|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Показатели точности уравнения регрессии и оценок его параметров
Сначала проверим значимость уравнения регрессии в целом. Как известно, для решения этой задачи используют процедуру дисперсионного анализа, основанную на разложении общей суммы квадратов отклонений зависимой переменной (SST) на две составляющие: одна – за счёт регрессионной зависимости (SSM – Sum. Squared model), другая – за счёт остаточного члена (SSR – Sum. Squared resid). SST = SSM + SSR или
Аналогичное разложение имеет место и для степеней свободы: dfT = dfR + dfE , где dfT = n – 1 – общее число степеней свободы; dfM = m – число степеней свободы, соответствующее регрессии (m – число независимых переменных в уравнении регрессии); dfR = n – m – 1 – число степеней свободы, соответствующее остаткам. Разделив суммы квадратов на соответствующее число степеней свободы, получим суммы квадратов на одну степень свободы или средние квадраты, которые являются оценками дисперсии Вернёмся ещё раз к MSR. Этот показатель является одной из характеристик точности уравнения регрессии. По-другому его называют остаточной дисперсией и обозначают S  MSR также используется при вычислении других показателей точности уравнения регрессии. Например, корень квадратный из MSR называется стандартной ошибкой оценки по регрессии – S.E. of regression (Sy,x) и показывает, какую ошибку в среднем мы будем допускать, если значение зависимой переменной будем оценивать по найденному уравнению регрессии на основе известных значений независимых переменных. Имеем Sy,x = Кроме того, этот показатель в неявном виде участвует в определении ещё одного показателя точности уравнения множественной регрессии, а именно – коэффициента множественной детерминации (R-squared или R2). Как известно,
или после преобразований
Отсюда следует, что коэффициент множественной детерминации показывает долю вариации зависимой переменной, обусловленную вариацией включённых в уравнение регрессии независимых переменных, или, иными словами, долю вариации зависимой переменной, обусловленную регрессионной зависимостью. Коэффициент множественной детерминации изменяется от нуля до единицы и равен единице, если SSR = 0, (связь линейная функциональная), и равен нулю, если SST = SSR, (линейная связь отсутствует). Из определения коэффициента множественной детерминации следует, что он будет увеличиваться при добавлении в уравнение регрессии независимых переменных, как бы слабо не были они связаны с независимой переменной. Следуя этой логике, в уравнение регрессии для увеличения точности отражения изучаемой зависимости может быть включено неоправданно много независимых переменных. Точность уравнения при этом может увеличиться незначительно, а размерность модели возрасти так, что её анализ будет затруднён. Кроме того, при этом уменьшается число степеней свободы модели и ухудшается точность оценок. Для преодоления этого недостатка был разработан исправленный (на число степеней свободы) коэффициент (Adjusted R-squared), имеющий вид
или после преобразования
В отличие от Исправленный коэффициент позволяет избежать переоценки независимой переменной при включении её в уравнение регрессии. Если добавление переменной приводит к увеличению Продолжим анализ точности уравнения регрессии. Как уже отмечалось, при проверке значимости уравнения регрессии проверяется гипотеза о том, что все коэффициенты модели регрессии равны нулю. Если нулевая гипотеза отклоняется, то это означает, что не все коэффициенты в модели регрессии равны нулю, и тогда встаёт вопрос о проверке значимости каждого коэффициента регрессии в отдельности. Такая проверка осуществляется на основе t-статистик, вычисляемых из соотношений
где Как известно, Здесь [(XTX)-1]kk – соответствующие диагональные элементы матрицы (XTX)-1 . При компьютерных расчётах вместе с t-статистикой (t-Statistic) для каждой оценки параметров уравнения регрессии вычисляется выборочный уровень значимости или Prob – это вероятность того, что вычисленное значение t-статистики не превосходит критического значения. По его значению и определяется значимость каждой оценки параметров уравнения регрессии.
|
||
|
|
Последнее изменение этой страницы: 2018-06-01; просмотров: 470. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |

 зависимой переменной y или остатков e в условиях разных предпосылок. Одна из этих оценок (MSM = SSM/m) рассчитывается в предположении, что все коэффициенты в модели регрессии равны нулю (Ho:
зависимой переменной y или остатков e в условиях разных предпосылок. Одна из этих оценок (MSM = SSM/m) рассчитывается в предположении, что все коэффициенты в модели регрессии равны нулю (Ho:  =
=  =…=
=…=  =0), а другая (MSR = SSR/(n–m–1)) – в общих условиях. Затем эти оценки сравниваются по F-статистике (F =
=0), а другая (MSR = SSR/(n–m–1)) – в общих условиях. Затем эти оценки сравниваются по F-статистике (F =  ), которая в случае выполнимости предпосылок МНК и верности нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя, равным m и знаменателя – (n – m – 1). Вместе с F-статистикой EViews вычисляет расчётный уровень значимости (Prob(F-statistic)), и если он меньше принятого уровня значимости, то нулевая гипотеза отклоняется, и уравнение регрессии признаётся значимым.
), которая в случае выполнимости предпосылок МНК и верности нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя, равным m и знаменателя – (n – m – 1). Вместе с F-статистикой EViews вычисляет расчётный уровень значимости (Prob(F-statistic)), и если он меньше принятого уровня значимости, то нулевая гипотеза отклоняется, и уравнение регрессии признаётся значимым. . Известно, что MSR является несмещённой оценкой дисперсии
. Известно, что MSR является несмещённой оценкой дисперсии 



 .
. ,
,  будет убывать, если в уравнение регрессии будут добавляться незначимые независимые переменные (с t-статистикой < 1).
будет убывать, если в уравнение регрессии будут добавляться незначимые независимые переменные (с t-статистикой < 1).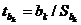 ,
,  – стандартные ошибки соответствующих оценок.
– стандартные ошибки соответствующих оценок. = MSR [(XTX)-1] kk , (k=0,1,…,m). (3.5)
= MSR [(XTX)-1] kk , (k=0,1,…,m). (3.5)