|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Фиктивные переменные в регрессионной модели 4 страница1. Построить линейную регрессионную модель годовой прибыли предприятия. Оценить параметры модели. 2. Проверить статистическую значимость уравнения регрессии и его коэффициентов на уровне значимости a=0,05. 3. Установить, существенна ли разница в размере годовой прибыли муниципальных и частных предприятий. Решение 1. Для учета формы собственности введем фиктивную бинарную переменную Z1. Предварительно предполагаем, что частные предприятия более эффективны и поэтому имеют при прочих равных условиях в среднем большую годовую прибыль, чем муниципальные. Поэтому фиктивной переменной Z1 присваиваем следующие значения: z1=1 — если предприятие частное и z1=0 — если муниципальное. Эти значения вносим в графу «Форма собственности» таблицы исходных данных вместо слов «частная» и «муниципальная» соответственно. Для выявления коллинеарных факторов с помощью табличного процессора EXCEL была получена матрица парных коэффициентов корреляции между всеми переменными (табл. 3.14).
Анализ коэффициентов корреляции между парами факторов Х1, Х2, Z1 показывает, что ни один из них не превышает по абсолютной величине 0,8. Коллинеарных факторов, таким образом, не выявлено. Результаты регрессионного анализа в EXCEL приведены в табл. 3.15. Уравнение регрессии имеет вид:
2. Коэффициент детерминации R2=0,787 показывает, что 78,7 % вариации годовой прибыли Y объясняется изменчивостью включенных в модель факторов X1, X2 и Z1. Дисперсионный анализ уравнения регрессии показывает, что оно статистически значимо в целом на уровне a=0,05. Статистически значимыми являются коэффициенты при факторах Х2 и Z1. Хотя коэффициент при Х1 и оказался незначимым, его t-статистика превышает по абсолютной величине единицу, поэтому фактор Х1 можно оставить в модели (см. табл. 3.15). 
3. Значимость коэффициента при фиктивной переменной Z1 свидетельствует о том, что разница в прибыли частных и муниципальных предприятий существенна. Положительный знак коэффициента подтверждает наше предположение о том, что частные предприятия имеют в среднем большую годовую прибыль, чем муниципальные — на 150,9 тыс. у.е. Значения коэффициентов уравнения регрессии при факторах Х1 и Х2 показывают, что каждый дополнительный обслуживаемый участок приносит предприятию в среднем 15,58 тыс. у.е. прибыли, а дополнительный рабочий высокой квалификации — в среднем 5,078 тыс. у.е. Заметим, что если не учитывать различий, связанных с формой собственности, то это ухудшит качество регрессионной модели. Так уравнение регрессии без фиктивной переменной
имеет существенно меньший коэффициент детерминации — R2=0,618. Разница между скорректированными коэффициентами детерминации также значительная: 0,716 для модели с фиктивной переменной и 0,542 для модели без нее. Пример 3.5 По торговой фирме исследуется влияние стажа работы в торговле (фактор X1, лет) и уровня образования менеджера по продаже на размер дохода от реализации товаров (зависимая переменная Y, млн. руб.), принесенного фирме за год. Имеются сведения по пятнадцати менеджерам:
Требуется: 1. Построить линейную регрессионную модель дохода менеджера. Оценить параметры модели. 2. Проверить статистическую значимость уравнения регрессии и его коэффициентов на уровне значимости a=0,05. 3. Установить, существенна ли разница в доходе менеджеров с разным уровнем образования. Решение 1. Качественный фактор «Образование» имеет три градации (k=3): высшее, среднее специальное и общее среднее образование. Для содержательной интерпретации коэффициентов уравнения регрессии введем в модель В табл. 3.17 приводятся результаты корреляционного анализа в EXCEL. Анализ значений парных коэффициентов корреляции между факторами Х1, Z11, Z12 свидетельствует об отсутствии коллинеарности. Следовательно, можно попробовать построить модель линейной регрессии со всеми этими факторами.
Результаты регрессионного анализа в EXCEL приведены в табл. 3.18. Уравнение регрессии имеет вид:
2. Коэффициент детерминации R2=0,772 показывает, что 77,2 % вариации годовой прибыли Y объясняется изменчивостью включенных в модель факторов X1, Z11 и Z12. Дисперсионный анализ уравнения регрессии показывает, что оно статистически значимо в целом на уровне a=0,05. Из коэффициентов уравнения регрессии при факторах статистически значимыми являются только коэффициенты при X1 и Z11 (см. табл. 3.18). 3. Значимость коэффициента при Z11 и незначимость коэффициента при Z12 свидетельствует о том, что существенная разница в доходе имеется только для менеджеров с высшим образованием. Более того, t-статистика коэффициента при Z12 меньше по абсолютной величине единицы. Поэтому фиктивную переменную Z12 следует исключить из модели, в результате чего в ней останется только одна фиктивная переменная — Z11 (z11=1 — если менеджер имеет высшее образование, z11=0 — во всех остальных случаях). Повторно проводим регрессионный анализ в EXCEL (табл. 3.19).
Уравнение регрессии второй модели будет иметь вид:
Коэффициент детерминации R2=0,755 показывает, что 75,5 % вариации годовой прибыли Y объясняется изменчивостью включенных в модель факторов X1 и Z11. Скорректированный (нормированный) коэффициент детерминации второй модели выше, чем первой: 0,714 против 0,710, что указывает на обоснованность исключения из модели фиктивной переменной Z12. Дисперсионный анализ второго уравнения регрессии показывает, что оно статистически значимо в целом на уровне a=0,05. Статистически значимы на уровне a=0,05 и коэффициенты уравнения регрессии при факторах X1, Z11 (см. табл. 3.19). Значимость коэффициента при Z11 свидетельствует о том, что имеется существенная разница в годовом доходе, приносимом фирме менеджерами с высшим образованием. В среднем их объем реализации превышает этот показатель для менеджеров со средним образованием на 15,93 млн. руб. Что касается фактора X1, то значение коэффициента при нем показывает, что каждый дополнительный год работы менеджера в торговле способствует росту годового объема реализации в среднем на 6,00 млн. руб.
Пример 3.6 Исследуются различия в средней стоимости квадратного метра общей площади квартиры (переменная Y, у.е.) в зависимости от района города (фиктивная переменная Z1: z1=1 — центральный район, z1=0 — периферийные районы), типа дома (фиктивная переменная Z2: z2=1 — кирпичный дом, z2=0 — панельный дом) и этажа (фиктивная переменная Z3: z3=1 — квартира расположена на средних этажах, z3=0 — квартира расположена на крайних этажах). Имеются данные по двадцати однородным квартирам:
Требуется: 1. Построить линейную регрессионную модель стоимости квадратного метра квартиры. Оценить параметры модели. 2. Проверить статистическую значимость уравнения регрессии и его коэффициентов на уровне значимости a=0,05. 3. Установить, существенна ли разница в стоимости квадратного метра квартиры в зависимости от района города, типа дома и этажа. Решение 1. Матрица парных коэффициентов корреляции между всеми исследуемыми переменными приведена в табл. 3.20. Ее анализ указывает на отсутствие коллинеарных факторов.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 725. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 .
.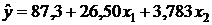
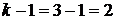 бинарные переменные Z11 и Z12, принимающие значения: z11=1 — если менеджер имеет высшее образование, z11=0 — во всех остальных случаях; z12=1 — если менеджер имеет среднее специальное образование, z12=0 — во всех остальных случаях. Еслименеджер имеет общее среднее образование, то это будет отражено парой значений z11=0 и z12=0 (табл. 3.16).
бинарные переменные Z11 и Z12, принимающие значения: z11=1 — если менеджер имеет высшее образование, z11=0 — во всех остальных случаях; z12=1 — если менеджер имеет среднее специальное образование, z12=0 — во всех остальных случаях. Еслименеджер имеет общее среднее образование, то это будет отражено парой значений z11=0 и z12=0 (табл. 3.16).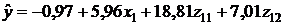 .
.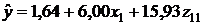 .
.