|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Фиктивные переменные в регрессионной модели 3 страница4) Отсутствие автокорреляции остатков.Выполнение данной предпосылки проверим методом Дарбина–Уотсона. Предварительно ряд остатков на рабочем листе EXCEL упорядочивается в зависимости от последовательно возрастающих значений Y, предсказанных уравнением регрессии. Для этой цели в «Выводе остатка» выделяется любая ячейка в столбце «Предсказанное Y», и на панели инструментов нажимается кнопка «Сортировка по возрастанию». Для расчета d‑статистики используется выражение, составленное из встроенных функций «СУММКВРАЗН» и «СУММКВ»: =СУММКВРАЗН(«Остатки 2, …, n»;«Остатки 1, …, n–1»)/СУММКВ(«Остатки 1, …, n») В результате получим d=2,01. Критические границы d‑статистики для числа наблюдений n=27, числа факторов p=4 и уровня значимости a=0,05 составляют: d1=1,08; d2=1,76. Так как выполняется условие статистическая гипотеза об отсутствии автокорреляции в остатках не отклоняется на уровне значимости a=0,05. Проверим отсутствие автокорреляции в остатках также и по коэффициенту автокорреляции остатков первого порядка, для расчета которого в EXCEL может использоваться следующее выражение: =СУММПРОИЗВ(«Остатки 2,…, n»;«Остатки 1,…, n–1»)/СУММКВ(«Остатки 1, …, n») Ряд остатков упорядочен в той же самой последовательности, что и при расчете d‑статистики. Коэффициент автокорреляции остатков первого порядка равен r(1)=–0,078. Критическое значение коэффициента автокорреляции для числа наблюдений n=27 и уровня значимости a=0,05 составляет r(1)кр=0,381. Так как r(1) не превышает по абсолютной величине критическое значение, то это еще раз указывает на отсутствие автокорреляции в остатках.  5) Нормальный закон распределения остатков. Выполнение этой предпосылки проверяем с помощью R/S-критерия
где emax=558,7 тыс. руб.; emin=–430,3 тыс. руб. — наибольший и наименьший остатки соответственно (определялись с помощью встроенных функций «МАКС» и «МИН»); Se=218,5 тыс. руб. — стандартное отклонение ряда остатков (определено с помощью встроенной функции «СТАНДОТКЛОН»). Критические границы R/S-критерия для числа наблюдений n=27 и уровня значимости a=0,05 имеют значения: (R/S)1=3,34 и (R/S)2=4,71. Так как R/S‑критерий попадает в интервал между критическими границами, то это означает, что статистическая гипотеза о нормальном законе распределения остатков не отклоняется на уровне значимости a=0,05. Таким образом, выполняются четыре из пяти предпосылок обычного метода наименьших квадратов. Это говорит о том, что регрессионная модель не вполне адекватна исследуемому экономическому явлению, и использовать ее для целей анализа и прогнозирования годовой прибыли страховой компании следует с некоторой долей осторожности. 8. Рассчитаем прогнозное значение годовой прибыли, если прогнозные значения факторов составят 75 % от своих максимальных значений в исходных данных. Максимальные значения определяем с помощью встроенной функции EXCEL «МАКС». Прогнозные значения рассчитываем только для количественных факторов X2, X3, X4: · фактор Х2: · фактор Х3: · фактор Х4: Среднее прогнозируемое значение годовой прибыли государственных компаний (x06=0) равно:
Для частных компаний (x06=1) этот показатель равен
9. Построим доверительный интервал прогноза фактического значения годовой прибылиc надежностью 80 %. Стандартная ошибка прогноза фактического значения годовой прибыли y0 для определенных в предыдущем пункте прогнозных значений факторов рассчитывается по формуле
Так как фиктивная переменная Х6 может принимать два значения — 0 или 1, то – для государственных компаний (x06=0):
– для частных компаний (x06=1):
Построим доверительные интервалы прогноза фактического значения результата y0 с доверительной вероятностью g=0,8 (уровень значимости a=0,2):
где tтаб — табличное значение t-критерия Стьюдента при уровне значимости a=0,2 и числе степеней свободы Интервальный прогноз для государственных компаний имеет вид:
Таким образом, с вероятностью 80 % годовая прибыль государственных компаний будет находиться в интервале от 272,4 до 945,4 тыс. руб. Для частных компаний интервальный прогноз:
С вероятностью 80 % годовая прибыль частных компаний будет находиться в интервале от 499,1 до 1173,7 тыс. руб. Пример 3.2 Исследуется зависимость доходности акций компании (зависимая переменная Y, %) от доходности рынка (фактор X1, %). Имеются данные за пятнадцать кварталов:
Требуется: 1. Построить линейную регрессионную модель доходности акций компании, включив в нее в качестве фактора фактор времени. Оценить параметры этой модели. 2. Проверить статистическую значимость уравнения регрессии и его коэффициентов на уровне значимости a=0,05. 3. Проверить временной ряд остатков на наличие автокорреляции. Решение 1. Регрессионная модель строится по временным рядам переменных, которые могут иметь свои тенденции. Для исключения «ложной» корреляции между переменными целесообразно номер квартала (первый столбец таблицы исходных данных) считать независимой переменной t. Проверим факторы X1 и t на коллинеарность, для чего с помощью EXCEL строим матрицу парных коэффициентов корреляции (табл. 3.9).
Коэффициент корреляции между Х1 и t не превышает по абсолютной величине 0,8, что свидетельствует об отсутствии коллинеарности. Поэтому можно попробовать построить двухфакторную модель (табл. 3.10).
Уравнение регрессии имеет вид:
2. Коэффициент детерминации R2=0,478 показывает, что 47,8 % вариации годовой прибыли Y объясняется изменчивостью включенных в модель факторов X1 и t. Дисперсионный анализ уравнения регрессии свидетельствует о его статистической значимости в целом на уровне a=0,05. Статистически значимыми являются и коэффициенты уравнения при факторах Х1 и t (см. табл. 3.10). Значение коэффициента при Х1, показывает, что при увеличении доходности рынка на 1 % доходность акций увеличивается в среднем на 0,495 %. Статистическая значимость коэффициента при факторе времени t свидетельствует о наличии тенденции во временном ряду переменной Y: воздействие всех факторов, кроме доходности рынка, на доходность акций приводит к ее среднему приросту за квартал на 0,528 %. 3. Проверим отсутствие автокорреляции во временном ряду остатков методом Дарбина–Уотсона. В табл. 3.11 приводятся временные ряды предсказанных уравнением регрессии значений результата Y, остатков и стандартизированных (стандартных) остатков (получены в EXCEL при проведении регрессионного анализа). Предварительно проверим остатки на наличие выбросов. Видно, что ни один из стандартных остатков не превышает по абсолютной величинетабличное значение t-критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы остатка регрессии
При расчете d‑статистики остатки остаются упорядоченными по времени. d‑статистика определяется с помощью выражения, приведенного в предыдущем примере. Она оказалась равной d=2,02. Критические значения d‑статистики для числа наблюдений n=15, числа факторов p=2 и уровня значимости a=0,05 составляют: d1=0,95; d2=1,54. Так как выполняется условие статистическая гипотеза об отсутствии автокорреляции в остатках не отклоняется на уровне значимости a=0,05. Автокорреляция возмущений модели, как указывалось в § 3.8, может быть вызвана и неправильным выбором формы регрессионной зависимости. Поэтому d‑статистику целесообразно рассчитать ипо ряду остатков, упорядоченному в зависимости от последовательно возрастающих значений Y, предсказанных уравнением регрессии. В этом случае d‑статистика будет равна d=1,90, и статистическая гипотеза об отсутствии автокорреляции в остатках также не отклоняется. Пример 3.3 Имеется временной ряд прибыли предприятия за девять лет (переменная Y, млн. руб.):
Требуется: 1. Построить трендовую линейную модель прогнозирования прибыли. 2. Проверить статистическую значимость уравнения регрессии и его коэффициентов на уровне значимости a=0,05. 3. Проверить временной ряд остатков на отсутствие выбросов, автокорреляции и соответствие нормальному закону распределения. 4. Оценить точность уравнения регрессии. 5. Спрогнозировать значение прибыли предприятия на 1 год вперед с надежностью 90 %. Решение 1. Независимой переменной в трендовой модели является фактор времени t (здесь — номер года). Уравнение регрессии строим с помощью EXCEL (табл. 3.12). Оно имеет вид:
2. Уравнение регрессии статистически значимо на уровне a=0,05. Это свидетельствует о наличии наличие линейного тренда во временном ряду. Коэффициент детерминации R2=0,884 показывает, что изменение во времени прибыли предприятия на 88,4 % описывается линейной моделью. Статистически значимыми оказались и оба коэффициента уравнения регрессии. Коэффициент при факторе времени показывает, что за один год прибыль предприятия увеличивается в среднем на 4,283 млн. руб. (см. табл. 3.12). 3. При проведении регрессионного анализа в EXCEL были получены предсказанные уравнением регрессии значения Y, остатки и стандартные остатки (табл. 3.15).
Ни один из стандартных остатков не превышает по абсолютной величине табличное значение t-критерия Стьюдента tтаб=2,365 (a=0,05 и d‑статистика Дарбина–Уотсона имеет значение d=2,34. Критические значения d‑статистики для числа наблюдений n=9 и уровня значимости a=0,05 составляют: d1=0,82; d2=1,32. Так как выполняется условие то статистическая гипотеза об отсутствии автокорреляции в остатках не отклоняется на уровне значимости a=0,05. R/S‑критерий определяется по формуле
где emax=6,68 млн. руб.; emin=–5,17 млн. руб. — наибольший и наименьший остатки соответственно; Se=4,24 млн. руб. — стандартное отклонение ряда остатков (определено с помощью встроенной функции «СТАНДОТКЛОН»). Критические границы R/S-критерия для числа наблюдений n=9 и уровня значимости a=0,05 имеют значения: (R/S)1=2,59 и (R/S)2=3,55. Видно, что расчетное R/S-критерий попадает в интервал между критическими границами, и статистическая гипотеза о нормальном законе распределения остатков, таким образом, не отклоняется на уровне значимости a=0,05. 4. Оценим точность модели через стандартную ошибку регрессии Sрег=4,537 млн. руб. (см. табл. 3.12). Средняя относительная ошибка аппроксимации равна
где Точность модели — достаточно высокая: предсказанные уравнением регрессии значения прибыли отличаются от фактических значений в среднем на 6,5 %. 5. Построим точечный и интервальный прогнозы прибыли предприятия на 1 год вперед (период упреждения k=1). Среднее прогнозируемое значение прибыли предприятия в следующем году составляет:
Интервальный прогноз с доверительной вероятностью 0,9 имеет вид:
где tтаб=1,895 — табличное значение t-критерия Стьюдента для a=0,1 и С вероятностью 90 % фактическое значение прибыли предприятия в следующем году будет находиться в интервале от 66,67 (оптимистический прогноз) до 87,93 млн. руб. (пессимистический прогноз). Пример 3.4 По тринадцати предприятиям ЖКХ города исследуется зависимость годовой прибыли (зависимая переменная Y, тыс. у.е.) от числа обслуживаемых участков (фактор X1), количества рабочих высокой квалификации (фактор X2, чел.) и формы собственности:
Требуется: |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 759. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 ,
, ,
, тыс. руб.;
тыс. руб.;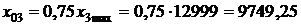 тыс. руб.;
тыс. руб.;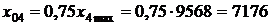 тыс. руб.
тыс. руб.

 .
. определим для обоих случаев:
определим для обоих случаев:

 ,
, составляет tтаб=1,321.
составляет tтаб=1,321. тыс. руб.
тыс. руб. тыс. руб.
тыс. руб. .
. , которое составляет tтаб=2,179.
, которое составляет tтаб=2,179. ,
, .
. ), что свидетельствует об отсутствии аномальных наблюдений (выбросов).
), что свидетельствует об отсутствии аномальных наблюдений (выбросов).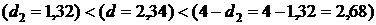 ,
,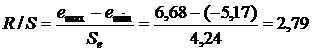 ,
,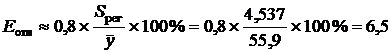 %,
%,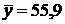 млн. руб. — средний уровень временного ряда переменной Y.
млн. руб. — средний уровень временного ряда переменной Y. млн. руб.
млн. руб.
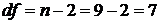 .
.