|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
В СОЦИОЛОГИЧЕСКОМ ИССЛЕДОВАНИИСоциологи изучают поведение (мнения, оценки, мотивы) не отдельно взятых людей, но некоторых человеческих "совокупностей" - социальных групп, классов, сообществ. Информация о массовых социальных явлениях и процессах может быть получена как из объективных, так и из субъективных источников. К объективным источникам относятся официальная государственная статистика, статистика министерств и ведомств, служб социальной защиты, профессиональных союзов, общественных партий и движений и т.п. Такие данные, как правило, касаются обобщенных количественных характеристик социальных общностей, явлений, процессов, например, численность населения, уровень безработицы, средняя зарплата, национальный валовой продукт, численность и состав партий и общественных объединений, реализуемый тираж печатных изданий. Объективное и даже официальное происхождение таких данных не всегда гарантирует их точность и однозначность. Так, существенно расходятся оценки уровня безработицы службами занятости и профсоюзами, которые используют для определения этого уровня разные методики. Средний уровень доходов, определяемый министерством статистики, является заведомо заниженным, так как в нем не учитываются (или учитываются не в полном объеме) заработки в теневом секторе экономики и доходы от индивидуальной трудовой деятельности. Заведомо занижены данные о распространенности наркомании или пьянства за рулем из-за того, что регистрируются далеко не все случаи этих явлений. А данные о читателях библиотек, напротив, завышены, так как библиотека считает своим читателем каждого, кто был в нее записан, даже если человек посетил ее лишь однажды.  Субъективными источниками данных являются сами люди. Только от них можно узнать о настроениях населения или отдельных социальных групп, к ним обращаются службы общественного мнения, по их ответам прогнозируют результаты выборов и определяют рейтинги телепередач. При работе с такими источниками возникают, как минимум, две методологические проблемы. Во-первых, данные, полученные от отдельных людей, должны характеризовать изучаемое явление или процесс в целом. Следовательно, они должны быть некоторым образом обобщены. Во-вторых, наиболее точные результаты могут быть получены при исследовании полной совокупности объектов, имеющих отношение к изучаемой проблеме, — генеральной совокупности. Лучшим примером подобного исследования является перепись населения. Однако подобные проекты чрезвычайно трудоемки и дорогостоящи, а в информации от субъективных источников общество нуждается постоянно. Поэтому социологические исследования в большинстве случаев бывают выборочными. Главной проблемой выборочного исследования является отбор из генеральной совокупности объектов такой подсовокупности (выборки), которая сделала бы исследование одновременно и представительным, и экономичным. Представительностью или репрезентативностью выборки называется ее способность правильно отражать состояние дел в генеральной совокупности, из которой она извлечена и для изучения которой предназначена. Понятие эффективности (экономичности) выборки связано со стоимостью исследования. Эффективной называется выборка, которая позволяет получить наиболее точные результаты при заданной стоимости исследования либо обеспечить заданную точность результатов при минимальных затратах. Репрезентативность и эффективность зависят от дизайна выборки - стратегии и конкретных процедур ее формирования. Дизайн исследования определяется его целями, задачами и гипотезами, а также характеристиками генеральной совокупности. В зависимости от целей и задач различают дескриптивные (описательные), аналитические, полевые исследования и исследования отдельных случаев. Дескриптивные (описательные) исследования, называемые также просто обследованиями, предназначены для получения обобщенных характеристик генеральной совокупности. Они бывают сплошными и выборочными, а также разовыми и лонгитюдными. Основным методом сбора информации является интервьюирование (анкетирование). Сплошное дескриптивное исследование предполагает обследование всей генеральной совокупности, как, например, при переписи населения. Собранная информация может быть использована для классификации объектов, получения обобщенных характеристик генеральной совокупности, измерения связей между показателями. Полное обследование позволяет получить абсолютно надежную информацию, но требует значительных усилий и материальных средств. Выборочное обследование имеет дело не со всей генеральной совокупностью, но только с некоторой ее частью. Для того, чтобы выборка была репрезентативной (позволяла воспроизвести основные характеристики генеральной совокупности), необходимо соблюдать специальные процедуры. Данные выборочного обследования позволяют оценивать неизвестные характеристики генеральной совокупности, проверять гипотезы, анализировать парные и множественные связи между переменными. Выборочное обследование является самым распространенным дизайном в социальных исследованиях, ниже мы рассмотрим его более подробно. Как сплошные, так и выборочные обследования бывают разовыми и лонгитюдными. Разовые исследования позволяют получить "срез" информации о состоянии генеральной совокупности в определенный момент времени. При изучении социальных процессов в динамике возможна организация мониторингового исследования как последовательности разовых обследований, проводимых по общей программе и инструментарию, для каждого из которых строится новая выборка. Обязательное требование к мониторинговым исследованиям - применение на всех этапах одних и тех жепроцедур формирования выборки. Исследование случаев (case study) обычно направлено на интенсивный анализ единичных случаев изучаемого феномена. Исследователь интервьюирует индивидуумов или изучает документы истории их жизни, чтобы глубже понять их поведение; пытается определить как уникальные, так и общие черты, свойственные всем людям из данного класса (социальной группы). Для исследования общих тенденций случаи могут быть сгруппированы по типам. Метод эффективен для исследований личности и процессов социализации, разработки новых понятий либо проверки существующих. Данные об отдельных случаях могут быть закодированы для последующей статистической обработки. Сплошное или выборочное обследование генеральной совокупности может применяться в комбинации с исследованием отдельных случаев для более глубокого освещения происходящих процессов и наблюдаемых феноменов. Случаи отбираются после обследования таким образом, чтобы продемонстрировать поведение объектов с типичными либо, наоборот, резко выделяющимися характеристиками. Таким образом, найденные статистические закономерности иллюстрируются данными об отдельных судьбах, что позволяет изучать и описывать процессы социализации личности с большей глубиной. Остановимся более подробно на методах выборочного обследования - дизайна, наиболее распространенного в социологических исследованиях. Построение репрезентативной (представительной) выборки невозможно без корректного определения генеральной совокупности (ГС), которое далеко не всегда очевидно. Оно включает ответы на следующие вопросы: - какие именно объекты (элементы) составляют ГС - отдельные люди, семьи, академические группы, предприятия, населенные пункты или целые государства; - какими признаками обладают элементы ГС, насколько они доступны для определения; - какова численность ГС; - как ГС размещена территориально; - как ГС ограничена во времени. В большинстве социальных исследований в качестве элементов генеральной совокупности выступают обычные люди. Однако это не является общим правилом. В демографических исследованиях элементом наблюдения часто является домохозяйство или семья; в микроэкономических исследованиях - домохозяйство, фирма, предприятие; в сравнительных международных исследованиях - государство или регион. Ошибки в определении элементов генеральной совокупности приводят к систематическим ошибкам в полученных результатах. По характеру элементов генеральные совокупности (ГС) делятся на конкретные и гипотетические. Конкретные ГС состоят из элементов, которые могут быть выделены относительно легко. Например, учителя составляют достаточно большую, но конкретную ГС, так как их можно найти и обследовать через министерство образования и школы. Элементы гипотетической ГС обладают характеристиками, которые трудно или даже невозможно определить до начала исследования. Например, нельзя определить, принадлежит ли человек к зрителям телевизионного шоу, до тех пор, пока он сам не ответит на этот вопрос, или к генеральной совокупности избирателей - до того, как он пришел на избирательный участок. К гипотетическим генеральным совокупностям относятся аудитория СМИ, сторонники различных учений, потребители некоторых товаров, коллекционеры и т.п. Численность конкретных генеральных совокупностей в большинстве случаев известна или может быть относительно легко уточнена. Численность некоторых гипотетических ГС, например, национальных меньшинств, тоже может быть определена без больших усилий (например, по данным официальной статистики). Довольно часто приходится довольствоваться заведомо завышенными или заниженными оценками, основанными на реальных данных. Например, численность читателей библиотеки можно оценить по картотеке, но такая оценка будет завышенной. Оценка численности безработных по картотеке биржи труда или наркоманов по данным наркологической службы будут заведомо заниженными. Наконец, численность таких генеральных совокупностей, как аудитория СМИ может быть оценена только с помощью специального исследования. Иногда бывает полезно различать конечные и "бесконечные" генеральные совокупности. На практике к бесконечным относят генеральные совокупности численностью более ста тысяч элементов. Так, вполне конкретную ГС учителей Беларуси можно считать практически бесконечной; а весьма гипотетичная ГС узбеков, проживающих в Минске, является конечной, так как ее численность определенно не превышает нескольких десятков человек. В соответствии с территориальным размещением генеральные совокупности бывают национальными, региональными, городскими, и т.п. Они могут также ограничиваться принадлежностью к определенным ведомствам, организациям, сообществам, социальным группам. Временные рамки генеральной совокупности в большинстве случаев ограничиваются моментом обследования. Однако в некоторых исследованиях время играет весьма значительную роль. Так, при изучении демографических или миграционных процессов учитываются все случаи рождений, смертей, эмиграции, иммиграций на определенной территории за год или за пять лет. В лонгитюдных исследованиях время фигурирует как условие выделения генеральной совокупности по принципу образовательной или возрастной когорты. Например, в республиканском лонгитюдном исследовании "Пути поколения" ГС была определена как "лица, получившие среднее образование в 1983 году". Большинство выборочных процедур предполагает, что известны не только общие характеристики, но и списочный состав генеральной совокупности. На практике так бывает далеко не всегда, поэтому следующим этапом построения выборки является определение ее представительной основы - совокупности, из которой выборка будет непосредственно формироваться. При опросах взрослого населения в качестве основы выборки используют картотеку адресного стола, списки избирателей, или списки адресов, которыми располагают коммунальные службы (хотя все эти источники, как правило, не вполне точны); при исследовании читателей прессы -списки подписчиков в почтовых отделениях (хотя газеты читают не только они); при телефонных опросах населения - номера телефонов, включенные в городской справочник (хотя значительная часть населения не охвачена этим видом услуг) и т.п. Поскольку выборка является средством изучения генеральной совокупности, основное требование к ней - возможность обобщения результатов выборочного исследования на генеральную совокупность. Соответствие выборки этому требованию определяет ее репрезентативность. Выбор конкретных методов формирования выборки зависит от характеристик генеральной совокупности, а также имеющихся материальных и временных ресурсов. Существует два основных подхода к обоснованию репрезентативности выборки: статистический и внестатистический. При статистическом подходе репрезентативность обеспечивается специальными вероятностными методами извлечения выборки. Для обобщения результатов исследования на генеральную совокупность применяются строгие индуктивные процедуры статистического вывода, оценивается ошибка выборки с заданной доверительной вероятностью. Внестатистическое обоснование репрезентативности предполагает теоретическое доказательство того, что выборка достаточно хорошо представляет генеральную совокупность. При использовании этого подхода статистическое оценивание ошибок выборки не производится. Поскольку абсолютное большинство методов статистического анализа разработаны для статистически обоснованных (вероятностных) выборок, мы будем говорить, главным образом, о них. Различают три основных вида случайного отбора: простой, стратифицированный и кластерный. Простой случайный отбор из генеральной совокупности предполагает, что (1) генеральная совокупность однородна; (2) все ее элементы доступны для исследования в одинаковой степени; (3) имеется полный список элементов, составляющих генеральную совокупность (или хотя бы репрезентативная основа выборки); (4) к этому списку применяются процедуры случайного отбора, с использованием таблиц или компьютерных генераторов случайных чисел. При правильной организации простого случайного отбора все элементы генеральной совокупности имеют одинаковую вероятность попасть в выборку, что значительно упрощает ее статистическое обоснование. Основными проблемами простого случайного отбора являются сложность и неоднозначность понятия однородности генеральной совокупности; невозможность получения представительной основы выборки; разная степень доступности элементов генеральной совокупности и их готовности участвовать в исследовании. Однородность генеральной совокупности является одним из наиболее сложных для определения понятий. Она означает не столько одинаковое поведение ее элементов, сколько однородность условий, в которых эти элементы находятся. Условия, по которым контролируется однородность ГС, должны быть тесно связанными с задачами и гипотезами исследования. Так, при экологических исследованиях, всю территорию Беларуси делят на две относительно однородные части - загрязненную радиоактивными элементами и "чистую". При исследованиях общественного мнения неодинаково ведут себя городское и сельское население. При предсказании результатов выборов необходимо принимать во внимание различия в политических симпатиях населения западных и восточных районов страны. В некоторых исследованиях критериями неоднородности могут быть возраст, образование, принадлежность к религиозным конфессиям, даже пол респондента. Для получения основы выборки применяются два главных подхода, выбор которых зависит от определения генеральной совокупности. Если она определена по территориальному принципу (как население, проживающее на определенной территории), формирование основы выборки также производится по территориальному принципу - через адресные или справочные столы, по спискам избирателей или подписчиков газет, домовым книгам, спискам адресов, планам населенных пунктов и т.п. Если генеральная совокупность определяется по производственному принципу, основа выборки формируется по спискам работников предприятий, учащихся учебных заведений, списков членов партий или других сообществ, библиотечных картотек, и так далее. Термин "производственный" здесь трактуется широко, как зарегистрированное членство в любой организации. Возможность получения основы выборки зависит от степени конкретности/гипотетичности генеральной совокупности, ее объема, особенностей организации. Наконец, необходимо учитывать, что социальные объекты могут проявлять разную степень готовности участвовать в исследовании (вплоть до полного отказа), а также могут иметь разную степень доступности. Например, менее доступными часто оказываются молодые респонденты, особенно мужчины, ведущие мобильный образ жизни; в зимнее время в некоторых районах могут оказаться практически недоступными для опроса жители сельской глубинки и т.п. Таким образом, соблюдение условий простого случайного отбора возможно не всегда, а если и возможно теоретически, то не всегда приемлемо с экономической точки зрения, так как опрос респондентов, равномерно "рассеянных" на большой территории, и особенно в сельской местности, требует значительных материальных средств. Лучшим, с точки зрения теории выборки, решением этой проблемы является применение других методов случайного отбора - стратифицированного или гнездового (кластерного). Стратифицированный случайный отбор заключается в том, что генеральную совокупность разделяют на относительно однородные части или слои (страты), для каждой страты определяют собственную основу выборки, из которой производят простой случайный отбор. Предполагаемый объем выборки при этом делится между стратами пропорционально их численности, что позволяет обеспечить для всех элементов генеральной совокупности одинаковую вероятность быть отобранным. Стратифицированный случайный отбор применяется, когда генеральная совокупность не является однородной, а также в тех случаях, когда она слишком велика или имеет сложную структуру, так что основу выборки значительно проще получить для отдельных ее частей, чем для генеральной совокупности в целом. В тех случаях, когда стратификация производится по территориальному принципу, отбор иногда называют районированным. Например, при национальных опросах в Беларуси часто применяют районирование по областям. Если генеральная совокупность может быть представлена как совокупность относительно мелких групп элементов (кластеров, гнезд), к ней могут применяться процедуры кластерного (гнездового) отбора. Основа выборки представляет собой список кластеров, к которому применяется процедура простого случайного отбора. Затем отобранные кластеры обследуются полностью или выборочно. Сплошное (серийное) обследование кластеров применяется, если численность групп примерно одинакова, и различия между группами меньше, чем различия между отдельными элементами внутри группы. Примерами серийного отбора являются опросы старшеклассников целыми классами, студентов - академическими группами, рабочих - бригадами и т.п. Если кластеры не удовлетворяют требованиям серийного отбора, их рассматривают как некие промежуточные ступени в многоступенчатом отборе. Например, на территории отбираются в качестве кластеров отдельные населенные пункты, в которых затем производится выборочное обследование населения. Метод случайного кластерного отбора применяется в тех случаях, когда трудно получить репрезентативную основу выборки (получить список кластеров, в любом случае, значительно проще), а также при ограниченных материальных и временных ресурсах, так как групповой опрос по месту учебы или работы или проведение обследования только в некоторых населенных пунктах весьма экономичны. Наряду с методами случайного отбора на практике используется также ряд квазислучайных методов, не использующих таблицы и генераторы случайных чисел, но позволяющих получить результаты, аналогичные результатам случайного отбора. Наиболее популярным из них является систематический отбор. При систематическом отборе основа выборки упорядочивается по какому-либо критерию, а затем из упорядоченного списка, с заданным шагом, извлекаются элементы. Критерий упорядочивания должен исключать возникновение в списке каких-либо циклических закономерностей. Лучшим критерием для списков людей считается алфавитный порядок. Более крупные объекты (населенные пункты, организации, фирмы) могут быть упорядочены по размеру, объему товарооборота, и т.п. Систематический отбор, как и случайный, может быть простым, стратифицированным и кластерным. Популярным вариантом систематического отбора является "маршрутная" выборка, при которой адреса домохозяйств извлекаются из списка, упорядоченного по улицам населенного пункта. Вместе с маршрутной выборкой часто применяют рандомизирующие процедуры, призванные обеспечить "случайность" отбора элемента генеральной совокупности в выборку. К ним относятся, например, случайный выбор первого адреса из списка, запрет на обследование подряд однотипных квартир, процедуры случайного отбора респондента в семье. В рамках теории выборки разработаны также разнообразные стратегии и методы, к которым можно обратиться, если случайный отбор невозможен или требует недопустимо высоких затрат. Основным нестатистическим методом извлечения выборок является квотный отбор. Его применяют, если распределение генеральной совокупности по основным социально-демографическим или другим существенным для исследования признакам известно, но ее списки получить невозможно, или если для осуществления случайного отбора недостаточно времени и средств. В этом случае интервьюерам поручают опросить определенное число лиц с заданными характеристиками, отбирая их по своему усмотрению. Квотный отбор критикуется специалистами по теории выборки, главным образом, за то, что точность результатов, полученных по квотным выборкам, не может быть оценена статистически. Тем не менее, он достаточно популярен благодаря своей простоте, относительно низкой стоимости и анонимности. При исследовании общественного мнения, ценностей, установок, мотивов квотный отбор обычно дает удовлетворительные результаты. Однако его категорически не рекомендуется использовать в исследованиях социальной структуры, стратификации, мобильности. Метод основного массива применяется на небольших генеральных совокупностях, для которых нет смысла проводить выборочное исследование. Обоснование репрезентативности в этом случае носит внестатистический характер, оно осуществляется посредством сравнения исследованной и неисследованной частей генеральной совокупности. Наиболее уязвим, с точки зрения соответствия полученных результатов реальному положению дел, метод доступной выборки, который применяется при исследовании генеральных совокупностей, слишком сложных для исследования другими методами. Обычно это гипотетические генеральные совокупности - аудитория СМИ (опрашиваемая непосредственно через СМИ), потребители определенных товаров (опрашиваемые в магазинах), национальные меньшинства, представителей которых опрашивают в культурных обществах или в местах компактного проживания и т.п. Метод "снежного кома" представляет собой нечто среднее между методами доступной выборкой и основного массива. Он применяется к малочисленным гипотетическим генеральным совокупностям, например, к коллекционерам или экспертам по узкой проблеме. Каждого найденного члена такой совокупности спрашивают, кого из своих коллег он мог бы назвать. Полученный список принимается за основу выборки; опрос продолжается до тех пор, пока имена в списке не начнут повторяться. К большим генеральным совокупностям со сложной структурой часто применяют многоступенчатый отбор. Для этого генеральную совокупность структурируют, разбивая ее на конечное число подсовокупностей. Образуется новая, конкретная и конечная, генеральная совокупность, элементами (единицами отбора) которой являются выделенные подсовокупности. Часть из них отбирается для продолжения исследования. Эта операция может повторяться несколько раз, пока не будут получены подсовокупности, доступные для непосредственного изучения, причем на разных ступенях могут использоваться разные методы отбора и репрезентации. При многоступенчатом отборе основой выборки на каждой ступени является список выделенных структурных единиц отбора. На последней ступени единицы отбора совпадают с единицами наблюдения - объектами из генеральной совокупности, включенными в выборку и подлежащими непосредственному исследованию. Результаты выборочных исследований всегда являются отчасти неопределенными. Это происходит потому, что изучается только часть генеральной совокупности, и измерения производятся с ошибками. Однако при отсутствии грубых просчетов в планировании и реализации выборки эти ошибки можно контролировать, то есть с высокой вероятностью полагать, что они находятся в некоторых пределах, которые представляются исследователю допустимыми. Обычно выделяют две составляющие ошибки выборки, одну из которых называют систематической, а другую случайной ошибкой. Систематическая ошибка представляет собой некоторое смещение выборочного среднего значения признака по отношению к генеральному среднему, не уменьшающееся с увеличением объема выборки. Систематические ошибки обычно связывают с ошибками проектирования выборки и ошибками инструментария исследования. Их часто трудно обнаружить и еще труднее измерить; для этого проводятся специальные методологические исследования и применяются специальные процедуры тестирования выборки и измерительных шкал. Иногда систематические ошибки могут быть определены, если со временем становится известным распределение признака в генеральной совокупности (например, результаты выборов), или в результате скрупулезного анализа артефактов, обнаруженных при анализе данных. Случайные ошибки связаны с вероятностным характером процедур извлечения выборки из генеральной совокупности и ошибками измерения, не имеющими систематического характера. Ошибки такого рода неустранимы, но подчиняются статистическим законам и, соответственно, поддаются контролю. Важнейшее свойство случайных ошибок состоит в том, что они уменьшаются с увеличением объема выборки. Следовательно, увеличивая объем выборки, их можно свести к допустимому пределу, и, тем самым, обеспечить желательную степень точности результатов исследования. Степень точности для каждого показателя, измеряемого в процессе обследования, задается (и измеряется) двумя количественными характеристиками: предельно допустимой величиной ошибки и вероятностью того, что эта величина не будет превышена (доверительной вероятностью). Оба эти значения существенным образом зависят от объема выборки и способа ее извлечения. Стремление повысить точность приводит к быстрому росту необходимого объема выборки и, соответственно, стоимости исследования. Таким образом, каждая реализованная выборка является компромиссом между желательной степенью точности и имеющимися в распоряжении исследователя временными и материальными ресурсами. Итак, ошибкой выборки (А) называется разность между средними арифметическими значениями признака по выборке и по генеральной совокупности:
где х - среднее арифметическое значение признака по выборке; μ - среднее арифметическое значение признака по генеральной совокупности. Таким образом, ошибка выборки измеряется в тех же единицах, что и измеряемый показатель. Поскольку в реальном исследовании среднее значение признака по генеральной совокупности (μ) обычно неизвестно (напротив, исследование проводится с целью его оценить), ошибка выборки не может быть вычислена точно, а только оценена статистическими методами. Сразу оговоримся, что статистическое оценивание ошибок возможно только для вероятностных выборок, на всех ступенях которых применяются случайные методы отбора, и при этом оценивается только случайная составляющая ошибки, а ее систематическая составляющая полагается равной нулю. Мы рассмотрим наиболее простой случай оценивания ошибки и объема выборки - при простом случайном отборе. Случайные ошибки простой случайной выборки из бесконечной генеральной совокупности имеют распределение, близкое к нормальному (Гауссовому), с нулевым средним и дисперсией, равной σ2/n, где σ 2 - дисперсия признака по выборке, n - ее объем. Величина Δст =σ/√n называется стандартной ошибкой выборки. Из свойств нормального распределения следуют два важных обстоятельства. Во-первых, значения таких ошибок обычно невелики. С вероятностью (1-а) они не выходят за пределы так называемого доверительного интервала, который имеет вид:
или
Вероятность а выбирается заранее. Наиболее часто используются значения а = 0.01, 0.05 или 0.1. Соответствующие уровни доверительной вероятности (1-а) составляют 0.99, 0.95 и 0.9. Доверительный коэффициент Z1- α /2 соответствующий доверительной вероятности (1 — α), определяется по таблице стандартного нормального распределения. Перечисленным уровням вероятности соответствуют значения доверительного коэффициента, равные 2.58; 1.96; 1.65. Во-вторых, стандартная ошибка выборки Δст и диапазон изменения случайной ошибки выборки Δ обратно пропорциональны √n , следовательно, их можно контролировать, увеличивая объем выборки. Формулы (1) и (2) применяются для оценивания ошибки выборки после завершения исследования. Однако во многих случаях необходимо до его начала определить, какой объем выборки при выбранном дизайне может обеспечить необходимую точность результатов. Желательная точность результатов (для конкретного признака) задается двумя численными величинами: предельно допустимым значением ошибки Δдоп и вероятностью превысить эту ошибку а. Для простой случайной выборки из бесконечной генеральной совокупности эти две величины связаны с дисперсией признака по генеральной совокупности а2 и объемом выборки п выражением
откуда
В этой формуле предельная ошибка выборки Δдоп и вероятность а задаются исследователем произвольно, а дисперсия генеральной совокупности, если она неизвестна, должна быть предварительно оценена, например, с помощью пилотажного исследования. Степень точности одной и той же выборки для разных показателей может существенно различаться. В этой сложной ситуации мы рекомендуем ориентироваться, в первую очередь, на достижение удовлетворительной точности для признаков, наиболее важных с точки зрения целей исследования. Если генеральная совокупность конечна, и ее объем сравним с объемом выборки, дисперсию ошибки выборки следует вычислять с поправкой на объем генеральной совокупности. Она будет равна:
где N - объем генеральной совокупности. Следовательно, формула для оценивания ошибки выборки примет вид:
а формула для вычисления необходимого объема выборки:
Приведенные выше формулы справедливы для простой случайной выборки. При более сложном дизайне применяются более сложные оценки дисперсии выборочной ошибки и необходимого объема выборки. С этими вопросами можно познакомиться в специальной статистической литературе.
Вопросы для самоконтроля и повторения 1. Выберете подходящий дизайн для исследования: а) самочувствия национальных меньшинств; б) проблем наркоманов; в) рейтинга телевизионных программ; г) межличностных отношений в студенческой группе. 2. а) Определите генеральную совокупность для изучения бытовых проблем в студенческом общежитии вашего университета: состав, конкретность/гипотетичность, численность, структуру, б) Разработайте выборку для такого исследования. 3. 3. В каких единицах будет определяться ошибка выборки при исследовании: а) доходов; б) коэффициента интеллекта IQ; в) возраста; г) при предсказании результатов выборов? 4. а) Определите ошибку выборки, если по прогнозу ожидалось, что за кандидата в депутаты проголосует 49 % избирателей, в то время как реально проголосовали 51 %. б) Можно ли с вероятностью 0.99 утверждать, что эта ошибка является случайной, то есть может быть объяснена последствиями случайного отбора, если объем простой случайной выборки составил 1600 человек, а дисперсия равна 0.25? в) С какой максимальной вероятностью можно утверждать, что ошибка выборки является случайной? г) Какой объем выборки понадобился бы, чтобы при той же дисперсии ошибка выборки с вероятностью 0.99 не превысила 1 %?
Литература 1. Кокрен У. Методы выборочного исследования. М., 1976. 2. Методы сбора информации в социологическом исследовании: В 2-х кн. М., 1990. 3. Ноэль Э. Массовые опросы: введение в методику демоскопии. М., 1978. 4. Оперативные социологические исследования. Мн., 1997. 5. Паниотто В.И. Качество социологической информации. Киев, 1986. 6. Территориальная выборка в социологических исследованиях. М., 1980. 7. Чурилов Н.Н. Проектирование выборочного социологического исследования. Киев, 1986. 8. Шляпентох В.Э. Проблемы репрезентативности социологической информации (случайные и неслучайные выборки в социологии). М., 1976. 9. 9. Шэреги Ф.Э., Гуцу В.Г., Папоян Г.Р. Выборка в опросах общественного мнения: учебное пособие. Кишинев, 1989.
|
||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 683. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
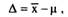
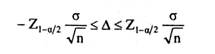 (1)
(1)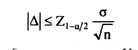 (2)
(2)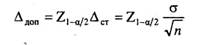 (3)
(3)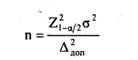 (4)
(4)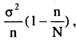
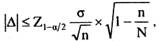 (2а)
(2а)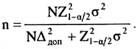 (4a)
(4a)