|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Организация вычислений в компонентах.Модель фон Неймана. Эта модель основана на последовательном выполнении цепочек примитивных вычислений. Модель дискретных событий. События в модели переносят строго упорядоченные штампы времени, показывающие моменты возникновения событий. Симулятор дискретных событий обычно содержит глобальную очередь событий, упорядоченную во времени. Записи очереди обрабатываются в соответствии с этим порядком. Недостаток модели в том, что она полагается на глобальное понятие очереди событий, делающей трудным отображение семантики модели на параллельную реализацию. Такую модель поддерживают языки проектирования аппаратуры VHDL, SystemC и Verilog. Машина с конечным числом состояний (FSM, конечный автомат). Эта модель основана на понятии конечного множества состояний, входов, выходов и переходах между состояниями. Несколько таких машин могут взаимодействовать между собой, образуя взаимодействующие машины с конечным числом состояний (CFSM) . Дифференциальные уравнения. Дифференциальные уравнения способны моделировать аналоговые электрические схемы и физические системы. Поэтому они находят применение для моделирования кибер-физических систем. Модель потока данных. В случае если вычисления предпочтительнее представить не как синхронизированные события, а в виде зависимости реакции одних компонент от реакции других компонент, то такую модель называют моделью потока данных. Комбинированные модели. Реальные языки программирования обычно объединяют определенные модели взаимодействия с организацией вычислений в компонентах. Например, SDL объединяет машины с конечным числом состояний с асинхронной передачей сообщений. Языки ADA и CSP объединяют модель фон Неймана с синхронной передачей сообщений.  Каждая из MoC успешна в той или иной прикладной области. Выбор «лучшей» MoC для конкретного приложения может быть очень трудным. Преодолению дилеммы помогает применение смешанных MoC. Средства для ранней стадии проектирования встроенной системы. Самые первые идеи о системе часто фиксируются неформально на естественном языке с помощью бумаги и карандаша. Это является входом в раннюю стадию проектирования. Такие описания обычно используют крайне неформальный стиль и должны быть зафиксированы в машинно-читаемом документе. Примеры использования (use cases). Для многих приложений целесообразно представлять потенциальные применения проектируемой системы. Такие применения фиксируются как use cases. Use cases описывают возможные применения системы и могут использовать разные способы обозначения. Для поддержки ранних стадий проектирования был разработан стандарт UML (Unified Modeling Language), содержащий стандартизованную форму для use cases [23]. На рис. 65 приведен пример нескольких use cases для устройства Автоответчик.

Рис. 65. Пример use cases
Use cases идентифицируют различные классы пользователей и приложений проектируемой системы. Есть возможность зафиксировать на самом высоком уровне проектирования то, что ожидается от системы. Диаграмма взаимодействия (MSC – Message Sequence Charts). Это чуть более детальный уровень представления, позволяющий подробно задавать последовательность сообщений между компонентами для реализации некоторого применения проектируемой системы. В MSC одно измерение (вертикальное) используется для представления последовательностей, а другое (горизонтальное) отражает взаимодействие компонент. MSC описывает частичный порядок между передачами сообщений и показывает возможное поведение проектируемой системы. MSC стандартизовано в UML. На рис. 66 показана MSC одного из use cases Автоответчика.
2.2 Автомат с конечным числом состояний Начальное представление проектируемой системы на более детальном уровне требует более точной модели, основанной на представлении поведения с помощью состояний. Граф переходов, представляющий автомат с конечным числом состояния (FSM), является классическим способом представления состояний. Будем рассматривать детерминированные FSM, в которых в каждый момент активным является только одно состояние. Узлы графа представляют состояния. Ребра представляют переходы между состояниями. Метки ребер представляют события. Предположим, что некоторое состояние FSM активно, происходит событие, которое соответствует одному из исходящих ребер. FSM изменит свое текущее активное состояние на состояние указанное этим ребром. Если FSM полностью тактируема, то ее называют синхронной. FSM может также генерировать выход.
Рис. 66. Пример MSC Автоответчика для случая вызова
FSM недостаточны для задания встроенных систем, тат как не моделируют время и не поддерживают совместного поведения нескольких FSM. Поэтому были предложены следующие усовершенствования классических автоматов . Расширенный конечный автомат (ЕFSM) – автомат, пополненный переменными, которые могут быть прочитаны и записаны как часть перехода между состояниями. Введение переменных решает проблему быстрого увеличения числа состояний классического автомата для моделирования реальных объектов. Для моделирования времени в ЕFSM ввели действительные переменные, которые моделируют логические часы системы. Переменные времени инициализируются значением 0 при старте системы, а затем синхронно увеличиваются с одной и той же скоростью. Автоматы с такими переменными называют временными автоматами (timed automata ТА). Переменные времени являются элементами охранных условий ребер. Переходы будут выполняться, когда значения часов удовлетворят охранным условиям ребер. Часы могут быть сброшены в 0 во время перехода [24]. На рис. 67 приведен пример модели Автоответчика в виде временного автомата. Автоответчик обычно находится в начальном состоянии «Старт». При поступлении вызова часы Х устанавливаются в 0 и выполняется переход в состояние «Ожидание». Если вызываемый абонент поднимает трубку, то происходит разговор до опускания трубки. В противном случае выполняется переход в состояние «Проигрывание текста», если время достигнет значения 4. По завершению проигрывания текста выполняется переход в состояние «Бип-сигнал». Часы Y обеспечивают однократную генерацию бип-сигнала. После бип-сигнала часы Х сбрасываются снова в 0 и автоответчик готов к записи сообщения. Когда время достигает величины 8 или вызывающий абонент замолчал, генерируется следующий однократный бип-сигнала. После второго бип-сигнала выполняется переход в состояние «Отключено».
Рис. 67. Модель обслуживания входящих вызовов Автоответчиком в виде временного автомата
В этом примере переходы выполняются или под воздействием входов (таких как «Трубка поднята») или так называемых временных ограничений (clock constraints). Временные ограничения описывают переходы, которые могут, но не обязаны быть. Для того чтобы обеспечить реальный переход по этим условиям дополнительно определяются инварианты местоположения (location invariants). Инварианты местоположения X <= 5, X <= 9 и Y <= 2 используются в примере для того чтобы переходы выполнялись не позже чем через время при котором условия инвариант становятся истинными. Формально временной автомат определяется следующим образом [24]. Пусть С есть множество действительных не отрицательных переменных, представляющих часы. Пусть Σ есть конечный алфавит возможных входов. Определение. Временное ограничение есть коньюктивная формула элементарных ограничивающих условий в форме: x ◦ n или (x−y) ◦ n для x, y ∈ C, ◦ ∈ {≤,<,=,>,≥} и n ∈ N. Пусть B(C) есть множество временных ограничений. Определение. Временной автомат есть кортеж (S, s0,E, I), где S– конечное множество состояний. s0 – начальное состояние. E ∈ S×B(C) ×Σ×2^C×S– множество ребер. B(C) представляет конъюнктивное условие, которое должно иметь место и Σ – входы необходимые для перехода. 2^C выражает множество временных переменных, которые сбрасываются во время перехода. I: S→B(C) – множество инвариант для каждого состояния. B(C) представляет инварианту, которая должна иметь место для определенного состояния. Эта инварианта описывается коньюктивной формулой. Временной автомат хоть и расширяет классический автомат, однако в своей стандартной форме не выражает таких свойств как иерархия и одновременность работы. Это учитывают в различных языках проектирования, ориентированных на те или иные модели вычислений.
2.3. Асинхронный язык проектирования SDL В качестве примера рассмотрим язык SDL (Specification and Description Language, стандартизован ITU) основанный на CFSM с асинхронной передачей сообщений. Наряду с текстовым представлением SDL поддерживает и графическое представление проектов. Базовыми элементами SDL являются процессы, представляющие компоненты MoC как EFSM. На рис. 68 показаны графические символы, используемые для представления EFSM. На рис.69 приведено графическое представление в виде процесса (Process P) на SDL временного автомата Автоответчика из примера на рис. 67. Временные переменные (часы) X и Y на SDL представляют два таймера X и Y.
Рис. 68. Символы графической формы SDL
Рис. 69. Модель Автоответчика на SDL Оператор SET (NOW+4, X), например, запускает таймер X на интервал равный 4, а оператор RESET(X) останавливает таймер X. Процессы SDL представляют EFSM, поэтому они могут выполнять преобразования над данными. Переменные могут быть объявлены локально в процессах. Многие типы данных предопределены, так же они могут быть определены пользователем. Синтаксис для объявлений и операций подобен другим языкам. На рис. 70 показаны объявления, оператор присвоения и условный оператор.
Рис. 70. Объявление, присвоение и условный оператор SDL
В общем, описание на SDL состоит из взаимодействующих процессов или EFSM. Процессы могут посылать сигналы другим процессам, образуя CFSM. Семантика взаимодействия процессов основана на асинхронной передаче сообщений и реализована в виде очередей типа FIFO (first-in first-out), ассоциированных с процессами (на каждый процесс своя очередь). Сигналы, посылаемые определенному процессу, поступают в соответствующую очередь как на рис. 71.
Рис. 71. Взаимодействие процессов SDL
Каждый процесс выбирает из очереди запись и проверяет, совпадает ли она с одним из входов назначенных текущему состоянию. Если да, то выполняется соответствующий переход и генерируется выход. Выбранная запись игнорируется, если нет совпадения ни с одним из назначенных входов. Запись при этом может остаться в очереди, если используется механизм запоминания SAVE. Концептуально очереди бесконечны, а значит, не могут переполниться. На практике это не реализуемо и это одна из проблем реализаций проектов на SDL. Язык SDL хорошо подходит для описания распределенных систем. Порядок обработки сигналов одновременно поступающих в очередь не специфицирован, поэтому SDL не является с необходимостью детерминированным. Надежная реализация очереди требует знаний длины ее верхней границы. Вычисление длины может оказаться трудной задачей, а концепция таймера подходит лишь для мягкого реального времени.
2.4. Синхронный язык проектирования Lustre Трудно описывать сложные (смешанные) встроенные системы только в терминах FSM. Диаграммы состояний не могут выражать сложных вычислений. Стандартные языки программирования могут выражать сложные вычисления, но результат последовательного исполнение нескольких потоков может оказаться непредсказуемым. Исполнение множества потоков в среде с приоритетным планировщиком задач приводит к множеству чередований различных вычислений. Трудно понять все возможные нюансы поведения таких одновременных систем. Ключевая причина этого состоит в том, что много допустимых вариантов порядка выполнения программ, т.е. порядок выполнения не специфицирован. Недетерминированное поведение может вызвать негативные последствия, например, проблемы при верификации конкретного проекта. Для распределенных систем с независимой синхронизацией трудно достигнуть детерминированного поведения. Однако для сосредоточенных систем можно попытаться снять излишние проблемы недетерминированной семантики. Это делает синхронный язык. Синхронный язык объединяет конечный автомат и язык программирования в одну модель. Синхронный язык может выражать сложные вычисления, но исполнительной моделью является конечный автомат. Такой язык описывает одновременно действующие автоматы. Детерминированное поведение достигается за счет того, что параллельно работающие автоматы одновременно выполняют переходы между состояниями. Это предполагает наличие единого глобального «тактового сигнала», а не своего «тактового сигналов» для каждого из автоматов. В каждом такте принимаются во внимание все входы, вычисляются выходы и следующие состояния, что требует быстрого широковещательного механизма для всех частей модели. Такой идеалистический взгляд на одновременность гарантирует детерминированное поведение. Это является ограничением, если сравнивать с моделью CFSM, в которой каждая FSM имеет свой собственный «тактовый сигнал». Синхронный язык, по сути, отражает принцип работы синхронных схем. Пусть даны две переменные d и x. Каждый тик в синхронной модели они обновляются следующим образом (d’ и x’ – значения в следующий момент времени):
d’ = -d если x=0 ; d иначе x’ = x + d x: 0 -1 0 1 0 -1 0 1 d: -1 1 1 -1 -1 1 1 1
В 80-х годах прошлого века был предложен синхронный язык Lustre [25] для разработки надежных систем в таких критических областях как аэрокосмическая, ядерная энергетика, поезда без водителей. Lustre базируется на парадигме программирования, которая представляет преобразования в виде модели синхронного потока данных. Эта парадигма полагается на следующие моменты: • Модель встроена в цикл, состоящий из трех фаз: прием множества текущих входных данных, вычисление выходных данных и их выдача. • Входы и выходы, таким образом, являются потоками бесконечных последовательностей значений некоторого типа. • Предполагается, что эти потоки имеют одинаковую длину. Они синхронизируются на временной шкале, основанной на максимальном времени вычисления. • Модель описывается просто списком выходных выражений для второй фазы периодического режима выполнения. Благодаря синхронизации можно однозначно ссылаться на текущие и прошлые значения внутри выражений. Вычисления выходов могут потребовать предыдущих входных значений входов и выходов. В этом случае отношение между входами и выходами не являются функциональными, а зависят от истории сигналов. Если v есть выражение потока, то последовательность обозначается как v1, v2, v3, ... . • 3 означает поток констант 3, 3, 3, ... . • a+b означает поток a1+b1, a2+b2, a3+b3, ... . • Пусть v = expr есть выражение для потока v. Тогда в других выражениях v может быть безопасно заменен на exprвсоответствии с принципом замещения. Выходные потоки задаются своими математическими выражениями. Это подразумевает, что может быть только по одному выражению на поток. Нет понятия присвоения значений в императивном смысле. Несколько выражений для одного и того же потока может все же иметь место в контексте конечного автомата при условии что выполняется только одно активное выражение в каждый момент времени. ESTEREL Technologies разработала коммерческий инструмент SCADE для моделирования, тестирования и верификации синхронных систем использующих Lustre. SCADE де-факто стала европейским стандартом. Она используется в Airbus, Merlin-Gerin, «Сухой», .... SCADE является комплектом программ, работающих под Windows и Linux, и состоит из следующих программных компонент: • GUI интерфейс для графической манипуляции с моделями Lustre; • симулятор; • инструмент для верификации; • генератор исполняемого кода; • инструмент генерации отчетов.
Lustre опирается на 3 базовые концепции. • flow(поток) – последовательность значений данных. Все значения потока принадлежат к одному типу, например, integer flow: 0,1,2,3,.... • node(узел) – базовый кирпич любой программы. Lustre является функциональным языком: каждый узел определяет функцию, которая получает входные потоки и производит выходные потоки, например:
Оператор pre (предыдущее значение): если A = (a1,a2,a3,...,an,...) тогда pre(A) = (nil,a1,a2,a3,...,an-1,...). Оператор -> (инициализация flow): если A = (a1,a2,a3,...,an,...) и B = (b1,b2,b3,...,bn,...), то A->B = (a1,b2,b3,...,bn,...). Функция rising примера обнаруживает моменты изменения символов входного потока Х с 0 на 1 и формирует соответствующий выходной поток Y. Однажды определенный узел становится оператором и может быть вызван в другом узле. На рис. 72 приведено графическое представление rising в SCADE.
Рис. 72. Графическое представление rising в SCADE
• cycle (цикл) – один шаг выполнения программы. В каждом цикле вычисляются новые значения и добавляются в каждый поток. Каждый цикл соответствует тику. Модели систем могут быть смоделированы в SCADE. Симулятор вычисляет значения каждого потока в каждом цикле. Разработчик может ввести значения для входных потоков и наблюдать выходные потоки. На рис. 73 приведены результаты моделирования узла rising.
.
Рис. 73. Временная диаграмма rising
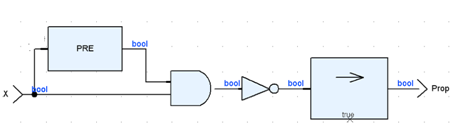
Для модели, которая была отлажена с помощью симулятора, SCADE может выполнить формальную валидацию (верификацию). Для этого необходимо спроектировать поток (называемый монитором), который принимает истинное значение тогда и только тогда, когда интересуемое свойство обнаруживается. Если такой поток всегда принимает истинное значение, то свойство подтверждается. Например, для узла rising мы хотим убедиться, что выходной поток никогда не будет иметь значение true во время двух соседних циклов. На рис. 74 приведен узел Monitor, формирующий потока Prop, для доказательства этого свойства.
Рис. 74. Узел Monitor для верификации rising
Monitor затем подключают к узлу rising (рис. 75) и убеждаются, что выход Monitor всегда принимает значение true.
Рис. 75. Верификации rising
Преобразование линейных систем после дискретизации в программы на Lustre является очевидной задачей. Если система выражена в форме z-преобразований, то оператор 1/z транслируется в 0.0 -> pre(). Пусть например передаточная функция второго порядка имеет вид:
H(z)= (a*z^2 + b*z +c)/( z^2 + d*z +e), y= H(z)*x, у=a*x+(b*x-d*y)*1/z+(c*x-e*y)*1/z^2, отсюда программа:
SCADE может генерировать Си код из модели. Каждый узел транслируется в функцию так, что входные и выходные аргументы функции соответствуют входным и выходным аргументам узла. Сгенерированный код обладает следующими характеристиками: • Как и модель является детерминированным. • Не содержит динамически выделяемой памяти. • Чистое отображение между кодом и моделью. • Последнее позволяет производить трассировку программы при отладке. Рассмотрим простой пример проектирования контроллера «Газовая горелка» (рис. 76) [26]. Контроллер должен сохранять температуру внутри заданного интервала (например, между 50 и 60 градусами включительно). Изначально температура находится в заданном интервале. Контроллер преобразует входной поток Т (значения температуры) в выходной булев поток В.
Рис. 76. «Газовая горелка»
Предлагается следующий алгоритм работы: когда температура достигает 50 °С горелка включается, когда температура достигает 60 °С, горелка выключается. На Lustre это выглядит так:
На рис. 77 представлена модель контроллера газовой горелки в SCADE.
Рис. 77 Модель газовой горелки в SCADE
Для проверки модели контроллера необходимо сформулировать гипотезу об окружающей среде (горелка, датчик температуры, бак): – когда горелка включается, температура повышается; – когда горелка выключается, температура понижается. – горелка переключается мгновенно; – когда нагрева нет температура в баке уменьшается со скоростью 1°С в единицу времени; – когда происходит нагрев температура в баке повышается со скоростью 3°С в единицу времени; – датчик температуры точный. Описание датчика температуры: • вход temp – температура в баке, действительная величина (real); • выход reading – отсчет; • преобразование – temp = reading. Описание горелки: • вход switch – команда контроллера • выход heating – the «пламя», булева величина (Boolean); • преобразование – heating = switch. Описание бака: • вход heated – булева величина, индицирующая нагрев или его отсутствие; • выход temp – температура; • преобразование – temp = 55 -> (if heated then pre(temp)+3 else pre(temp)-1) . Моделирование в SCADE позволяет найти ошибку: для некоторой начальной температуры никогда не достигается температура точно в 60 °С и горелка никогда не выключится. Это связано с ограничениями на частоту дискретизации CPU. Поэтому необходимо вместо ‘if T=60 then false’ перейти к нестрогому неравенству: ‘if T>=57 then false’, где Т – температура, вычисленная в предыдущем цикле.
2.5. Многозадачность. Рассмотренные MoC представляют встроенные системы на самом высоком уровне абстракции. Они используют различные модели представления одновременной работы. Реализацией этих абстракций занимается аппаратное обеспечение MPS, исполняющее последовательный программный код, полученный в результате компиляции проектов написанных на том или ином языке проектирования. Поэтому необходимы механизмы, работающие на среднем уровне, для обеспечения одновременного исполнения последовательного кода. Можно назвать несколько причин необходимости одновременного выполнения нескольких программ. Во-первых, это уменьшение времени реакции путем исключения ситуаций, когда «долгоиграющие» программы могут блокировать программы, реагирующие на внешние воздействия. Улучшение реакции уменьшает задержку – время между получением стимулирующих воздействий и откликом. Во-вторых, увеличивается производительность из-за того, что программе разрешается выполняться одновременно на нескольких процессорах или ядрах. В-третьих, прямое управление синхронизацией внешних взаимодействий. Программе может потребоваться выполнить некоторые действия, такие как обновление информации на дисплее в определенное время, независимо от того что другие задачи могут выполняться в это же время. Существуют различные подходы, позволяющие моделировать одновременную композицию последовательных программ.
2.5.1. Язык программирования Си Программы с языка проектирования автоматически или полуавтоматически транслируются сначала в программы на языке программирования Си, а затем компилируются в объектный код. Этот процесс называют генерацией кода. Часть разработчиков встроенных систем предпочитаюют писать проекты сразу на Си и даже для «голого железа» (без использования операционных систем). Языки программирования, которые выражают вычисления как последовательность операций, называют императивными. Язык Си является таким языком. Рассмотрим модель памяти в Си. Си-программы сохраняют данные в стеке, «куче» (heap) и фиксированных ячейках памяти, назначаемых компилятором. Рассмотрим пример Си-программы:
Переменная ‘a’ является глобальной переменной, т.к. объявлена вне определений функций. Компилятор назначит ее на определенное место в памяти. Переменные ‘b’ и ‘c’ являются параметрами. Им выделяется место в стеке, когда вызывается функция foo (компилятор может также назначить их на регистры). Переменные ‘d’ и ‘e’ локальные переменные. Они объявляются внутри тела функции (в примере в main). Компилятор зарезервирует для них место в стеке. Когда в строке 11 вызывается функция foo, ячейка стека, назначенная для ‘b’, получает копию переменной ‘d’, установленной в строке 8. Это является примером передачи параметров в функцию. Данные передаваемые указателем ‘e’ наоборот запоминаются в памяти, выделенной под кучу и проходят через ссылку (указатель на ‘e’ проходит как величина). Адрес запоминается в ячейке стека для ‘c’. Если foo содержит оператор присвоения для *c, то после возврата из foo это значение может бать прочитано разименованием ‘e’. Рассмотрим некоторые ключевые моменты Си на примере программы на рис. 78. Эта программа реализует часто используемый шаблон, называемый « observer» (наблюдатель). В этом шаблоне функция update изменяет величину переменной ‘х’. Наблюдатели (другие программы или части программы) будут оповещаться (notify) функций обратного вызова (callback) всякий раз, когда изменяется ‘х’. В программе используется связанный список – структура данных для хранения списка элементов, длина которого может изменяться во время выполнения программы. Каждый элемент списка содержит полезную нагрузку (значение элемента) и указатель на следующий элемент в списке (или нуль-указатель, если элемент последний).
Рис. 78. Пример программы-шаблона «observer» на Си
Первая строка декларирует, что notifyProcedure принадлежит к типу Си-функций с аргументом типа int, функция ничего не возвращает. Строки 2 – 5 декларируют struct (структура) – составной тип данных в С. Эта структура состоит из двух элементов: listener типа notifyProcedure* (указатель на функцию) и next – указатель на экземпляр этой же структуры. Строка 7 декларирует, что element_t является типом, относящимся к экземпляру структуры element. Строка 7 декларирует указатель head на список element. head инициализируется значением 0, индицирующим пустой список. Функция addListener создает первый элемент списка, используя следующий код:
В первой строке выделяется память из кучи с использованием стандартной С-функции malloc для сохранения списка element и запоминается в head указатель на element. heap – это структура данных, которая помогает сохранять сведения об областях памяти, используемыми приложениями. В строке 2 запоминается нагрузка, в строке 3 индицируется, что это последний элемент списка. В строке 4 устанавливается значение в tail – указатель на последний элемент списка. Когда список не пуст функция addListener будет использовать tail для добавления элемента к списку. Программа main использует функции, определенные на рис. 78:
Она дважды регистрирует print как callback-функцию, затем выполняет update (устанавливает x = 1), снова регистрирует print и в завершении, снова выполняет update (устанавливает x = 2). Функция print просто выводит на дисплей текущую величину. В процессе работы программы на дисплее появится последовательность 1 1 2 2 2. Си-программа специфицирует последовательность шагов, в которой каждый шаг изменяет состояние памяти в MPS. В Си-программе состояние представляется значениями переменных. В программе на рис. 78 состояние памяти включает значение глобальной переменной ‘x’ и список элементов указываемых переменной head (другая глобальная переменная). Сам список представляется как связанный список, в котором каждый элемент является указателем (адресом) функции, которая вызывается при изменении ‘x’. Во время выполнения Си-программы в состояние памяти включается также стек содержащий локальные переменные. Используя EFSM можно смоделировать выполнение простой С-программы, предполагая, что программа имеет фиксированное и ограниченное число переменных. Переменные Си-программы будут переменными EFSM. Состояния EFSM соответствуют места в программе, а переходы – выполнению программы. На рис. 79 приведена модель функции update из примера на рис. 78. Тип сигнала pure (строгий) означает, что в каждый момент либо сигнал отсутствует (нет события), либо присутствует (есть событие). Такой сигнал не переносит значений, а лишь свидетельствует о присутствии.
Рис. 79. Пример модели Си-программы «шаблон observer»
Автомат переходит из начального состояния Idle, когда вызывается функция update. Вызов сигнализирует о наличии входного аргумента типа int. Когда выполняется этот переход, newx (в стеке) будет присвоено значение аргумента и глобальная переменная ‘x’ получит обновление. После первого перехода EFSM попадает состояние 31 (соответствует оператору element_t* element = head; ). Затем следует безусловный переход в состояние 32 (while(element != 0)) и устанавливается значение element. Из состояния 32 есть два варианта перехода. Если element = 0, то EFSM перейдет и состояние Idle с выходным значением return (возврат из функции), иначе переход в состояние 33. Переход из состояния 33 в 34 сопровождается вызовом функция listener с аргументом равным переменной newx из стека. Переход из 34 обратно в 32 выполняется после получения сигнала returnFromListener, индицирующего возврат из listener. При построении модели подобной рис. 79, необходимо решить на каком уровне детализации остановится, решить какие действия считать атомарными (неделимыми). В приведенном примере строки Си-программы используются в качестве уровня детализации. Но нет гарантии, что строки выполняются как атомарные действия. К тому же точные модели Си-программ часто не являются конечными автоматами. Для кода на рис. 78 модель конечного автомата неприемлема, т.к. она поддерживает регистрацию произвольного числа слушателей. Для функции main из примера модель конечного автомата устраивает, т.к. число регистраций конечно (всего три). Проблема усиливается при добавлении возможностей по одновременному выполнению программ. Поэтому многие разработчики предпочитают работать на верхнем уровне абстракций языков проектирования и не связываться с промежуточными уровнями.
2.5.2. Потоки Потоки (thread или тред) – императивные программы, которые выполняются одновременно и разделяют (совместно используют) адресное пространство. Одновременность выполнения опирается на механизм прерываний, имеющийся во всех микропроцессорах. Большинство ОС обеспечивают высокоуровневый механизм противоположно прерываниям для императивных программ с разделяемой памятью. Механизм выступает в форме коллекции процедур, которые программист может использовать. Такие процедуры обычно соответствуют стандартизованным API (application program interface), которые дают возможность писать переносимые программы (работают на различных процессорах и ОС). Таким API, например, является Pthreads (или POSIX threads), интегрированным во многие современные ОС. Pthreads определяют множество Си-типов, функций и констант. Они стандартизованы IEEE в 1988 для унификации вариантов ОС Unix. В Pthreads поток определяется Си-функцией и создается вызовом функции создания потока. На рис. 80 показана простая многопоточная Си-программа, использующая Pthreads. printN (строки 3 – 9) – функция, которую поток начинает выполнять при старте, называют стартовой подпрограммой. Стартовая

Рис. 80. Простая многопоточная программа на Си, использующая Pthreads
подпрограмма печатает передаваемый аргумент 10 раз и завершается. Функция main создает два потока (строки 14, 15), каждый из которых будет выполнять стартовую подпрограмму. Первый создаваемый поток будет печатать значение 1, а второй – 2 . Когда запускаются эта программы, значения 1 и 2 в некотором чередующемся порядке, зависящим от планировщика задач. Обычно повторное выполнение вызовет отличный чередующийся порядок 1 и 2. Функция pthread_create создает поток и сразу завершается. Стартовая подпрограмма может не начать выполняться перед выходом из pthread_create. Строки 17 и 18 используют функцию pthread_join для того чтобы главная программа main не завершилась перед завершением работы потоков. Без этих строк запущенная программа не сможет произвести требуемые результаты всеми потоками. Во встроенных приложениях широко распространено объявление стартовой подпрограммы как бесконечного цикла, т.е из нее невозможно выйти. Например, стартовая подпрограмма может «вечно» выполняться, периодически выполняя вывод информации на дисплей. Если стартовая подпрограмма не возвращается, тогда некоторый другой поток, который вызывает для нее pthread_join, будет навсегда заблокирован. Как показано на рис.80 стартовая подпрограмма может иметь аргумент и возвращать значение. Четвертый аргумент pthread_create является адресом аргумента, который передается в стартовую подпрограмму. Важно понимать модель памяти Си, иначе возможны очень тонкие ошибки. Предположим, создается поток внутри следующей функции:
Этот код является некорректным, так как аргумент стартовой подпрограммы задается указателем на переменную в стеке. Во время когда поток обращается к оговоренному адресу памяти, функция createThread с вероятностью может завершиться и адрес памяти может быть перезаписан кем-нибудь следующим, попавшим в эту область стека.
2.5.2.1. Реализация потоков Ядром реализации потоков является программа планировщик потоков, решающий какой поток выполнить следующим, когда процессор доступен для выполнения потока. Решение может быть основано на равноправии, когда даются одинаковые возможности всем активным потокам или временных ограничениях или измерении важных характеристик или приоритетах. Первый ключевой вопрос как и когда вызывается планировщик. Кооперативная многозадачность. Это простая техника не прерывает поток пока сам поток не вызовет определенную процедуру. Например, планировщик может вмешиваться всякий раз, как только работающим потоком вызывается из библиотеки некоторый сервис ОС. Каждый поток имеет собственный стек и когда процедура вызывается, адрес возврата проталкивается в стек потока. Если планировщик определяет, что текущий поток должен продолжить работу, запрошенный сервис завершается, и процедура нормально возвращается. Если вместо этого планировщик определяет, что поток должен быть приостановлен и следующий поток должен быть выбран для выполнения, тогда вместо возврата планировщик сохраняет указатель стека текущего потока и изменяет указатель стека на значение, соответствующее новому выбранному потоку. Затем планировщик из стека адрес возврата и запускает новый поток. Главный недостаток кооперативной многозадачности состоит в том, что программа может выполняться очень долго без вызовов сервисов, когда бы могли стартовать другие потоки. Для коррекции этого большинство ОС включает подпрограмму обработки прерываний, которая запускается через фиксированный интервал времени. Это подпрограмма обслуживает системные часы, которые обеспечивают прикладные программы механизмом получения текущего времени дня и разрешают периодический вызов планировщика через прерывание таймера. Для ОС с системными часами период вызова обработчика прерываний системных часов является «мигом» (тик). Для версий Linux этот период варьируется от 1 до 10 ms. Величина тика определяется балансировкой производительности в соотношении с требуемой временной точностью. Маленький тик означает, что функции планировщика выполняются чаще, что уменьшает общую производительность. Большой тик означает, что точность системных часов грубая и что переключение задач происходит реже, а это может вызвать нарушение ограничений реального времени. Иногда тик диктуется приложением. В дополнении к периодическим прерываниям и вызовам сервисов ОС планировщик может быть вызван, когда блокируется поток.
2.5.2.2. Взаимное исключение Поток может быть приостановлен между двумя атомарными операциями для выполнения другого потока и/или обработки прерывания. Это делает максимально трудным рассуждение о взаимодействии между потоками. Рассмотрим функцию addListene из примера 78. Предположим, что она вызывается больше чем в одном потоке. Что может произойти неправильно. Первое, два потока могут одновременно модифицировать список связей структуры данных, что может привести к искажению данных. На рис. 81 приведены результаты моделирования этого асинхронного взаимодействия потоков. Предположим, например, что поток 1 приостановлен перед выполнением оператора tail->listener = listener. Предположим, что пока поток 1 приостановлен другой поток 2 вызывает addListene. Когда поток 1 снова получает управление, он начинает выполняться с оператора tail->listener = listener, но значение указателя tail уже изменено потоком 2. Оно больше не является величиной, вычисленной предыдущим оператором tail = tail->next, до приостановки потока 1. Анализ показывает, что это может закончиться случайным указателем на listener (случайное значение после выделения памяти функцией malloc) в элементе списка i+1. Второй слушатель, добавленный в список потоком 2, будет перезаписан потоком 1 и таким образом будет утрачен. Когда вызывается функция update, она пытается выполнить действия со случайным адресом listener?, что может окончиться ошибкой сегментации или еще хуже, выполнением случайного кода.
Рис. 81. Результат одновременного изменения связанного списка двумя потоками
Подобные проблемы известны под названием состояние гонок (состязания). Две одновременных части кода в предыдущем примере состязались за доступ к одному и тому же ресурсу и порядок, в котором они получали доступ, влиял на результат. Не все состязания являются такими плохими с катастрофическими последствиями как в примере. Один из путей предотвращения этого несчастья состоит в использовании замка для взаимного исключения или мутекса (mutex). В Pthreads мутексы реализуются созданием структуры, называемой pthread mutex. Например можно модифицировать функцию addListener следующим образом:
В первой строке создается и инициализируется глобальная переменная lock. В первой строке функции addListener берет замок. Принцип такой, что только один поток может владеть замком в каждый момент времени. Функция mutex_lock блокирует поток пока вызывающий поток не получит замок. Итак, когда addListener вызывается потоком и начинает выполняться, pthread mutex не возвращает замок, пока им владеет другой поток. Получив замок, вызывающий поток сохраняет его за собой. Функция pthread_mutex_unlock вызывается в конце для освобождения замка. В многопоточном программировании серьезной ошибкой является не освободить замок. Замок взаимного исключения предотвращает одновременный доступ потоков или модификацию потоками разделяемого ресурса. Код между закрыванием и открыванием замка является критической секцией. В каждый момент времени только один поток может выполнять код критической секции. Программист может с необходимостью обеспечить, чтобы всякий доступ к разделяемому ресурсу был защищен аналогичным образом. Функция update из примера на рис.78 не модифицирует список слушателей, она его только читает. Предположим, что поток A вызывает addListener и откладывается после выполнения оператора tail->next = malloc(sizeof(element_t)). Предположим, что пока A отложен другой поток B вызывает update с кодом:
Что случится при выполнении оператора element = tail->next? В этой точке поток B будет работать со случайным содержимым, полученным от malloc при работе потока A, вызывая функцию отсылаемую указателем element->listener. И снова это приведет к ошибке сегментации или того хуже. Мутех, добавленный в предыдущем примере, не устраняет этих ошибок. Он не защищает поток A от перевода в состояние отложен. Таким образом, необходимо защитить все возможные доступы к структуре данных с помощью мутексов. Модифицируем update следующим образом:
Это защитит функцию update от чтения списка, пока не закончится его модификация другим потоком.
2.5.2.3. Взаимная блокировка Большое количество мутексов в программах увеличивает риск взаимной блокировки (deadlock). Взаимоблокировка имеет место, когда некоторые потоки становятся постоянно блокированными пытаясь получить замки. Например, если поток A сохраняет замок 1 и затем блокируется при попытке получить замок 2, которым владеет поток B, затем блокируется B при попытке получить замок 1. От таких «смертельных объятий» не спастись. Программа должна быть прервана. Предположим что функции addListener и update на рис. 73 защищены мутексом, как и двух предыдущих примерах. Update содержит строку (*(element->listener))(newx), которая вызывает функцию, указанную в элементе списка. Разумно для этой функции получить замок мутекса. Предположим, например, что функции слушателя необходимо обновить дисплей. Дисплей типичный разделяемый ресурс и, следовательно, должен быть защищен собственным замком мутекса. Предположим, что поток A вызывает функцию update, которая достигает оператора (*(element->listener))(newx) и затем блокируется, т.к. функция слушателя пытается получить другой замок, которым владеет B. Предположим затем, что поток B вызывает addListener, что приводит к взаимной блокировке. Взаимную блокировку трудно преодолеть. В классической статье [27] даются необходимые условия возникновения взаимной блокировки, некоторые из которых могут быть удалены для преодоления взаимной блокировки. Простая техника состоит в использовании только одного замка для всей многопоточной программы. Эта техника, однако, не приводит к высокомодульной программе. Более того она может затруднить удовлетворению ограничениям реального времени, т.к. некоторые разделяемые ресурсы (например дисплей) могут нуждаться в достаточно длительном удержании, что приведет к просрочке времени исполнения другими потоками. В очень простом микроядре иногда можно использовать разрешение/запрещение прерываний, а так же простой глобальный мутекс. Предположим, что имеется простой процессор (не многоядерным) и прерывания являются механизмом только для приостановки потоков (т.е. потоки не приостанавливаются при вызовах сервисов ядра или блокировке ввода-вывода). С такими предположениями запрещение прерываний предотвращает потоки от приостановки. В большинстве ОС, однако, потоки могут быть приостановлены по многим причинам, следовательно, эта техника не будет работать. Третья техника говорит о том, что когда существует много замков, каждый поток получает замки в одном и том же порядке. Однако по некоторым причинам это трудно гарантировать. Во-первых, большинство программ пишутся многими людьми, получение замков функцией не является частью описания функции. Таким образом, эта техника полагается на очень тщательную и непротиворечивую документацию и перекрестную кооперацию в группе разработчиков. В некоторый момент добавляется замок, затем все части программы, которые получают замок должны быть модифицированы. Во-вторых, может оказаться трудным делом корректное программирование. Если программист захочет вызвать функцию, которая получает замок 1, который согласно принятому соглашению всегда является первым для получения, затем должен первыми освободить некоторые удерживаемые замки. Как только поток освободит эти замки, он может быть приостановлен и ресурс, который замки удерживали, может быть модифицирован. Однажды получив замок 1, он должен вновь приобрести эти замки, но затем будет необходимо предположить, что нет больше каких-либо сведений о состоянии ресурсов, и придется переделать значительное количество работы. Большинство техник налагают строгие ограничения на программиста или требуют определенных изощрений для применения, которые напоминают, что проблема связана с моделью параллельного программирования потоков.
2.5.2.4. Модели непротиворечивости памяти
Тогда как поток B выполняет следующие два оператора:
Интуитивно получаем, что после выполнения потоками этих операций мы должны надеяться, что хотя бы одна из двух переменных w и z имеют значение 1. Такая гарантия относится к последовательной непротиворечивости. Это означает, что результат любого выполнения точно такой же, как если бы операции всех потоков всегда выполнялись в некотором порядке и операции каждого индивидуального потока всегда появлялись в этой последовательности в порядке, определенном в потоке. Однако последовательная непротиворечивость не гарантируется большинством (или возможно всеми) реализаций Pthreads. Обеспечение такой гарантии весьма трудно для современных процессоров, использующих современные компиляторы. Компилятор, например, свободен в вариантах переупорядочивании команд в каждом из потоков, т.к. не существует зависимости между ними (так это может казаться компилятору). Даже если компилятор не переупорядочивает команды, это может сделать аппаратура. Поэтому для доступа к разделяемым переменным остается лишь использовать взаимоисключающие замки и надеяться, что они реализованы корректно. О проблемах непротиворечивости памяти можно посмотреть в [28], [29].
2.5.2.5. Проблемы с потоками Многопоточные программы могут быть очень трудными для понимания. Более того они могут быть трудными для построения конфиденциальности в программах, потому что проблемы кодировки не могут быть обнаружены при тестировании. Программа, например, возможно может содержать взаимоблокировку, но, не смотря на это работать корректно несколько лет без ее проявления. Программист должен быть очень внимательным, но судить о программе адекватно, полагая, что возможны ошибки. В примере на рис. 73 можно устранить потенциальную взаимоблокировку, использую простой трюк, но он приводит к коварным ошибкам (не возникают при тестировании, не извещаются при наличии). Предположим, функция update модифицирована следующим образом:
Эта реализации не удерживает замок, когда вызывается функция listener. Вместо этого программа удерживает замок, когда формирует копию списка слушателей и затем освобождает замок. После возвращения замка программа использует копию списка слушателей для их оповещения. Этот код, однако, имеет потенциально серьезную проблему, которая не может быть обнаружена тестированием. Предположим, что поток A вызывает update с аргументом newx = 0, индицирующим, что «все системы в норме». Предположим, что поток A отложен сразу после освобождения замка, но перед выполнением оповещения. Предположим, что пока он отложен поток B вызывает update с аргументом newx = 1, означающим «авария! двигатель в огне!». Предположим, что этот вызов update завершается перед тем как поток A получает шанс на выполнение. Когда поток A получает разрешение на выполнение, он будет оповещать всех слушателей, но неправильным значением! Если один из слушателей обновляет дисплей пилота самолета, дисплей будет показывать, что все нормально, когда фактически двигатель объят пламенем. Нетривиальные многопоточные программы очень трудно понимать. Они могут содержать коварные ошибки, состязания и взаимоблокировку. Проблемы многопоточных программ могут оставаться незамеченными годы даже при интенсивном использовании программ. Эти проблемы очень важны для встроенных систем т.к. оказывают влияние на безопасность и средства существования. Фактически каждая встроенная система включает параллельное программное обеспечение, потому инженеры, проектирующие встроенные системы должны противостоять всевозможным ловушкам.
2.5.3. Процессы и передача сообщений Процессы есть императивные программы с собственным адресным пространством. Эти программы не могут ссылаться на переменные друг друга и следовательно не имеют проблем потоков. Взаимодействия между программами происходят через механизмы ОС, микроядра или библиотеки. Корректная реализация процессов требует аппаратной поддержки в форме узла управления памятью (MMU). Напомним, что MMU защищает память одной программы от случайного чтения или записи другой программой. Узел MMU также обеспечивает трансляцию адресов, обеспечивая иллюзию фиксированного адресного пространства одного и того же для всех программ. Когда программа выполняет доступ к ячейке в таком адресном пространстве, MMU смещает адрес, отсылая к ячейке физической памяти, выделенной для этой программы. Для достижения одновременности процессы должны уметь взаимодействовать. ОС обычно предоставляют разнообразные механизмы, часто даже включая возможность создания разделяемого адресного пространства, которое конечно открывает программисту все потенциальные трудности многопоточного программирования. Одним из таких механизмов с меньшим числом проблем является файловая система. Файловая система является простым путем создания массива данных, который постоянен в том смысле, что он переживает создавший его процесс. Один процесс может создавать данные и записывать их файл, другой процесс может читать данные из того же файла. Для реализации файловой системы необходимо обеспечить, чтобы процесс читающий данные не делал этого перед их записью. Это может быть сделано, например, разрешением в каждый момент времени только одному процессу взаимодействовать с файлом. Более гибким коммуникационным механизмом между процессами является передача сообщений. В этом случае один процесс создает порцию данных, копирует ее в управляемую секцию разделяемой памяти, а затем извещает другие процессы, что сообщение готово. Эти другие процессы могут быть заблокированы на время пока данные не станут готовыми. Передача сообщений требует некоторое количество разделяемой памяти и реализуется в библиотеках, создаваемыми, конечно же, экспертами. Прикладная программа вызывает библиотечную функцию для отправки или получения сообщения. Пример простой программы передачи сообщений приведен на рис. 82. Эта программа использует шаблон producer/consumer, в которой один поток генерирует последовательность сообщений, а второй поток их потребляет. Такой шаблон может быть использован для реализации рассмотренного ранее шаблона observer без риска взаимной блокировки и без коварных ошибок предыдущих разделов. Функция update всегда выполняться в различных потоках наблюдателей и генерирует сообщения, потребляемые наблюдателями.
Рис.82. Пример простой программы передачи сообщений Функция producer (стартовая функция потока-отправителя) в строке 4 вызывает send (должна быть определена) для отправки сообщения в виде целого значения. Функция consumer обеспечивается тем что, get не возвратится пока она реально не получила сообщение. Заметим, что в этом случае consumer никогда не вернется. Эта программа не завершается собственными средствами. Реализация send и get с использованием Pthreads приведена на рис. 83. Реализация использует связанный список подобный рис. 78, но нагрузка является целой величиной. Связанный список реализован как неограниченная очередь с дисциплиной FIFO (first-in, first-out), когда новый элемент помещается в tail (хвост), а старые элементы удаляются из head (головная часть). Рассмотрим первой реализацию send. Она использует мутекс для того чтобы send и get одновременно не модифицировали связанный список. В дополнении она использует переменную условия для взаимодействия с процессом consumer, который изменяет размер очереди. Переменная условия sent объявляется и инициализируется в строке 7. В строке 23 поток producer вызывает функцию pthread_cond_signal, которая «пробуждает» другой поток, блокированный переменной условия, если такой поток существует.
Рис.83. Функции send и get для передачи сообщений
Чтобы увидеть что означает «пробуждает» другого потока, посмотрим на функцию get. В строке 31, если поток вызывающий get обнаружил, что размер очереди равен 0, тогда он вызывает pthread_cond_wait, который будет блокировать поток до тех пор, пока некоторый другой поток не вызовет pthread_cond_signal. (Существуют другие условия, которые заставят вернуться из pthread_cond_wait, так код должен периодически ждать пока не обнаружит отличный от нуля размер очереди). Критично то, что функции pthread_cond_signal и pthread_cond_wait вызываются, пока владеют замком мутекса. Предположим, что строки 23 и 24 переставлены местами и pthread_cond_signal была вызвана после освобождения замка мутекса. Тогда в этом случае будет возможным вызов pthread_cond_signal пока поток consumer приостановлен (но еще не заблокирован) между строками 30 и 31. В этом случае, когда поток consumer разрешен для работы, будет исполнена строка 31 и наступит блокировка ожидания сигнала. Но сигнал уже был послан и он не может быть послан повторно, так что поток consumer будет постоянно блокироваться. Заметим далее в строке 31, что pthread_cond_wait принимает в качестве аргумента &mutex. Пока поток блокируется на ожидании, он временно освобождает замок мутекса. Если не сделать этого, тогда поток producer не сможет попасть в критическую секцию и, следовательно, не сможет послать сообщение. Программа окажется в состоянии взаимоблокировки. Перед выходом из pthread_cond_wait, функция будет вновь получать замок мутекса. Программист должен быть очень аккуратным, когда вызывает pthread_cond_wait, т.к. замок мутекса временно освобожден во время вызова. Заметим что, значение некоторой разделяемой переменной после вызова pthread_cond_wait может быть отличным от значения до вызова. Условные переменные, использованные в предыдущем примере, есть обобщенная форма семафоров. Программные семафоры получили свое название вслед механическим сигналам, традиционно используемым на железнодорожных путях для сигнализации о том, что на перегоне пути присутствует состав. Использование таких семафоров сделало возможным движение по одной колее в двух направлениях (семафор реализует взаимное исключение, препятствующее одновременному движению двум составом по одному участку пути). В 60-е годы прошлого века Е. Дейкстра заимствовал эту идею, чтобы показать, как программы могут надежно разделять ресурсы. Вычислительный семафор (PV семафор Дейкстра) это неотрицательная целая (натуральная) переменная. Значение 0 рассматривается обособленно. Фактически переменная size из предыдущего примера является семафором. Она увеличивается при отправке сообщений, а величина 0 блокирует consumer, пока значение станет ненулевым. Переменная условия обобщает эту идею, поддерживая произвольные условия, а не только 0 или не 0, как критерий для блокировки. Более тога, по крайней мере, в Pthreads переменные условия координируются с мутексами для облегчения написания программ. Использование передачи сообщений в приложениях может быть проще, чем использование потоков разделяемых переменных, но даже и в этом случае существуют опасности. Реализация шаблона producer/consumer фактически имеет четкий дефект. В частности не налагаются ограничения на размер очереди сообщений. В некоторый момент времени поток producer вызывает send, будет выделена памяти для запоминания сообщения, память не будет возвращена, пока сообщение не употребится. Если поток producer генерирует сообщения быстрее, чем consumer потребляет, то программа, в конце концов, исчерпает допустимую память. Это может быть зафиксировано ограничением размера буфера, но какой размер является приемлемым? Выбор маленького буфера может вызвать взаимоблокировку, большого буфера – неэкономно. Эта проблема не имеет тривиального решения. Также существуют и другие ловушки. Программисты могут неаккуратно построить программы передачи сообщений, так что возникнет взаимоблокировка, когда множество потоков будут ждать сообщений друг от друга. Вдобавок программисты могут неаккуратно построить программы передачи сообщений, так что возникнет недетерминированность в смысле того, что результат вычислений зависит от порядка, в котором планировщик потоков обслуживает их. Простейшее решение для прикладных программистов состоит в использовании высокоуровневых абстракций одновременных вычислений (рассмотренные ранее модели вычислений) , конечно же если доступна их надежная реализация.
2.6. Интегрированная среда разработки прикладного программного обеспечения |
||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 396. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |






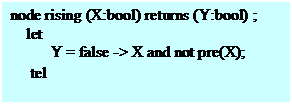







 Для программы на рис. 78 структура данных связанного списка определяется так:
Для программы на рис. 78 структура данных связанного списка определяется так:







 Еще одна весьма тонкая проблема потоков связана с моделью памяти программы. Некоторые отдельные реализации потоков исходят из определенной модели непротиворечивости (консистентности) памяти, определяющей как переменные, которые читаются и записываются разными потоками, кажутся этим потокам. Интуитивно подразумевается, что чтение переменной должно иметь своим результатом последнее, записанное в переменную значение, но что означает «последняя». Рассмотрим, например, сценарий, где все переменные инициализируются значением 0 и поток A выполняет два оператора:
Еще одна весьма тонкая проблема потоков связана с моделью памяти программы. Некоторые отдельные реализации потоков исходят из определенной модели непротиворечивости (консистентности) памяти, определяющей как переменные, которые читаются и записываются разными потоками, кажутся этим потокам. Интуитивно подразумевается, что чтение переменной должно иметь своим результатом последнее, записанное в переменную значение, но что означает «последняя». Рассмотрим, например, сценарий, где все переменные инициализируются значением 0 и поток A выполняет два оператора:

