|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Поиск в ширину и кратчайшие пути в графеПоиск в ширину находит расстояния до каждой достижимой вершины в графе от исходной вершины s. Определим длину кратчайшего пути δ(s,v) как минимальное количество ребер на пути от s к v, если пути не существует, то δ(s,v) = ∞. CСледующий алгоритм вычисляет длины кратчайших путей. 1. Пусть G=(V,E) – ориентированный или неориентированный граф, а s – его произвольная вершина, тогда для любого ребра (u,v) графа справедливо δ(s,v) ≤ δ(s,u)+1. 2. Пусть в данном графе процедура поиска (//обхода) в ширину выполняется с исходной вершиной s. Тогда по завершении процедуры для каждой вершины графа v справедливо d[v] ≥ δ(s,v). Где d[v] – метка времени, показывающая, на каком шаге алгоритма обхода в ширину была достигнута вершина v.По сути – расстояние от vдоs. 3. Следствием выполнения процедуры поиска в ширину над графом G=(V,E) является монотонное увеличение параметра d, при каждом следующем шаге алгоритма обхода в ширину. 4. Таким образом, в процессе своей работы алгоритм обхода в ширину открывает все вершины v∈V, достижимые из s, и по окончании работы алгоритма для каждойvi∈Vбудет справедливо d[vi]= δ(s,v). Кроме того, для всех достижимых из s вершин v ≠ s, один из кратчайших путей от s к v – это путь от s к π[v], за которым следует ребро (π[v], v), где π[v]– вершина, из которой мы попали в вершину v, в процессе процедуры поиска в ширину.
Алгоритмы поиска в последовательно организованных файлах. Бинарный и интерполяционный поиск. Поиск в файлах, упорядоченных по вероятности. Самоорганизующиеся файлы. Оценки трудоемкости. Последовательный поиск Задача поиска. Пусть заданы линейные списки: список элементов В=<К1,К2,К3,...,Кn> и список ключей V= (в простейшем случае это целые числа). Требуется для каждого значения Vi из V найти множество всех совпадающих с ним элементов из В. Чаще всего встречается ситуация когда V содержит один элемент, а в В имеется не более одного такого элемента. Эффективность некоторого алгоритма поиска А оценивается максимальным Max{А} и средним Avg{А} количествами сравнений, необходимых для нахождения элемента V в В. Если Pi - относительная частота использования элемента Кi в В, а Si - количество сравнений, необходимое для его поиска, то  n Max{А} = max{ Si, i=1,n } ; Avg{А} = PiSi . i=1 Последовательный поиск предусматривает последовательный просмотр всех элементов списка В в порядке их расположения, пока не найдется элемент равный V. Если достоверно неизвестно, что такой элемент имеется в списке, то необходимо следить за тем, чтобы поиск не вышел за пределы списка. Очевидно, что Max последовательного поиска равен N. Если частота использования каждого элемента списка одинакова, т.е. P=1/N, то Avg последовательного поиска равно N/2. При различной частоте использования элементов Avg можно улучшить, если поместить часто встречаемые элементы в начало списка. Бинарный поиск Бинарный поиск состоит в том, что ключ V сравнивается со средним элементом списка. Если эти значения окажутся равными, то искомый элемент найден, в противном случае поиск продолжается в одной из половин списка. Нахождение элемента бинарным поиском осуществляется очень быстро. Max бинарного поиска равен log2(N), и при одинаковой частоте использования каждого элемента Avg бинарного поиска равен log2(N). Недостаток бинарного поиска заключается в необходимости последовательного хранения списка, что усложняет операции добавления и исключения элементов. Интерполяционный поиск Алгоритм, называемый интерполяционным поиском: Если известно, что К лежит между Kl и Ku, то следующую пробу делаем на расстоянии (u-l)(K-Kl)/(Ku-Kl) от l, предполагая, что ключи являются числами, возрастающими приблизительно в арифметической прогрессии. Интерполяционный поиск работает за log(logN) операций, если данные распределены равномерно. Как правило, он используется лишь на очень больших таблицах, причем делается несколько шагов интерполяционного поиска, а затем на малом подмассиве используется бинарный или последовательный варианты. Самоорганизующиеся файлы Закон Парето или Принцип Парето в наиболее общемвиде формулируется как «20 % усилий дают 80 % результата, а остальные 80 % усилий — лишь 20 % результата». В действительности, удивительно большое количество функций распределения реальных дискретных величин (начиная от количества транзакций на строку таблицы и заканчивая распределением богатства людей или капитализации акционерных обществ) подчиняются закону Парето:
где k — значение величины (в нашем случае — количество обращений к данной записи), р — количество записей, к которым происходит k обращений, с — нормализующий коэффициент (правило "80—20" соответствует = Одним из следствийзакона Парето является концепция «самоорганизующегося файла» — для ускорения поиска в несортированном массиве предлагается передвигать записи ближе к началу массива. Если обращения к массиву распределены в соответствии с законом Зипфа, наиболее востребованные записи концентрируются в начале массива и поиск ускоряется в c/lnN раз, где N — размер массива, а с — константа, зависящая от используемой стратегии перемещения элементов.
Основные понятия защиты информации (субъекты, объекты, доступ, граф.доступов, информационные потоки). Постановка задачи построения защищённой автоматизированной системы (АС). Ценность информации. Информация - сведения о лицах, предметах, фактах, событиях, явлениях и процессах независимо от формы их представления. ЗИ – деятельность, направленная на предотвращение утечки защ-ой И., несанкционированных и непреднамеренных воздействий на защ-ую И. Объект – пассивный компонент системы, хранящий, принимающий или передающий И. (компьютерная или автоматизированная система обработки данных). Субъект – активный компонент системы, кот.м. стать причиной потока И. от объекта к субъекту или изменения состояния системы. Доступ – ознакомление сИ., ее обработка, в частности: копирование, модификация, уничтожение. Потоком информациимежду объектом Оm и объектом Оj наз. произвольная операция над объектом Оj реализуемая в субъекте Si, и зависящая от Оm. Граф доступов –граф, который определяет доступ субъектов к объектам. Две аксиомы защищенных АС. Аксиома 1. В защищенной АС всегда присутствует активный компонент (субъект), выполняющий контроль операций субъектов над объектами. Этот компонент фактически отвечает за реализацию некоторой политики безопасности. Аксиома 2. Для выполнения в защищенной АС операций над объектами необходима дополнительная И. (и наличие содержащего ее объекта) о разрешенных и запрещенных операциях субъектов с объектами. Фундаментальная аксиома для всей теории ИБ. Аксиома 3. Все вопросы БИ в АС описываются доступами субъектов к объектам. ИБ АС - состояние АС, при кот.она, с одной стороны, способна противостоять дестабилизирующему воздействию внешних и внутренних инф. угроз, а с другой - ее наличие и функционирование не создает инф. угроз для элементов самой системы и внешней среды. Постановка задачи построения защищенной автоматизированной системы. Защищенные АС– АС, в кот.обеспечивается безопасность информации. Защищенные АС должны обеспечивать безопасность (конфиденциальность и целостность) обработки И. и поддерживать свою работоспособность в условиях воздействия на систему заданного множества угроз. Соответствовать требованиям и критериям стандартов ИБ. Для того, чтобы построить защищенную систему необходимо: провести комплекс правовых норм, орг. мер, тех., программных и криптографических средств, обеспечивающий защищенность И. в АС в соответствии с принятой политикой безопасности, т.е. создать систему защиты. Ценность информации. Ценность И. определяется степенью ее полезности для владельца. Обладание достоверной И. дает ее владельцу определенные преимущества. Достоверной является И., кот.с достаточной для владельца (пользователя) точностью отражает объекты и процессы окружающего мира в определенных временных и пространственных рамках. И., искаженно представляющая действительность (недостоверная информация), может нанести владельцу значительный материальный и моральный ущерб. Если информация искажена умышленно, то ее называют дезинформацией. Если доступ к И. ограничивается, то такая И. является конфиденциальной. Конф. И. может содержать гос. (сведения, принадлежащие государству (гос. учреждению)) или КТ (сведения, принадлежащие частному лицу, фирме, корпорации и т. п.). В соответствии с законом «О ГТ» сведениям, представляющим ценность для государства, м.б. присвоена одна из трех возможных степеней секретности («секретно», «совершенно секретно» или «особой важности»). В гос. учреждениях менее важной И. может присваиваться гриф «ДСП». Для обозначения ценности конф. комм. И. используются три категории: «КТ - строго конф.»; «КТ- конф.»; «КТ». Используется и другой подход к градации ценности комм. И.: «строго конф. - строгий учет»; «строго конф.»; «конф.». |
||
|
|
Последнее изменение этой страницы: 2018-05-29; просмотров: 417. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
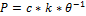 ,
, 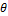 — число в диапазоне от 0 до 1,
— число в диапазоне от 0 до 1,