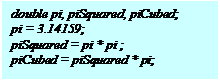|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
АППАРАТНЫЕ СРЕДСТВА ВСТРОЕННЫХ СИСТЕМ 3 страница
1.3. Типы процессоров Микропроцессор (μР) представляет собой процессорный узел, реализованный в виде одной микросхемы. μР чаще всего используются для вычислений общего назначения и применяются в основном в персональных компьютерах, серверах, суперкомпьютерах и высокопроизводительных встроенных системах реального времени. Микроконтроллер (μC) представляет собой объединение на одном кристалле процессорного узла, постоянной памяти для хранения программ (десятки килобайт), оперативной памяти для хранения данных (несколько килобайт) и набора различных устройств ввода-вывода. μC широко применяются в недорогих встроенных системах реального времени. Система на кристалле (SoC) как и μC размещается на одном кристалле и также выполняет функции целого устройства (например, компьютера). Отличие состоит в большей сложности, ориентированности на специализированную задачу и подходом к проектированию - аппаратная часть собирается из стандартных отлаженных блоков (IP-ядер), а для сборки программной части используются готовые драйверы. Выделяют процессоры, основанные на SoC. Они содержат процессорное ядро и большое количество периферийных интерфейсов [3]. Системы на кристалле могут содержать несколько процессорных узлов в общем случае разнородных. Такие устройства называют мультипроцессорными системами на кристалле (MPSoC), например [4]. Цифровой сигнальный процессор (Digital signal processor - DSP) [5] — это специализированный микропроцессор, предназначенный для цифровой обработки сигналов в реальном масштабе времени. Задачи цифровой обработки сигналов имеют несколько общих моментов.  Во-первых, большое число обрабатываемых данных, которые представляют отсчеты физических величин, поступающих с заданным периодом дискретизации (отсчеты радиосигналов, изображения, речи). Во-вторых, обычно выполняются сложные математические операции, включающие фильтрацию, идентификацию, спектральный анализ, машинное обучение и другие. Это интенсивные операции, для поддержки которых и разработаны DSP, например, операция «умножение с накоплением» (MAC) А = A + X × B обычно исполняется за один такт, где А – аккумулятор, Х – входной отсчет, а В – некоторый постоянный коэффициент. Коммуникационные микропроцессоры, например [6], разработаны для интеграции с сетевым и другим коммуникационным оборудованием и состоит из высокопроизводительного процессорного ядра, гибкого контроллера памяти и коммуникационного процессорного модуля (CPM). CPM содержит независимый специализированный RISC процессор (CP). Этот процессор разгружает центральный процессорный узел от задач взаимодействия с периферийным оборудованием. CPM содержит: – последовательные коммуникационные контроллеры (SCC), поддерживающие протоколы Ethernet, ATM, HDLC и другие; – последовательные контроллеры администрирования (SMC); – интерфейсы с временным разделением каналов; – интерфейсы характерные для обычных микропроцессорных систем. Графические процессоры (GPU)[7] –специализированные процессоры, разработанные для выполнения вычислений требуемых для визуализации графики. Они поддерживают 3D графику, построение теней и цифровое видео. Доминируют в этой области Intel, NVIDIA иAMD. Некоторые встроенные приложения, в частности игры, хорошо подходят для GPU. Графические процессорыэволюционируют в сторону общей модели программирования и поэтому начинают примеряться в других приложениях, требующих интенсивных вычислений, таких как измерительная техника. Обычно GPU потребляют много энергии и поэтому не находят применения для встроенных приложений с жесткими требованиями к энергопотреблению.
1.4. Формы параллелизма в процессорах Большинство современных процессоров обеспечивают различные формы параллельной работы. Эти механизмы существенно влияют на время выполнения программ микропроцессорной системой, поэтому разработчики встроенных систем должны понимать их. Понятие конкурентная (одновременная) работа является центральным для встроенных систем. Говорят, что компьютерная программа конкурентная, если ее различные части концептуально могут выполняться совместно. Говорят, что компьютерная программа параллельна, если ее различные части физически выполняются совместно на различном оборудовании (например, многоядерный процессор или группа различных процессоров) Не конкурентные программы задают строгую последовательность выполнения команд. Языки программирования, выражающие такие программы, называют императивными (например, язык Си). Использование Си для написания конкурентных программ требует дополнительных шагов вне языка. Обычно это использование библиотеки потоков (thread), которая обеспечивается операционной системой. В Java, являющимся императивным языком включены конструкции, напрямую поддерживающие потоки. Рассмотрим следующие операторы Си кода:
Последние два оператора являются независимыми и, следовательно, могут выполняться параллельно или в обратном порядке. Это не повлияет на результат. Перепишем эту последовательность следующим образом, и она перестанет быть независимой:
В этом случае последний оператор зависит от предыдущего. Компилятор может анализировать зависимости между операторами и формировать параллельный код, если целевая микропроцессорная система поддерживает параллельную работу. Такой анализ называют анализом потока данных. Сегодня многие микропроцессоры поддерживают параллельное выполнение, используя архитектуру с множественной выдачей потоков команд или VLIW (Very Large Instruction Word, очень длинный формат команды). Процессоры с множественной выдачей потоков команд могут выполнять одновременно независимые команды. Аппаратные средства анализируют команды на лету, и когда зависимость не обнаруживается, выполняют одновременно более чем оду команду. VLIW процессоры имеют команды ассемблерного уровня, которые определяют конкурентные операции. В этом случае от компилятора обычно требуют вставить подходящие команды в программу. В обоих случая (множественна выдача и VLIW) императивная программа анализируется на предмет одновременности для разрешения ее параллельного выполнения. Общее требование состоит в увеличении скорости выполнения программы. Цель - увеличение производительности, когда предположение о завершении задачи раньше всегда лучше завершения позже. Однако в контексте встроенных систем одновременность играет более существенную роль, чем просто улучшение производительности. Программе встроенной системы часто необходимо отслеживать и реагировать на множество одновременных источников и одновременно управлять множеством выходных устройств. Программа встроенной системы почти всегда одновременная программа и одновременность является присущей частью логики программы. Это не только путь улучшения производительности. В действительности завершение задачи раньше не является с необходимостью лучше, чем завершение позже. Суть в своевременности, т.е. действия в физическом мире часто необходимо делать в правильное время - не раньше и не позже. Например, регулятор бензинового двигателя: раннее зажигание не лучше позднего. Оно должно произойти в правильное время. Также как императивные программы могут выполняться последовательно или параллельно, конкурентные программы могут выполняться последовательно или параллельно. Последовательное выполнение конкурентной программы сегодня обычно выполняется многозадачной операционной системой, которая чередует выполнения множества задач в простом последовательном потоке команд. Аппаратура может распараллелить это выполнение, если процессор поддерживает множественную выдачу или VLIW. Таким образом, конкурентная программа преобразуется операционной системой в последовательный поток и обратно в конкурентную программу аппаратным обеспечением для улучшения производительности. Это множественное преобразование сильно затрудняет получение результата в правильное время. Параллелизм в аппаратном обеспечении призван повысить производительность приложений, требующих интенсивных вычислений. С точки зрения программиста одновременность вырастает как следствие разработки аппаратура для увеличения производительности. Другими словами приложение не требует, чтобы множество действий происходило одновременно, требуется лишь, чтобы все происходило очень быстро. Конечно, много интересных приложений объединят обе формы одновременности, возникающие из параллелизма и требований приложения. В этом параграфе рассматриваются такие параллелизмы как конвейерная обработка, параллелизм уровня команд и многоядерные архитектуры.
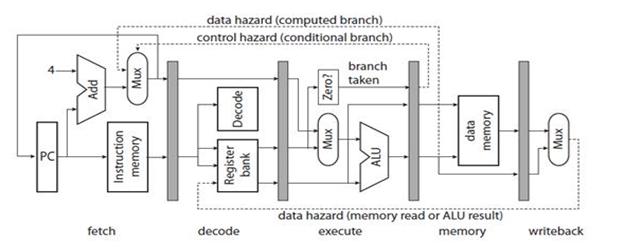
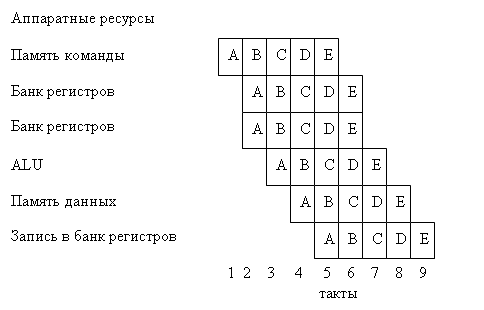
1.4.1. Конвейеризация Большинство современных процессоров являются конвейерными. На рис. 6 [8] приведен простой пятиступенчатый конвейер для 32-разрядного Рис. 6. Простой конвейер процессора, где: fetch – ступень выборки команды; decode – ступень декодирования команды; execute – ступень выполнения команды; memory – ступень чтения или записи в память; writeback – ступень обратной записи; РС – счетчик команд; Add –устройство сложения; Mux – мультиплексор; Instruction memory – память команды; Decode – устройство декодирования; Zero? – устройство определения равенства 0 операнда; Register bank – банк регистров; ALU – арифметико-логическое устройство; Data memory – память данных; data hazard (memory read or ALU result) - риск сбоя данных при чтении памяти или результата ALU; data hazard (computed branch) - риск сбоя данных при безусловном переходе; control hazard (conditional branch) - риск сбоя управления; branch taken –переход по команде ветвления. Затененные прямоугольники на рисунке – регистры-защелки, синхронизированные тактовой частотой процессора. По фронту тактового сигнала данные на их входах запоминаются, а выходы остаются неизменными до прихода следующего фронта, что дает возможность схемам, находящимся между защелками, установить свое значение. На ступени выборки команды РС задает адрес памяти команд, которая содержит кодированные 32-разрядные слова команд. На этой ступени РС увеличивается на 4 (байта), указывая на адрес следующей команды, за исключением команд условного перехода, которые сами обеспечивают установку нового адреса в РС. На ступени декодирования из команды извлекаются адреса регистров, по которым из банка регистров выбираются данные. На ступени выполнения, выбранные из банка регистров или из РС (для команд безусловного перехода) данные преобразуются с помощью ALU. На ступени памяти выполняются операции записи или чтения по адресу, указанному в регистре банка. На ступени обратной записи выполняется запоминание результата в регистровом файле. В случае DSP добавляется одна или две ступени для выполнения умножения и вычисления адресов двух портовой памяти с помощью отдельных ALU. Двух портовая память допускает одновременный доступ к двум операндам. Оборудование конвейера между регистрами-защелками функционирует параллельно. Следовательно, мы видим, что одновременно выполняется пять команд каждая на своей ступени. Это легко визуализировать с помощь таблицы распределения на рис. 7. Слева на рисунке показаны одновременно используемые аппаратные ресурсы. Регистровый банк появляется три раза, т.к. в цикле команды могут быть два чтения и одна запись в банк регистров. Таблица распределения показывает последовательность команд A, B, C, D, E программы. В цикле 5 выбирается Е в то время как D читает из банка регистров, С использует ALU, В читает или записывает в память данных, а А записывает результат в банк регистров. Запись А происходит в цикле 5, а чтение В в цикле 3. Таким образом значение прочитанное В не может быть значением, записываемым А. Это вызывает риск сбоя данных при чтении (на рис.6. отмечено пунктирной линией). Обычно программист предполагает А выполняется перед В и результат А доступен В, что в действительности не так.
Рис.7. Таблица распределения для конвейера на рис. 6
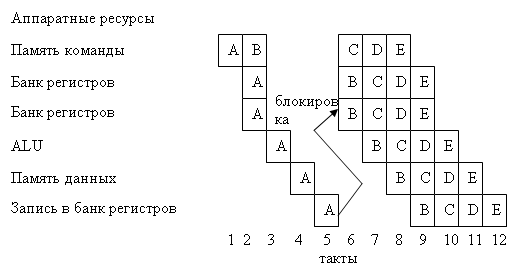
В компьютерных архитектурах проблема рисков сбоя решается различными путями. Простейшее решение известно как явный конвейер, когда риски просто документируются и программист (или компилятор) должен учитывать их. Например, где В читает регистры, записанные А, компилятор должен вставить три пустые команды (ничего не делают) между А и В для обеспечения записи перед чтением. Эти пустые команда образуют «пузыри», распространяющиеся по конвейеру. Более сложное решение основано на взаимоблокировке, когда аппаратура декодирует В и обнаруживает, что В читает регистр записываемый А (риск сбоя), то выполнение В задерживается на три такта пока А не завершит ступень обратной записи. Это иллюстрирует рис. 8. Задержку можно уменьшить до двух тактов, если реализовать чуть более сложную логику продвижения команд в конвейере, которая обнаруживает запись А в туже ячейку из которой читает В, а затем напрямую обеспечивает данными В перед их обратной записью. Это автоматизирует введение «пузырей». Еще более сложной техникой является выполнение с изменением последовательности, когда аппаратура обнаруживает риск сбоя и вместо задержки выполнения В продолжает выборку С и если С не читает регистры записываемые А или В и не записывает регистры читаемые В, тогда продолжается выполнение С перед В. Это уменьшает число «пузырей».
Рис.8. Таблица распределения для конвейера на рис. 6 с взаимоблокировкой, когда В читает регистр, записываемый А.
Другая разновидность рисков сбоя конвейера на рис. 6 – риск сбоя управления выборкой команд. Команда условного перехода изменяет РС, если определенный регистр равен 0. В этом случае, если А является командой условного перехода, она достигает ступени чтения или записи в память перед тем как изменяет РС. Следующие за А команды будут выбраны, декодированы, но в какой то момент времени выясняется что их не нужно было исполнять. Существует несколько способов преодоления рисков сбоя управления выборкой команд. При задержанном переходе просто документируется, что команда перехода занимает столько-то тактов. Программист (или компилятор) должен обеспечить, чтобы команды, следующие за командами перехода, были пустыми или делали полезную работу, не зависящую от ветвления. Взаимоблокировка обеспечивает автоматическое введение «пузырей» как рисках сбоя данных. Наиболее сложный способ преодоления рисков сбоя управления выборкой команд это спекулятивное выполнение команд. Аппаратура предполагает что переход, вероятно, будет иметь место и начинает выполнять предполагаемые команды. Если предположение не оправдалось, приходится удалять побочные результаты (такие как запись в регистры), вызванные спекулятивным выполнением команд. За исключение явной конвейеризации и задержанных переходов все остальные способы вносят вариативность во время выполнения команд. Анализ времени выполнения программы может стать очень трудным в случае длинного конвейера с замысловатым продвижением и спекулятивным выполнением. Явные конвейеры наиболее характерны для DSP, которые часто используются в задачах, где важно точное время. Изменение порядка выполнения и спекулятивное выполнение характерны в процессорах общего назначения, где время имеет значение в общем смысле. Разработчику встроенных систем необходимо понимать требования приложения и не останавливаться на процессорах, для которых неочевидна точность расчета времени выполнения программ.
1.4.2. Параллелизм уровня команд Процессоры, поддерживающие параллелизм уровня команд (ILP) способны выполнять несколько независимых операций в каждом цикле команды. Рассмотрим четыре основных типа ILP: процессоры CISC, параллелизм части слова, суперскалярные процессоры и процессоры VLIW. Процессоры со сложными командами (точнее со специализированными) называют CISC (complex instruction set computer) процессорами в противоположность RISC (reduced instruction set computers) процессорам с сокращенным множеством команд . Процессор DSP типичный CISC процессор, включающий специальные команды поддержки программной реализации фильтров с конечной импульсной характеристикой (FIR фильтров). Такой процессор реализует FIR с производительностью одна команда на ветвление в фильтре. Недостаток такого процессора состоит в экстремальном напряжении сил компилятором для включения таких команд в программу. Поэтому DSP используют библиотеки, написанные и оптимизированные на ассемблере. Параллелизм части слова[9].Многие встроенные приложения оперируют с данными меньшей разрядности, чем слово процессора. Для поддержки таких типов данных некоторые процессоры используют параллелизм на уровне части слова, когда многоразрядное ALU разбивается на минимальные части, допускающие одновременное выполнение арифметических или логических операций над маленькими словами. Векторный процессор один из тех, у кого множество команд включает одновременные операции над элементами множественных данных. Параллелизм уровня команд является формой векторной обработки. Суперскалярные процессоры[10]используют обычное множество команд, но аппаратура может одновременно распределять несколько команд по индивидуальным узлам обработки, когда обнаруживается, что такое распределение не изменяет поведения программы. Такие процессоры поддерживаю изменение последовательности выполнения, когда поздняя команда потока выполняется перед ранней. Недостаток суперскалярной архитектуры с точки зрения встроенных систем состоит в трудности предсказания времени выполнения программы. В контексте многозадачности (прерывания и потоки) это время даже может и не иметь высокой повторяемости. Время выполнения может быть очень чувствительно к точному времени прерываний, так незначительные вариации этого времени могут существенно повлиять на время выполнения программы. Процессоры с архитектурой VLIW [1]часто используются во встроенных системах вместо суперскалярных для получения высокой повторяемости и предсказуемости времени выполнения программ. Так же как суперскалярные процессоры, VLIW процессоры включают несколько функциональных узлов, но вместо динамического определения какие команды могут выполняться одновременно каждая команда определяет то что каждый функциональный узел должен делать в отдельном цикле. Таким образом, VLIW объединяет несколько независимых операций в отдельную команду. Как и в суперскалярных процессорах множество операций выполняется одновременно на различном оборудовании. Однако порядок и одновременность выполнения фиксирована в программе в противоположность принятия решений на лету у суперскалярных процессоров. Это требует от программиста или компилятора обеспечить, чтобы одновременные операции были действительно независимыми. В обмен на эти дополнительные сложности в программировании время выполнения становится предсказуемым. Для приложений требующих еще увеличения производительности VLIW процессоры могут быть усложнены. Многоядерные процессорыявляются комбинацией нескольких CPU на одном кристалле. Разнородные (гетерогенные) многоядерные процессоры объединяют разнотипные CPU в противоположность однородным (гомогенным) процессорам, объединяющим одинаковые CPU. Для встроенных систем многоядерная архитектура несет значительные преимущества, чем одноядерная из-за задач реального времени и задач, критичных по безопасности. По этой причине разнородные многоядерные процессоры используются в мобильных телефонах, т.к. функции по обработке речи и радиосигналов являются функциями жесткого реального времени со значительной вычислительной нагрузкой. В такой архитектуре пользовательские приложения не взаимодействуют с функциями реального времени. 1.5.Технологии памяти Выбор технологии памяти имеет важное последствие для разработчика встроенной системы. Например, программиста беспокоит изменяться или нет данные после выключения питания или вхождения в режим энергосбережения. Память, содержимое которой теряется после пропадания питания, называют энергозависимой памятью (volatile memory). Обычно с ней ассоциируют оперативную память или память с произвольным доступом (RAM). Встроенные системы без исключения нуждаются в сохранении данных даже при выключенном питании. Для этого существует несколько опций. Резервное батарейное питание является одной из них при котором энергия не исчезает. Батареи, однако, срабатываются, следовательно, требуется более совершенная опция в собирательном смысле известная как энергонезависимая память (non-volatile memory). Обычно с ней ассоциируют постоянную память (ROM).
1.5.1. Оперативная память RAM (Random Access Memory) – память, в которой единицы данных (байты или слова) могут быть записаны и считаны относительно быстро. Статическая память SRAM (Static RAM) работает быстрее динамической памяти DRAM (Dynamic RAM), но больше по размеру (каждый бит занимает большую площадь на кристалле).
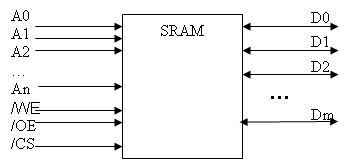
1.5.1. 1. Статическое ОЗУ SRAM конструируется с использованием D-триггеров. В лучшем случае требуется 6 МОП транзисторов на триггер, что препятствует созданию больших массивов ячеек на кристалле (обычно до нескольких миллионов байт). Информация сохраняется на протяжении всего времени, пока на SRAM подано питание. SRAM работает очень быстро. Обычно время доступа составляет несколько наносекунд. Поэтому SRAM часто используют в качестве кэш-памяти второго уровня. На рис.9 приведен интерфейс с SRAM. MPS может содержать несколько микросхем SRAM. Поэтому в интерфейс нужен сигнал для выбора одной из них, такой чтобы только нужная микросхема реагировала на обращение. Сигнал /CS (Chip Select – выбор кристалла) используется для этой цели. “/” означает, что активное значение сигнала равно 0. По сигнал /WE (Write Enable – разрешение записи) выбранная микросхема SRAM записывает данные с линий D0 … Dm в ячейку, двоичный адрес которой установлен на линиях A0 … An.
Рис.9. Интерфейс микросхемы статического ОЗУ
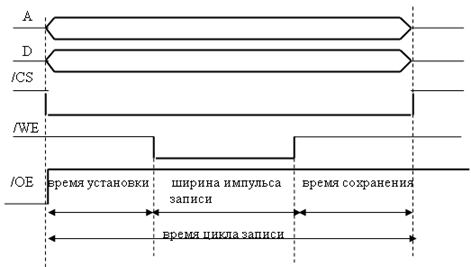
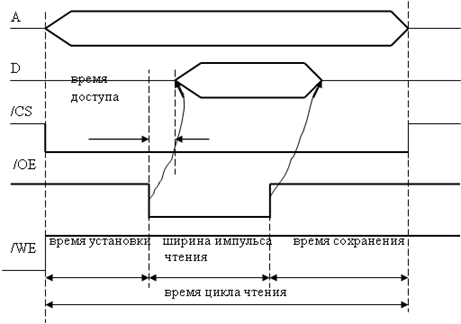
По сигналу /OE (Output Enable – разрешение выдачи данных) выбранная микросхема SRAM выставляет данные на линии D0 … Dm из ячейки, двоичный адрес которой установлен на линиях A0 … An. На рис. 10 приведена временная диаграмма цикла записи SRAM. Время установки (setup time) определяет минимальное время для подачи сигнала /WE после установки линий адреса (время необходимое для дешифрации адреса ячейки). Время сохранения (hold time) определяет минимальное время до очередного изменения адресных линий после снятия сигнала /WE (время необходимое для предотвращения перезаписи данных в другую ячейку). На рис. 11 приведена временная диаграмма цикла чтения статического ОЗУ.
Рис. 10 . Временная диаграмма цикла записи статического ОЗУ
Рис. 11. Временная диаграмма цикла чтения статического ОЗУ
1.5.1. 2. Динамическое ОЗУ В динамическом ОЗУ (DRAM) в качестве запоминающего элемента используется паразитная емкость pn-перехода, которая через МОП транзистор может быть подключена к схемам чтения или записи. На рис.12 приведена модель динамического ОЗУ, организованного в виде матрицы.
Рис.12. Модель динамического ОЗУ
Конденсатор С может быть заряжен или разряжен, что позволяет говорить о хранении 0 или 1. Электрический заряд конденсатора стекает за несколько десятков миллисекунд, поэтому каждый бит информации должен обновляться (регенерировать) для предотвращения разрушения данных. Во время выборки строки все соответствующие транзисторы открываются, и конденсаторы строки разряжаются. Токи разряда поступают на входы запоминающих усилителей считывания, формируя на их выходах соответствующие напряжения 0 или 1. Таким образом, и при обращении к строке данные разрушаются. Поэтому перед выборкой следующей строки, данные должны быть перезаписаны из запоминающих усилителей считывания в ранее выбранную строку. В динамическое ОЗУ на каждый бит требуется один конденсатор и один транзистор, поэтому такое ОЗУ имеет высокую плотность данных. Поэтому MM во многих MPS строится на основе динамического ОЗУ. Однако динамическое ОЗУ работает значительно медленнее. Таким образом, сочетание кэш-памяти на основе статического ОЗУ и MM на основе динамического ОЗУ соединяет в себе преимущества обоих устройств. Существует несколько типов динамических ОЗУ. Самый старый называется FPM (Fast Page Mode – быстрый страничный режим). Под страницей динамического ОЗУ понимают все множество ячеек памяти, принадлежащих одной строке. На смену FPM пришла EDO (Extended Data Output – память с расширенными возможностями выходов данных) с конвейеризацией адресов и данных, что увеличило пропускную способность памяти. Оба эти типа динамических ОЗУ являются асинхронными. На рис.13 приведен интерфейс микросхем асинхронных динамических ОЗУ. Первой выбирается строка. Для этого номер строки помещается на адресные выводы А0…Аn. Затем устанавливается сигнал /RAS (Row Address Strob – строб адреса строки). После этого на адресные выводы подается номер столбца и устанавливается сигнал /CAS (Colum Address Strob). И, наконец, сигналы /OE или /WE.
Рис.13. Интерфейс микросхемы асинхронного динамического ОЗУ
Регенерация всех ячеек строки выполняется установкой ее номера на адресных линиях и сигналов /RAS и /CAS (алгоритм CBR – Cas Befor Ras, т.е. /CAS устанавливается чуть раньше /RAS). В течении нескольких миллисекунд необходимо перебрать все строки и вся память будет регенерирована. На смену асинхронным пришли синхронные динамическим ОЗУ (SDRAM), все действия в которых происходят по фронту или срезу синхронизирующего сигнала CLK. С целью совмещения операций ячейки сгруппированы в несколько банков (обычно 4) – расслоение или чередование (interleaving) памяти. Это дает возможность повысить производительность памяти. На рис.14 приведен интерфейс микросхем SDRAM. Рассмотрим взаимодействие с SDRAM стандарта JDEC. Ниже приведены интерфейсные команды этого стандарта. BANK-ACTIVATE: запоминание адреса строки. Содержимое строки (страница) считывается в запоминающие усилители считывания. Такую страницу называют открытой. MODE-SET: установка параметров SDRAM (передаются через адресныелинии). Скрытый период после сигнала CAS (CAS latency - CL) – задержка выдачи данных после сигнала CAS (1,2,3, … такта). Блочный режим передачи (burst) и длина блока – последовательная передача соседних данных. Длина блока (BL) может быть 1,2,4,8 слов или страница. На рис.15 приведен формат слова параметров. Слово параметров SDRAM устанавливается на линиях адреса и сопровождается установкой сигналов /RAS, /CAS и /WE. PRECHARGE (SINGLEBANK/ALLBANKS): перезапись данных из усилителей считывания в соответствующую строку. Эта команда должна выполняться всякий раз после записи или чтения, если адрес строки изменяется при следующем доступе. Выполнение команды PRECHARGE при А10=1 приводит к перезаписи выбранной строки во всех банках.
Рис.14. Интерфейс микросхемы синхронного динамического ОЗУ
Рис.15. Формат слова параметров SDRAM
READ: запоминание адреса колонки и передача данных из выбранных усилителей считывания в выходной буфер. В конце блочной передачи выбранная страница остается открытой. REFRESH: чтение строки во всех банках. Номер строки определяется внутренним регенерационным счетчиком адреса строки. После начала чтения строка автоматически перезаписывается. Все банки перед регенерацией должны быть в состояние PRECHARGE. Регенерация очередной страницы запускается установкой сигналов /RAS и /CAS (алгоритм CBR). WRITE: запоминание адреса колонки и передача данных с линий D в выбранные усилители считывания. Во время каждого последующего тактового импульса при блочной передаче данные запоминаются без дополнительной операции WRITE. В конце блочной передачи выбранная страница остается открытой. |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 406. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |