|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
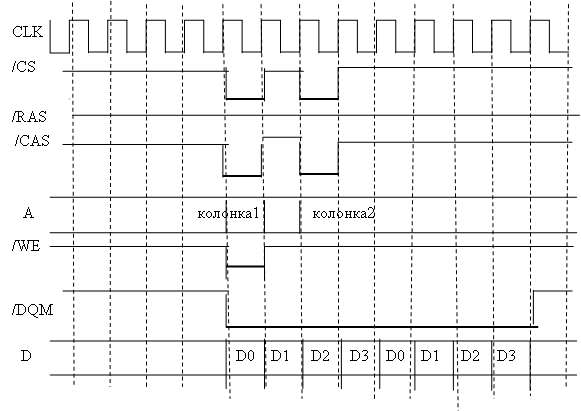
АППАРАТНЫЕ СРЕДСТВА ВСТРОЕННЫХ СИСТЕМ 4 страницаSDRAM поддерживает плотный (back-to-back) страничный режим доступа. Это означает, что страница остается открытой пока доступ вплотную осуществляется к ячейкам в пределах открытой страницы или пока магистраль не начнет выполнять холостые циклы. SDRAM поддерживает конвейеризацию. Это означает, что доступ к следующим данным может происходить минимум через 0 тактов. SDRAM поддерживает расслоение банков. Это означает, что если происходит обращение к другой странице в другом банке, то сначала выдается команда BANK-ACTIVATE для новой страницы, а затем PRECHARGE для старой страницы. Это уменьшает накладные расходы, связанные с де активизацией старой страницы. Существует два варианта перекрытия внутренних банков SDRAM. Первый называют перекрытием страниц. В этом случае адрес ячейки памяти структурируется следующим образом (слева старшая часть адреса): номер строки – номер банка – номер колонки. В случае варианта с перекрытием банков адрес ячейки памяти структурируется следующим образом: номер банка - номер строки – номер колонки. Первый вариант обеспечивает большую производительность. На рис.16 приведена временная диаграмма чтения блока данных (BL=4, CL=3) при промахе страницы. Сначала де активизируется ранее выбранная страница, затем активизируется новая страница. Установка сигналов /CAS и /DQM запускают чтение четырех рядом расположенных слов. SDRAM выполняет блочную передачу для каждой транзакции. При чтении, если требуется данных меньше чем длина блока, то инициатор транзакции игнорирует ненужные прочитанные данные. При записи, если требуется записать меньше данных, чем длина блока, инициатор транзакции подавляет запись лишних данных сбросом линий /DQM. На рис.17 приведена временная диаграмма конвейеризованных транзакций чтения после записи к открытой странице 
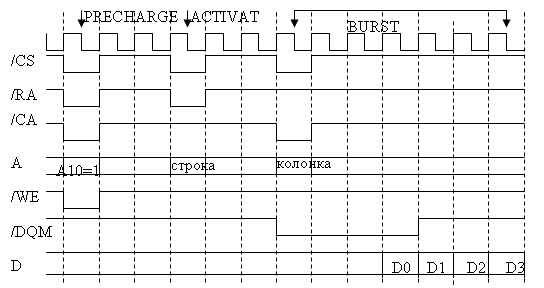
Рис.16. Временная диаграмма чтения блока данных (BL=4, CL=3)
Рис.17. Временная диаграмма конвейеризованных транзакций чтения после записи к открытой странице
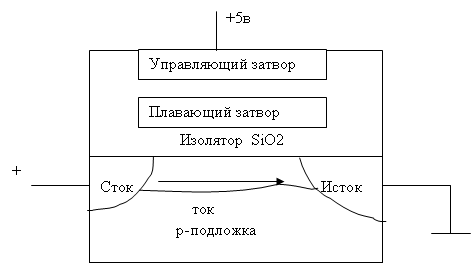
1.5.2. Постоянное запоминающее устройство (ROM) К PROM (Programmable ROM) — программируемое ПЗУ (ППЗУ) обычно относят к OTPROM (One Time Programmable ROM) — «Однократно Программируемое ПЗУ». К PROM также относят и «Масочное ПЗУ» — вариант OTPROM, который программируется не самим пользователем, а на фабрике в процессе изготовления. EPROM (Erasable Programmable ROM) — стираемая/программируемая ROM. По-русски иногда называют ПППЗУ («Перепрограммируемое ПЗУ»). Иногда употребляется как синоним UV-EPROM. EEPROM (Electrically Erasable Programmable ROM) — электрически стираемое перепрограммируемое ПЗУ, ЭСППЗУ. На рис.18 представлено устройство элементарной ячейки, лежащей в основе всех современных типов флэш-памяти. Если исключить из нее «плавающий затвор», мы получим самый обычный полевой транзистор — такой же, как тот, что входит в ячейку DRAM. Если подать на управляющий затвор такого транзистора положительное напряжение, он откроется, и через него потечет ток (состояние «логическая единица»).
Рис.18. МОП транзистор с плавающим затвором
На рис.18 изображен именно такой случай, когда плавающий затвор не оказывает никакого влияния на работу ячейки, — такое состояние характерно для «чистой» флэш-памяти, в которую еще ни разу ничего не записывали. Если же разместить на плавающем затворе некоторое количество зарядов — свободных электронов, то они будут экранировать действие управляющего электрода, и такой транзистор вообще перестанет проводить ток. Это состояние — «логический ноль”. Поскольку затвор «плавает» в толще изолятора (двуокиси кремния, SiO2), то сообщенные ему однажды заряды в покое никуда деться не могут. И записанная таким образом информация может храниться десятилетиями (производители обычно дают гарантию 10 лет, но на практике это время значительно больше). В первых образцах EPROM (UV-EPROM —стирались ультрафиолетом) слой окисла между плавающим затвором и подложкой был достаточно толстым (50 нанометров), и работало все это довольно грубо. При записи на управляющий затвор подавали достаточно высокое положительное напряжение — до 36–40 В (что для микроэлектронной техники считается просто катастрофическим перенапряжением), а на сток транзистора — небольшое положительное. При этом электроны, которые двигались от истока к стоку, настолько ускорялись полем управляющего электрода, что барьер в виде изолятора между подложкой и плавающим затвором просто «перепрыгивали». Такой процесс называется еще инжекцией горячих электронов. Ток заряда при этом достигал миллиампера — можете себе представить, каково было потребление всей схемы, если в ней одновременно заряжать хотя бы несколько тысяч ячеек. И хотя такой ток требовался на достаточно короткое время (хотя с точки зрения быстродействия схемы не такое уж и короткое — миллисекунды), это было крупнейшим недостатком всех старых образцов EPROM-памяти. Еще хуже другое — и изолятор, и сам плавающий затвор долго не выдерживали, постепенно деградируя, отчего количество циклов записи/стирания было ограничено несколькими сотнями, максимум — тысячами. Во многих образцах флэш-памяти (даже более поздних) была предусмотрена специальная схема для хранения карты «битых» ячеек — в точности так, как это делается в жестких дисках. В современных моделях такая карта, кстати, тоже имеется — однако число циклов стирания/записи возросло до сотен тысяч и даже миллионов. Рассмотрим, как осуществлялось в этой схеме стирание. В упомянутой UV-EPROM при облучении ультрафиолетом фотоны высокой энергии сообщали электронам на плавающем затворе достаточный импульс, чтобы они «прыгали» обратно на подложку самостоятельно, без каких-либо электрических воздействий. В электрически стираемой памяти (EEPROM) использован «квантовый эффект туннелирования Фаулера-Нордхейма». При достаточно тонкой пленке изолятора (10 нм) электроны, если их слегка «подтолкнуть» не слишком высоким напряжением в нужном направлении, могут «просачиваться» через барьер, не перепрыгивая его. Старые образцы EEPROM именно так и работали: запись производилась горячей инжекцией, а стирание — квантовым туннелированием. Оттого они были довольно сложны в эксплуатации. Первые микросхемы EEPROM требовали два, а то и три питающих напряжения, причем подавать их при записи и стирании требовалось в определенной последовательности. Поэтому разработчики предпочитали использовать более дешевую, удобную, скоростную и надежную статическую память (SRAM), пристраивая к ней резервное питание от литиевых батареек, которые были достаточно дешевыми. Компания Dallas Semiconductor выпустила специальный тип NVRAM с батарейкой, встроенной прямо в микросхему. Превращение EEPROM во Flash происходило по трем разным направлениям. Во-первых, усовершенствовалась конструкция самой ячейки. Для начала избавились от «горячей инжекции». Вместо нее при записи стали также использовать квантовое туннелирование, как и при стирании. Если при открытом транзисторе подать на управляющий затвор достаточно высокое (но значительно меньшее, чем при «горячей инжекции») напряжение, часть электронов, двигающихся через открытый транзистор от истока к стоку, «просочится» через изолятор и окажется на плавающем затворе. Потребление тока при записи снизилось на несколько порядков. Изолятор, правда, пришлось сделать еще тоньше, что обусловило довольно большие трудности с внедрением этой технологии в производство. Во-вторых, ячейку сделали несколько сложнее, пристроив к ней второй транзистор (обычный), который разделил вывод стока и считывающую шину всей микросхемы. Благодаря этому (вместе с отказом от горячей инжекции) удалось добиться значительного повышения долговечности — до сотен тысяч, а в настоящее время — до миллионов циклов записи/стирания. Кроме того, схемы формирования высокого напряжения и соответствующие генераторы импульсов записи/стирания перенесли внутрь микросхемы, отчего пользоваться такими типами памяти стало несравненно удобнее — они стали питаться от одного напряжения (5 или 3,3 В). И наконец, в-третьих, изменилась организация доступа к ячейкам на кристалле (NAND и NOR Flash [11, 12].
1.6. Иерархия памяти Многие приложения требуют значительного количества памяти, больше чем содержится на кристалле микроконтроллера, поэтому встроенные системы используют иерархию памяти, объединяющую различные технологии для увеличения общей емкости, а также для оптимизации стоимости, задержки и потребления энергии. Обычно относительно небольшого объема SRAM на кристалле процессора используется вместе с памятью DRAM большого объема вне кристалла процессора. Эта память в дальнейшем может быть объединена с памятью третьего уровня, такой как дисковое запоминающее устройство имеющего очень большую емкость, но без произвольного доступа, что увеличивает время записи и чтения. Прикладной программист может и не знать, что память так фрагментирована. Использование рассмотренной выше схемы виртуальной памяти делает эти разнообразные технологии памяти такими, что на взгляд программиста он имеет дело с непрерывным адресным пространством. Операционная система и/или аппаратные средства обеспечивают механизм трансляции адресов, который преобразует логический адрес в физический адрес доступной технологии памяти. Эта трансляция часто выполняется специализированной частью аппаратуры под названием TLB (translation look-aside buffer или буфер быстрого преобразования), ускоряющей преобразование адресов. Для разработчиков встроенных систем эта техника может создать серьезные проблемы, т.к. трудно предсказать или понять как будет выполняться доступ к большой памяти. Разработчикам встроенных систем обычно необходимо более глубоко понимать системы памяти. чем программистам, создающих программы общего назначения.
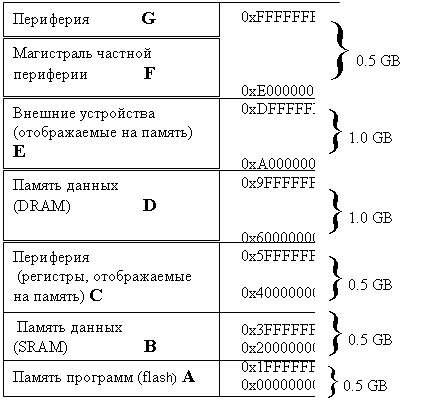
1.6.1. Распределение или карта памяти Карта памяти процессора определяет, как адреса отображаются на аппаратуру. Общий размер адресного пространства ограничивается разрядностью адреса процессора. 32-разрядный процессор, например, может адресовать 2^32 ячеек или 4 Гбайт, полагая, что каждый адрес относится к одному байту. Разрядность адреса обычно совпадает с разрядностью слова (данных) за исключением 8-разрядных процессоров, у которых разрядность адреса обычно выше (16 бит). На рис.19 в качестве примера приведена карта памяти процессора с архитектурой ARM CortexTM - M3.
Рис.19. Карта памяти процессора с архитектурой ARM CortexTM - M3
Эта архитектура Гарвардского типа, поэтому область А может быть доступна по своей магистрали, а области В и D –по своей. Это удваивает полосу пропускания. Некоторые реализации в кристалле этой архитектуры ограничивают ее карту памяти. Например, микроконтроллер Luminary Micro LM3S8962 имеет 256 KB flash памяти вместо допустимой flash памяти 0.5 GB. Эта память отображается на пространство 0x00000000 - 0x0003FFFF. Оставшееся пространство 0x00040000 - 0x1FFFFFFF осталось резервным. Это означает, что целевой компилятор не будет его использовать. LM3S8962 имеет 64 KB SRAM, отображенные на 0x20000000 -0x2000FFFF, маленькую область в B. Он также содержит периферию (устройства), доступную через область C(0x40000000 - 0x5FFFFFFF). К этим устройствам относятся таймеры, ADC, GPIO, UART и другие устройства ввода-вывода. Каждое из устройств занимает небольшое число адресов памяти для реализации регистров, отображаемых на память. Процессор микроконтроллера может записывать данные в некоторые из них для конфигурирования устройств или выдачи данных на их выходы. Некоторые из регистров могут быть прочитаны для ввода данных из периферии. Небольшое количество адресов из области магистраль частной периферии используется для доступа к контроллеру прерываний К LM3S8962 можно подключить дополнительно внешние память DRAM (в область Е) и устройства, такие как LCD дисплей, слот MicroSD и USB интерфейс. При этом остается много неиспользуемого адресного пространства. В архитектуре АРМ введен механизм под названием bit banding (привязка бит), который позволяет через неиспользуемые адреса осуществлять доступ к индивидуальным битам в памяти и периферии.
1.6.2. Блокнотная и кэш память Многие встроенные системы используют в своем составе память различных технологий. Некоторая память может быть доступна перед другой памятью. Говорят, что эта первая память является закрытой процессором. Например, закрытая память (SRAM) обычно используется для сохранения рабочих данных временно, пока процессор оперирует с ними. Если закрытая память имеет отдельное множество адресов и программа отвечает за перемещение данных в них или из них и удаленную память, то такую память называют сверхоперативной или блокнотной (scratchpad). Если закрытая память дублирует данные в удаленной памяти, автоматически копируя их туда и обратно, такую память называют кэш памятью. Для встроенных приложений с ограничениями реального времени кэш памятью представляет значительный препятствие, т.к. ее временное поведение может сильно изменяться и это трудно предсказать. С другой стороны ручное управление данными в блокнотной памяти могут быть трудоемкими для программиста, а автоматические методы управления на уровне компиляторы находятся в начальной стадии развития. Пусть процессор поддерживает виртуальную память и оборудован MMU для трансляции адресов, имеет карту памяти как на рис. 18. и пусть некоторому процессу может быть разрешено использовать логические адреса из области D(1 GB). MMU может реализовать кэш в области В, достаточного объема. Когда программа выдает адрес памяти, MMU определяет находится ли он в области Ви если да,то транслирует адрес и выполняет выборку. Если нет, то фиксируется промах кэш и MMU управляет выборкой данных из вторичной памяти (область D) в кэш (область В). Если ячейки нет и в области D,то MMU фиксирует ошибку страницы, в результате программное обеспечение управляет перемещением данных из диска в память. Так программа создает иллюзию огромной памяти. Расплата за это - трудность в предсказании времени доступа. Итак, кэш-память – это быстродействующая память буферного типа, заполняемая с умеренной скоростью из ОП. Кэш-память по сравнению с другими видами памяти MPS имеет минимальное время доступа и используется для хранения только тех данных, которые могут понадобиться CPU в ближайшее время. В МП находится небольшая кэш-память для команд и небольшая кэш-память для данных (разделенная кэш-память первого уровня). Кэш-память второго уровня расположена вне МП и соединена с ним через высокоскоростную магистраль. Эта кэш-память обычно не является разделенной и содержит смесь данных и команд. Ее размер гораздо больше. Кэш-память третьего уровня – это статическое оперативное запоминающее устройство (ОЗУ) в несколько мегабайтов, работающее гораздо быстрее чем динамическое ОЗУ. Обычно все содержимое кэш-памяти первого уровня находится в кэш-памяти второго уровня, а все содержимое кэш-памяти второго уровня находится в кэш-памяти третьего уровня. Во всех типах кэш-памяти используется следующая модель. MM разделяется на блоки фиксированного размера, которые называются строками кэш-памяти. Строка кэш-памяти состоит из нескольких последовательных байтов (обычно от 4 до 64). В любой момент несколько строк находятся в кэш-памяти. Когда происходит обращение к кэш-памяти, контроллер кэш-памяти проверяет, есть ли нужное слово в данный момент кэш-памяти. Если есть (попадание), то можно сэкономить время, требуемое на доступ к ОП. Если данного слова в кэш-памяти нет (промах), то какая-либо строка из нее удаляется, а вместо нее помещается нужная строка из MM или из кэш-памяти более низкого уровня.
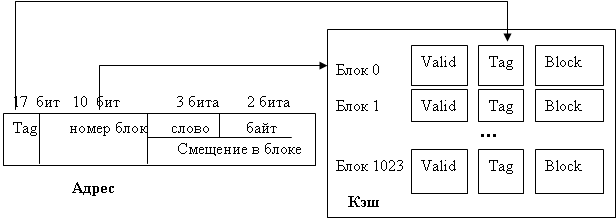
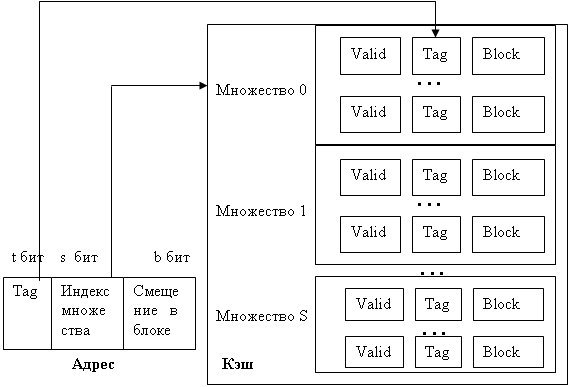
1.6.2.1. Кэш-память прямого отображения Кэш-память прямого отображения является самым простым типом кэш-памяти. На рис.20 приведен пример одноуровневой кэш памяти, содержащей 1024 блока по 32 байта.
Рис.20. Кэш-память прямого отображения и формат адреса
Каждый элемент кэш-памяти состоит из трех частей: 1) Поле Tag (бирка) содержит старшие 17 разрядов адреса памяти, из которого поступил блок данных (адрес блока). 2) Поле Valid (действительно) содержит сведения о достоверности данных. 3) Поле Block содержит копию блока данных памяти. В кэш-памяти прямого отображения данный блок может храниться только в одном месте по номеру блока. Когда процессор выдает адрес памяти, контроллер кэш-памяти выделяет из этого адреса 10 бит номера блока и использует их для поиска в кэш-памяти одного из 1024 элементов. Если этот элемент действителен, то производится сравнение поля Tag адреса и поля Tag кэш-памяти. Если поля равны, то попадание, иначе – промах. В случае попадания слово считывается из кэш-памяти. При промахе или недействительности, блок вызывается из памяти и сохраняется в кэш-памяти, заменяя тот блок, который там был.
1.6.2.2. Ассоциативная по множеству кэш-память В кэш-памяти прямого отображения одноименные блоки MM конкурируют за право занять одну и ту же область в кэш-памяти. Если программе часто требуются ячейки с адресами 0х00000000 и 0х0000800000, то будут иметь место постоянные конфликты и каждое обращение повлечет за собой замещение нулевого блока. Чтобы разрешить эту проблему, нужно сделать так, чтобы одноименные блоки помещались в нескольких местах (множествах) кэш-памяти. На рис.21. приведена ассоциативная по множеству кэш-память. Такая память сложнее предыдущей, поскольку требуется проверить все множества, чтобы узнать, есть ли нужный блок. Память для хранения тэгов адресов реализуется как ассоциативная, что позволяет исключить перебор при поиске места блока. Если нужно поместить новый блок в кэш-память, то какой из старых блоков нужно заместить? Для этого хорошо подходит рассмотренный выше алгоритм LRU. Обобщим параметры кэш памяти: m – разрядность адреса памяти ; M = 2^m – величина адресного пространство в байтах; S = 2^s – число множеств кэш; E – число линий (входов) в множестве; B = 2^b – размер блока в байтах; t = m * s*b – число бит тега; C – общий размер кэш в байтах. Таким образом, кэш может быть охарактеризована четверкой (m,S,E,B), а общий размер кэш составляет C = S*E *B байт.
1.6.2.3. Обновление кэш-памяти. При работе с кэш-памятью одновременно могут существовать две копии одних и тех же данных: одна в кэш, а другая в основной памяти. В MM данные может изменять не только процессор, но и устройства ввода-вывода, работающие по каналу прямого доступа в память. Поэтому необходимо поддерживать их непротиворечивость или когерентность. В MPS c несколькими МП, разделяющих общую MM, также необходимо поддерживать когерентность, но уже и кэш этих МП.
Рис.21. Ассоциативная по множеству кэш и формат адреса
Во всех решениях контроллер кэш-памяти разрабатывается так, чтобы кэш-память могла перехватывать запросы на магистрали, контролируя все запросы магистрали от других процессоров и устройств ввода-вывода, и предпринимать необходимые действия. Эти устройства называются кэш-памятью с отслеживанием (snooping cashe). Набор правил, которые выполняются кэш-памятью, процессорами и MM, чтобы предотвратить появление различных вариантов данных в нескольких блоках кэш-памяти, формирует протокол когерентности кэширования. Единица передачи и хранения кэш-памяти называется строкой или блоком кэш-памяти (32 или 64 байта). Самый простой протокол когерентности кэширования называется сквозной записью (write through). В случае промаха кэш-памяти при записи слова, которое было изменено, оно записывается в MM. Строка, содержащая нужное слово, не загружается в кэш-память. В случае попадания при записи кэш обновляется, а слово плюс ко всему записывается в MM. Всегда при обновлении кэш-памяти одновременно обновляется и основная память. Другой вариант поведения при промахах по записи – загрузка кэш-памяти (политика заполнения по записи – write-allocate). Заполнения по записи эффективно, когда высока вероятность повторного обращения к слову, вызвавшему промах. В устройствах с отслеживанием все кэши отслеживают все запросы магистрали, и всякий раз, когда записывается слово, оно обновляется в кэш-памяти инициатора запроса, обновляется в MM и удалится из всех остальных кэшей.
1.6.2.4. Протокол когерентности кэширования с обратной записью При большом количестве процессоров не эффективно каждый раз перезаписывать ОП. Вместо этого используется обратная запись (write back). Используется бит изменения в поле состояния кэша. Этот бит устанавливается, если блок был обновлен новыми данными и является более поздним, чем его оригинальная копия в основной памяти. Перед тем как перезаписать блок в кэш-памяти, контроллер проверяет состояние этого бита. Если он установлен, то контроллер переписывает данный блок и основную память перед загрузкой новых данных в кэш-память. Один из популярных протоколов с обратной записью MESI. MESI – аббревиатура состояния кэш-памяти: Invalid – блок кэш-памяти содержит недействительные данные. Shared - в нескольких кэшах содержаться одинаковые блоки, основная память обновлена. Exclusive – блок только в этой кэш-памяти, основная память обновлена. Modified - блок действителен, основная память недействительна, копий блока не существует. При загрузке процессора все элементы кэш памяти помечаются как недействительные I. При первом считывании из MM нужная строка вызывается в кэш-память и помечается как Е. Другой процессор (процессор 2) может вызвать ту же строку и поместить ее в кэш, но при отслеживании исходный держатель строки (процессор 1) узнает, что он уже не единственный, и объявляет, что у него есть копия. Обе копии помечаются состоянием S. Процессор 2 производит запись в строку кэш-памяти в состоянии S и помещает сигнал о недействительности на магистраль, сообщая всем другим процессорам, что нужно отбросить свои копии. Соответствующая строка в процессоре 2 переходит в состояние М. Процессор 3 считывает эту строку. Процессор 2, который в данный момент содержит строку, знает, что копия в MM недействительна, поэтому он передает на магистраль сообщение, чтобы процессор 3 подождал, пока он запишет строку обратно в память. После записи строки в MM процессор 3 вызывает из памяти копию этой строки, и в обоих кэшах строка помечается как S. Затем процессор 2 записывает в эту строку снова, что делает недействительным копию в кэш-памяти процессора 3. Процессор 1 записывает слово в эту строку. Процессор 2 видит это и передает на шину сигнал, который сообщает процессору 1, что нужно подождать, пока строка не будет записана в MM. После завершения этого действия процессор помечает собственную копию как недействительную, поскольку он знает, что другой процессор собирается изменить ее. Возникает ситуация, в которой процессор 1 записывает что-либо в некэшируемую строку. Если применяется политика write-allocate, строка будет загружена в кэш-память и пометится как М. В противном случае строка в кэш-памяти сохранена не будет.
1.6.2.5. Команды поддержки когерентности памяти Устройства ввода-вывода MPS, работающее по каналу прямого доступа к MM не содержат кэш-памяти, а следовательно и рассмотренных выше механизмов поддержки когерентности памяти. Вся ответственность ложится на CPU и реализуется программным путем. Для этой цели в системе команд процессора предусмотрены команды flush и invalidate. Пусть программа процессора формирует данные для отправки через устройство ввода-вывода, помещая их в кэшируемую область MM в виде буфера выходных данных (кэш-память работает в режиме обратной записи). Это означает, что новые данные будут сформированы в кэши, а не в MM. Устройство же ввода-вывода берет данные из MM. Поэтому перед разрешением на передачу, процессор должен переместить подготовленные данные из кэш-памяти в MM, выполнив команду flush. По этой команде данные из кэш-памяти перезаписываются в MM. В команде flush указывается адрес и размер перезаписываемых данных. Пусть устройство ввода-вывода принимает данные и помещает их во входной буфер MM, минуя процессор. В кэш-памяти процессора могут остаться данные входного буфера от предыдущей обработки, помеченные как действительные. По завершении приема устройство ввода-вывода информирует процессор о готовности входного буфера. Для работы с этими новыми данными процессор должен объявить недействительными строки кэш-памяти, содержащие старые значения входного буфера. Поэтому процессор выполняет команду invalidate для соответствующих строк кэш-памяти. Команда invalidate объявляет недействительными строки кэш, содержащие данные старого входного буфера. В команде invalidate указывается адрес и размер недействительных данных.
1.7. Магистраль микропроцессорной системы Каждая микросхема процессора содержит набор выводов, через которые происходит обмен информацией с внешним миром. Эти выводы подразделяются на три типа: адресные, информационные (данные) и управляющие, которые и являются основой трех шинной магистрали микросистемы. Эти выводы называют шиной адреса (AB - Address Bus), шиной данных (DB – Data Bus) и шиной управления (CB – Control Bus). Чтобы, например, выбрать команду, CPU помещает на шину адреса адрес команды. Затем формирует сигналы на одной или нескольких линиях шины управления, чтобы сообщить памяти о выполнении операции чтения. В ответ память помещает на шину данных требуемое слово и посылает сигнал о том, что это сделано. Когда CPU получает данный сигнал, он записывает выставленное слово в регистр команд. Число адресных выводов и число выводов шины данных – два ключевых параметра, определяющих производительность CPU. При наличии m адресных линий можно обратится к 2*m ячейкам памяти. Обычно m=16,20,32,64. CPU, содержащий n линий шины данных, может считывать или записывать n-битное слово за одну операцию. Обычно n=8,16,32,64. Линии шины управления регулируют и синхронизируют поток данных, а также выполняют другие разнообразные функции. Все шины управления содержат линии питания, “земли” и синхронизирующего сигнала. Остальные выводы разнятся от одной шины к другой. Тем не менее, линии шины управления можно разделить на несколько основных групп: 1. Управление шиной. 2. Прерывание. 3. Арбитраж шины. 4. Состояние. 5. Разное.
1.7.1. Циклы обращения к магистрали Обмен данными через магистраль выполняется словами или байтами в виде следующих друг за другом обращений. За один цикл обращения к магистрали между CPU, MM и I/O передается от одного до нескольких байт. Существует несколько типовых циклов обмена. Среди них чтение памяти и запись в память. В случае архитектуры гарвардского типа, когда память программ и данных физически разделены, вводится также цикл чтения памяти программ. Рассмотрим простую магистраль со следующим набором сигналов управления в манере Intel: RD (Read) – строб чтения памяти; WR (Write) – строб записи в память; READY – готовность к обмену. Временные диаграммы передачи данных через магистраль однотипны и имеют вид, представленный на рис. 22. На диаграммах выходные данные памяти истинны в момент окончания строба RD, тогда как формируемые CPU выходные данные в течение действия сигнала WR. В некоторых случаях, например, когда в MPS используются медленно работающие компоненты или некоторые из модулей еще не готовы к обмену по ряду причин, не зависящих от CPU, длительность стробов WR и RD могут оказаться недостаточными для правильного обмена со стороны компонента. Тогда для организации надежного завершения магистральной операции в состав магистрали вводят специальную линию READY. В каждом цикле обращения к магистрали перед окончанием строба RD или WR CPU проверяет линию READY. При подтверждении обмена CPU завершает операцию на магистрали, в противном случае он переходит в состояние ожидания подтверждения, в котором остается до установления сигнала READY (рис.23). |
||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 395. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |