надо щёлкнуть кнопкой мыши по этой заставке внизу окна «Workfile» и выбрать «Paste from Clipboard Page». В получившейся группе переменные будут названы «ser01, ser02 и т.д.». их нужно переименовать в соответствии с реальными именами, затем создать группу этих «сокращённых» переменных и построить их графики, выбрав «View/Graph/Line» в окне «Group». Получим (рисунок 3.47)
Рисунок 3.47 – Фактические (GDP) и прогнозные (GDPF) значения ряда gdp Видно, что фактические значения, начиная со второго наблюдения, сначала отклонились вниз от расчётных значений, а после 13-го наблюдения – вверх. Причём, после 16-го наблюдения эти значения вышли за границы интервального прогноза. Таким образом, признать прогноз по этому уравнению приемлемым представляется проблематичным.
Тест Чоу для прогноза
EViews представляет возможность протестировать, нет ли структурных изменений в прогнозном периоде. Для этого используется тест Чоу для прогноза (The Chow forecast test). Основан этот тест на F-статистике, которая рассчитывается для сравнения параметров выборочного и прогнозного периодов. С этой целью оцениваются отдельно параметры модели по выборке объёма Алгоритм работы теста следующий:
Чтобы реализовать этот тест, надо оценить уравнение регрессии и в окне «Equation» выбрать «View/Stability Test/Chow Forecast Test…». В появившемся диалоговом окне надо проставить дату, с которой предполагается осуществить прогноз (рисунок 3.48). В нашем случае предполагается, что прогноз будет осуществлён с первого квартала 1992г. Щёлкнув «ОК», получим (рисунок 3.49).
Рисунок 3.48 – Заполненное диалоговое окно теста Чоу для прогноза
Рисунок 3.49 – Отчёт о работе теста Чоу для прогноза
В заголовке отчёта указан выбранный прогнозный период (с первого квартала 1992г. по четвёртый квартал 1996г.), ниже – F-статистика теста (равна 8,22) и вероятность того, что её расчётное значение не превышает критического значения (она равна нулю). А далее приведено уравнение регрессии для выборочного периода (с 1952q1 по 1991q4). На основании вероятности для F-статистика теста (Probability < 0,05) делаем вывод о том, что в прогнозном периоде параметры модели различаются значимо, т.е. в прогнозном периоде произошли структурные изменения в динамике изучаемого показателя, как это мы видели на рисунке 3.47. Обратите внимание, что оценки уравнения на рисунке 3.49 отличаются от аналогичных оценок на рисунке 3.4, т.к. в этих двух случаях выборки разные. На рисунке 3.4 – это период с 1952q1 по 1996q4, а на рисунке 3.49 – с 1952q1 по 1991q4. Оценки для прогнозного периода приведены на рисунке 3.50.
Рисунке 3.50 – Отчёт об уравнении регрессии в прогнозном периоде
Сравнивая оценки для двух разных периодов (на рисунке 3.49 и на рисунке 3.50), видим, что они действительно различаются значимо. При этом расчётные и фактические значения зависимой переменной не различаются так значимо, как при рассмотрении всего периода (сравните рисунок 3.47 и рисунок 3.51). На рисунке 3.50 приведено уравнение регрессии для последних 20 наблюдений. Чтобы его получить, надо скопировать эти последние наблюдения и вставить их в новую страницу окна «Workfile», после чего переименовать переменные в соответствии с исходными именами, а затем рассчитать уравнение регрессии по этим данным.
Рисунок 3.51 – График фактических (Actual), расчётных (Fitted) значений и остатков (Residual) уравнения регрессии для прогнозного периода Тест Чоу на точку перегиба
Рассмотрим применение теста Чоу для проверки структурных изменений внутри рассматриваемой выборки (The Chow breakpoint test – тест Чоу на точку перегиба). Этот тест позволяет определить, надо ли менять спецификацию модели для различных подвыборок выборочного периода. Здесь проверяется нулевая гипотеза о том, что в выборочном периоде в исходных данных нет структурных изменений и их можно описать одним уравнением регрессии. Этот тест похож на только что рассмотренный, но в нём предполагается, что можно рассматривать не два периода, а несколько. Итак, пусть предполагается, что весь выборочный период разбит на l подпериодов, в которых изучаемый показатель претерпевает структурные изменения (разные режимы вариации). Пусть для каждого i-го периода
Известно, что при верности нулевой гипотезы эта статистика следует распределению Фишера При использовании этого теста можно указать только одну точку, тогда будет проверяться гипотеза о том, что в двух подвыборках нет структурных изменений и всю выборку можно описать одним уравнением регрессии. Если указывается, например, две точки, то будет проверяться гипотеза о том, что в трёх подвыборках нет структурных изменений (данные две точки всю выборку разделят на три подвыборки) и т.д. Рассмотрим реализацию этого теста на ранее рассмотренном примере (рисунок 3.4). После оценки уравнения регрессии по всей выборке график остатков имеет следующий вид (рисунок 3.52).
Рисунок 3.52 – График остатков (Residual) исходного уравнения
Видно (по поведению остатков), что после первого квартала 1960-го года и после второго квартала 1980-го года динамика исходных и расчётных значений расходится. Возьмём эти точки для проверки гипотезы о том, что в трёх периодах, разделённых этими точками, структурных изменений не произошло. После оценки исходного уравнения для всего периода в диалоговом окне теста Чоу проставим (рисунок 3.53).
Рисунок 3.53 – Диалоговое окно теста Чоу для двух точек перегиба
Щёлкнув «ОК», получим (рисунок 3.54).
Рисунок 3.54 – Отчёт теста Чоу для двух точек перегиба
Итак, вероятность для F-статистики теста Чоу равна нулю, следовательно, гипотеза об отсутствии структурных изменений в рассматриваемые периоды отклоняется. Если в качестве исследуемой точки взять только одну (1980q3), то результат будет следующий (рисунок 3.55).
Рисунок 3.55 – Тест Чоу для одной точки перегиба
Следовательно, в эти два периода произошло изменение динамики анализируемого показателя.
|
||
|
|
Последнее изменение этой страницы: 2018-06-01; просмотров: 1989. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |


 Rout Mean Squared Error (RMSE) – это корень квадратный из среднего квадрата ошибок – по сути дела, это стандартная ошибка прогноза, вычисляемая из соотношения
Rout Mean Squared Error (RMSE) – это корень квадратный из среднего квадрата ошибок – по сути дела, это стандартная ошибка прогноза, вычисляемая из соотношения .
. .
. .
. .
.



 и для прогнозного периода объёмом
и для прогнозного периода объёмом 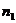 .
. с числом степеней свободы, равным n-m-1.
с числом степеней свободы, равным n-m-1. наблюдениям и получают остаточную сумму квадратов
наблюдениям и получают остаточную сумму квадратов  с числом ограничений
с числом ограничений 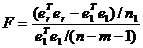 , которая следует распределению Фишера
, которая следует распределению Фишера  и с её помощью проверяется нулевая гипотеза.
и с её помощью проверяется нулевая гипотеза.



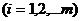 имеется
имеется  наблюдений (
наблюдений (  ). Обозначим через
). Обозначим через  – остаточную сумму квадратов для всей выборки, а через
– остаточную сумму квадратов для всей выборки, а через  – остаточную сумму квадратов для i-й подвыборки. Тогда
– остаточную сумму квадратов для i-й подвыборки. Тогда  даст остаточную сумму квадратов для всех подвыборок. Для проверки нулевой гипотезы о том, что в выборочном периоде нет структурных изменений, рассчитывается F-статистика
даст остаточную сумму квадратов для всех подвыборок. Для проверки нулевой гипотезы о том, что в выборочном периоде нет структурных изменений, рассчитывается F-статистика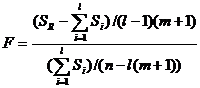 .
. . Следовательно, можно пользоваться критическими точками этого распределения для проверки выдвинутой гипотезы.
. Следовательно, можно пользоваться критическими точками этого распределения для проверки выдвинутой гипотезы.


