|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Пример на регрессионный анализ
Проиллюстрируем рассмотренные положения на примере. Для этого воспользуемся информацией, поставляемой вместе с пакетом EVievs и находящейся по адресу «EViews Workfile/data/demo». В файле «demo»находится следующая информация по экономике США: М1 – совокупный спрос на деньги, GDP – валовой внутренний продукт, PR – уровень цен, RS – краткосрочная процентная ставка (поквартально с 1952 г. по 1996 г.). По возможности на основе этих данных будем иллюстрировать обсуждаемые проблемы. Итак, выбрав «File/Open/ EViews Workfile…», войдём в диалоговое окно «Open» (рисунок 3.1).
Рисунок 3.1 – Открытие файла demo
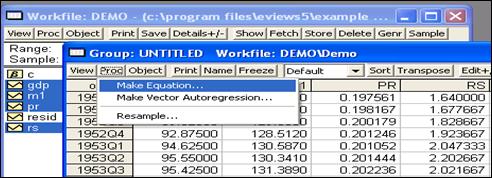
Щёлкнув «Открыть», получим список переменных, выделив которые, откроем их как группу, и затем выберем «Proc/Make Equation…» (рисунок 3.2).
Рисунок 3.2 – Выбор процедуры расчёта уравнения регрессии
В появившемся диалоговом окне «Equation Estimation» (оценка уравнения) (рисунок 3.3, выделено) указаны выбранные переменные. Причём, первая переменная в этом списке – это зависимая переменная. Остальные – независимые. При этом буква «с» указывает, что в уравнении регрессии будет присутствовать константа. Если независимая переменная окажется внутри списка переменных, то её надо с помощью правой кнопки мыши вырезать и вставить впереди списка переменных (в нашем примере это переменная gdp). Если в Вашем уравнении не должно быть константы, то «с» из этого списка надо удалить.
Рисунок 3.3 – Формирование спецификации уравнения для его оценки
В этом же диалогов окне указан метод оценки (LS – Least Squares – наименьшие квадраты) и выборка (1952q1 1996q4). Щёлкнув «ОК», получим отчёт об оцененном уравнении регрессии (рисунок 3.4). 
Рисунок 3.4 – Отчёт об уравнении регрессии
В начале отчёта указаны: зависимая переменная (GDP), метод оценивания (LS), дата и время выполнения расчётов, размах выборки и число включённых в работу наблюдений. Ниже в отчёте перечислены: регрессоры, включая константу (столбец Variable), столбец оценок параметров (Coefficient), стандартные ошибки оценок (Std. Error), t-статистики и расчётный уровень значимости (Prob.). Коэффициент множественной детерминации (R-squared) равен 0,998, следовательно, изменение GDP на 99,8% зависит от изменения включённых в регрессию переменных. Далее в отчёте указаны: исправленный коэффициент множественной детерминации (Adjusted R-squared), стандартная ошибка регрессии (S.E. of regression), сумма квадратов остатков (Sum squared resid), логарифм правдоподобия (Log likelihood), статистика Дарбина-Уотсона (Durbin-Watson stat), затем (правее) – средняя арифметическая зависимой переменной (Mean dependent var), её стандартное отклонение (S.D. dependent var), информационные критерии Акаике и Шварца, F-статистика дисперсионного анализа регрессии и расчётный уровень значимости для неё (Prob(F-statistic). Из перечисленных характеристик обсудим информационные критерии и статистику Дарбина–Уотсона. Приведённые информационные критерии по своей логике схожи с AIK = ln( Как видим, к логарифму остаточной дисперсии в этих критериях добавляется слагаемое, пропорциональное числу оцениваемых в регрессии параметров. Последнее можно считать «штрафом» за потерю числа степеней свободы в уравнении регрессии при добавлении в него дополнительных независимых переменных. При этом SIC «штрафует» сильнее, чем AIK. При выборе более предпочтительного уравнения обычно ориентируются на наименьшее значение этих критериев. Из отчёта (рисунок 3.4) видно, что одна из переменных (RS) оказалась незначимой (расчётный уровень значимости для неё оказался больше 0,05). Оценка параметра при этой переменной вычислена с большой ошибкой (ошибка больше оценки), отсюда и не значимость этой переменной. Избавимся от этой переменной. Для этого щёлкнем «Proc/Specify/Estimate…» и в появившемся диалогом окне уберём переменную RS. Получим следующее уравнение регрессии (рисунок 3.5).
Рисунок 3.5 – «Сокращённое» уравнение регрессии
Получили, как и отмечалось, что, избавившись от незначимой переменной, мы улучшили уравнение, если ориентироваться на исправленный коэффициент множественной детерминации и информационные критерии:
|
||
|
|
Последнее изменение этой страницы: 2018-06-01; просмотров: 509. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |



 . Они учитывают потерю числа степеней свободы при включении в уравнение регрессии дополнительных переменных. Рассчитываются они из соотношений
. Они учитывают потерю числа степеней свободы при включении в уравнение регрессии дополнительных переменных. Рассчитываются они из соотношений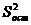 ) +
) +  и SIC = ln(
и SIC = ln( 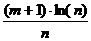 .
.