|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Тема 3. Информационно–аналитическая система как инструмент проведения экономического анализа.1. Общее понятие информационно – аналитической системы. 2. Функции и сферы применения ИАС 3. Классификация аналитических систем 4. Концепции построения ИАС 5. Общая структура информационной аналитической системы
1. Общее понятие информационно – аналитической системы. Современный этап развития рыночных отношений в российской экономике характеризуется началом экономического подъема. Сегодня все большее число организаций приходит к пониманию того, что без наличия своевременной и объективной информации о состоянии рынка, прогнозирования его перспектив, постоянной оценки эффективности функционирования собственных структур и анализа взаимоотношений с бизнес - партнерами и конкурентами их дальнейшее развитие становится практически невозможным. Начинают приобретать определяющее значение знания о протекающих хозяйственных процессах. На успех ведения дела влияют как объективные, так и субъективные факторы. К объективным факторам можно отнести: · закономерности протекания хозяйственных процессов, · правовую среду, · неписаные правила и традиции ведения дел, · экономическую конъюнктуру и т.д.
Большое значение имеет субъективный фактор, под которым понимается влияние на ход бизнес - процессов работников предприятия и в особенности лиц, принимающих решения (ЛПР). Для выработки и принятия соответствующих складывающейся обстановке решений необходима информация, которая должна удовлетворять требованиям полноты, достоверности, своевременности (актуальности), полезности. Основополагающую роль в подготовке принятия решений играет его обоснование по имеющейся у ЛПР информации. Её, как правило, получают из различных внутренних и внешних источников. В интересах выработки адекватного решения используются внутренние информационные ресурсы, которые складываются из отражения деятельности (функционирования) объекта в документах, других видах и способах сбора, обработки, хранения информации. А также внешние по отношению к объекту информационные ресурсы, например (если это предприятие) - корпорации, отрасли, региона, а также глобальные – из средств массовой информации, специальной литературы, всемирной информационной сети Интернет и т.д.  Таким образом, границы информационного пространства как отображения деятельности предприятия и его взаимодействия с внешней средой, в рамках которого принимаются решения, выходят далеко за пределы предприятия. Эти обстоятельства вынуждают использовать имеющиеся в настоящее время весьма развитые программно-технические средства. Широкое и эффективное применение этих средств стало одним из факторов выживаемости и успеха предприятия в условиях острой конкурентной борьбы. Получили широкое распространение автоматизированные информационные системы. Проблема анализа исходной информации для принятия решений оказалась настолько серьезной, что появилось отдельное направление или вид информационных систем – информационно – аналитические системы (ИАС). Информационно-аналитические системы (ИАС) призваны на основе данных, получаемых в режиме реального времени, помогать в принятии управленческих решений. ИАС - это современный высокоэффективный инструмент поддержки принятия стратегических, тактических и оперативных управленческих решений на основе наглядного и оперативного предоставления всей необходимой совокупности данных пользователям, ответственным за анализ состояния дел и принятие управленческих решений. Комплекс информационно-аналитических систем затрагивает всю управленческую вертикаль: корпоративную отчетность, финансово-экономическое планирование и стратегическое планирование.
2. Функции и сферы применения ИАС Основное назначение ИАС — динамическое представление и многомерный анализ исторических и текущих данных, анализ тенденций, моделирование и прогнозирование результатов различных управленческих решений. Основными функциями информационно-аналитической системы являются: · Извлечение данных из различных источников, их преобразование и загрузка в хранилище; · Хранение данных; · Анализ данных, в том числе оперативный и интеллектуальный; · Подготовка результатов оперативного и интеллектуального анализа для эффективного их восприятия потребителями.
Результатом применения средств ИАС являются с одной стороны — регламентные аналитические отчеты, ориентированные на нужды пользователей различных категорий, с другой — средства интерактивного анализа информации и быстрого построения отчетов пользователями-непрограммистами с использованием привычных понятий предметной области. Функцию сбора и хранения информации с сопутствующей доработкой в информационно-аналитических системах, выполняют информационные хранилища (Data Warehouse). В связи с большим объемом и сложностью анализ данных имеет два направления - оперативный анализ данных (информации), широко распространена англоязычная аббревиатура названия – On-line Analytical Processing (OLAP). Основной задачей оперативного или OLAP-анализа является быстрое (в пределах секунд) извлечение необходимой аналитику для обоснования или принятия решения информации. Эту функцию выполняют всевозможные OLAP – средства. Интеллектуальный анализ информации - имеет также широко распространенное в русской специальной литературе англоязычное название Data Mining. Он предназначен для фундаментального исследования проблем в той или иной предметной области. Требования по времени менее жёстки, но используются более сложные методики. Ставятся, как правило, задачи и получают результаты стратегического значения. Эту функцию выполняют всевозможные средства Data Mining. Жестких границ между OLAP и интеллектуальным анализом нет, но при решении сложных задач приходится использовать весьма мощные специальные программные средства. С технической точки зрения ИАС – это набор процедур, методов и регламентов, приводящих к регулярному плановому сбору, хранению, анализу и предоставлению информации, используемой для принятия управленческих решений. Информационно-аналитические системы являются надстройкой над уже функционирующими на предприятии информационными приложениями и не требуют их замены; эти системы аккумулируют данные по всем видам деятельности компании - от состояния складов до финансовой и бухгалтерской отчетности. Информационно - аналитические системы верхнего уровня служат для принятия стратегических решений. Они позволяют руководителю решать следующие задачи: · составление консолидированной отчетности и предоставление сводной информации о деятельности предприятия (финансовые, производственные и другие показатели, динамика их изменений и тенденции), · анализ деятельности дочерних предприятий, филиалов и подразделений компании (анализ доходности, затрат, выполнения плана), · анализ финансовой деятельности (основные финансовые показатели, тенденции, взаиморасчеты), оптимизация финансовых потоков, реальная оценка себестоимости продукции, · проведение комплексной оценки деятельности предприятия, основанной на постоянном контроле четырех наиболее существенных ее аспектов (финансы, отношения с внешним миром, внутреннее состояние компании, инновации), · анализ сбытовых процессов (составление плана, контроль исполнения распоряжений, расчеты за отгруженную продукцию, прогноз поступления средств, прогноз спроса).
Информационно-аналитические системы подразделений предполагают большую детализацию и более сложную аналитическую обработку. Эти системы помогают подготовить информацию для принятия решений в области сбыта, продуктового предложения, финансового планирования. Различают два вида информационно-аналитических систем по режиму и темпу анализа: · статические - имеют заранее разработанный сценарий обработки данных при весьма ограниченных возможностях вариаций запросов; · динамические - обеспечивают обработку нерегламентированных запросов и гибкую систему подготовки отчётов;
Можно выделить следующие принципы построения ИАС на предприятии: · объединение всех информационных процессов предприятия; · встраивание системы в уже сложившуюся организационную структуру предприятия; · координация усилий всех подразделений предприятия при выполнении поставленных задач; · открытость системы для дальнейшего развития; · комплексное использование всех доступных методов анализа; · информационная этика - "от каждого - в общую копилку, и из неё - каждому".
3. Классификация аналитических систем Для обозначения аналитических технологий и средств в целом принято использовать термин "Business Intelligence" или, сокращенно, - BI. Понятие BI объединяет различные средства и технологии анализа и обработки данных масштаба предприятия. На их основе создаются BI-системы. Их цель – повысить качество информации для принятия управленческих решений. BI-системы ранее были известны под названием Систем Поддержки Принятия Решений (СППР, DSS- Decision Support System). В качестве синонимов понятия "СППР" оперируют также понятиями "аналитическая система" или "управленческая система". Сейчас же класс систем BI является независимым классом систем, в который входят системы класса СППР. По оценкам IDC рынок BI состоит из 5 сегментов: 1. OLAP-продукты, 2. инструменты добычи данных, 3. средства построения Хранилищ и Витрин данных, 4. управленческие информационные системы и приложения, 5. инструменты конечного пользователя для выполнения запросов и построения отчетов, 6. системы СППР.
Полный классификатор аналитических систем
Рассмотрим более подробно каждый сегмент.
OLAP-продукты На сегодняшний день в мире разработано множество продуктов, реализующих OLAP-технологии. Чтобы легче было ориентироваться среди них, существует несколько классификаций OLAP-продуктов: · по способу хранения данных, · по месту нахождения OLAP-машины, · по степени готовности к применению. Рассмотрим классификацию систем по способу хранения данных. Основная идея OLAP заключается в построении многомерных таблиц, которые будут доступны для запросов пользователей. Многомерные таблицы (многомерные кубы) строятся на основе исходных и агрегатных данных. И исходные и агрегатные данные для многомерных таблиц могут храниться как в реляционных, так и многомерных базах данных. Поэтому в настоящее время применяются три способа хранения данных: MOLAP (Multidimensional OLAP), ROLAP (Relational OLAP) и HOLAP(Hybrid OLAP). Соответственно, OLAP-продукты по способу хранения данных делятся на три аналогичные категории: · В случае MOLAP, исходные и агрегатные данные хранятся в многомерной БД или в многомерном локальном кубе. Такой способ хранения обеспечивает высокую скорость выполнения OLAP-операций. Но многомерная база в этом случае чаще всего будет избыточной. Куб, построенный на ее основе, будет сильно зависеть от числа измерений. При увеличении количества измерений объем куба будет экспоненциально расти. Иногда это может привести к "взрывному росту" объема данных, парализующему в результате запросы пользователей. · В ROLAP-продуктах исходные данные хранятся в реляционных БД или в плоских локальных таблицах на файл-сервере. Агрегатные данные могут помещаться в служебные таблицы в той же БД. Преобразование данных из реляционной БД в многомерные кубы происходит по запросу OLAP-средства. При этом скорость построения куба будет сильно зависеть от типа источника данных и порой приводит к неприемлемому времени отклика системы. · В случае использования Гибридной архитектуры исходные данные остаются в реляционной базе, а агрегаты размещаются в многомерной. Построение OLAP-куба выполняется по запросу OLAP-средства на основе реляционных и многомерных данных. Такой подход позволяет избежать взрывного роста данных. При этом можно достичь оптимального времени исполнения клиентских запросов. Следующая классификация - по месту размещения OLAP-машины. По этому признаку OLAP-продукты делятся на OLAP-серверы и OLAP-клиенты. · В серверных OLAP-средствах вычисления и хранение агрегатных данных выполняются сервером. Клиентское приложение получает только результаты запросов к многомерным кубам, которые хранятся на сервере. Некоторые OLAP-серверы поддерживают хранение данных только в реляционных базах, другие - только в многомерных. Многие современные OLAP-серверы поддерживают все три способа хранения данных: MOLAP, ROLAP и HOLAP. Одним из самых распространенным в настоящее время серверным решением является OLAP-сервер корпорации Microsoft. · OLAP-клиент устроен по-другому. Построение многомерного куба и OLAP-вычисления выполняются в памяти клиентского компьютера. OLAP-клиенты также делятся на ROLAP и MOLAP. А некоторые могут поддерживать оба варианта доступа к данным. Среди одних из первых клиентских OLAP-средств можно назвать Oracle Discoverer. Те же возможности обеспечивает и отечественная разработка – продукты Аналитической платформы Контур от компании Intersoft Lab.
У каждого из этих подходов есть свои "плюсы" и "минусы". Нельзя однозначно говорить о преимуществах серверных средств перед клиентскими и наоборот. На практике такой выбор является результатом компромисса "эксплуатационных показателей", стоимости программного обеспечения и затрат на разработку, внедрение и сопровождение аналитической системы. Следующая классификация OLAP-продуктов - по степени готовности к применению. Различают: OLAP-компоненты, инструментальные OLAP – системы и конечные OLAP-приложения. · OLAP-компонента – это инструмент разработчика. С ее помощью разрабатываются клиентские OLAP-программы. Различают MOLAP и ROLAP-компоненты: MOLAP-компоненты являются инструментами генерации запросов к OLAP-серверу. Они также обеспечивают визуализацию полученных данных. ROLAP-компоненты содержат собственную OLAP-машину. OLAP-машина обеспечивает построение OLAP-кубов в оперативной памяти и отображает их на экране. Одна из наиболее доступных, но в то же время и одна из самых слабых OLAP-компонент – Decision Cube в составе Borland Delphi. · Инструментальные OLAP-системы – это программные продукты, предназначенные для создания аналитических приложений. Различают две категории инструментальных OLAP-систем: системы для программирования и системы для быстрой настройки. Системы для программирования – это среда разработчика аналитических систем. В ней, путем программирования запросов к данным, алгоритмов расчета и OLAP-интерфейсов можно создать OLAP-приложение для конечного пользователя. Представителем этого класса программного обеспечения является аналитическая платформа Knosys Pro Clarity. С другой стороны, OLAP-системы для быстрой настройки – это средства, которые предоставляют визуальный интерфейс для создания OLAP-приложений без программирования. Такие системы включают визуальный генератор запросов, встроенные алгоритмы агрегации и инструменты настройки пользовательских OLAP-интерфейсов. В такой технологии реализована большая часть инструментов пакета BusinessObjects и Аналитической платформы Контур. · Наконец, к третьей категории OLAP-продуктов по степени готовности к применению относятся конечные OLAP-приложения. Это готовые прикладные решения для конечного пользователя. Они требуют только установки, и, не всегда, настройки под специфику пользователя. Пример такого решения – OLAP-приложения системы "Контур Стандарт", подготовленные для анализа данных в различных отраслях и для решения различных аналитических задач. Инструменты добычи данных Knowledge Discovery in Databases (KDD)– это процесс поиска полезных знаний в "сырых" данных. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов "раскапывания данных" (Data Mining), а также обработки и интерпретации полученных результатов. Центральным элементом этой технологии являются методы Data Mining, позволяющие обнаруживать знания при помощи математических правил: · Фильтрация. Необходимость в фильтрации возникает, когда нужно отделить полезную информацию от искажающего его шума за счет сглаживания, очистки, редактирования аномальных значений, устранения незначащих факторов, понижения размерности информации и т.д. Применение фильтрации в системах анализа данных относится к первичной обработке данных и позволяет повысить качество исходных данных, а, следовательно, и точность результата анализа. · Деревья решений. Они позволяют представлять правила в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Под правилом понимается логическая конструкция, представленная в виде «если..., то...». Деревья решений применяются при решении задач поиска оптимальных решений на основе описанной модели поведения. · Ассоциативные правила. Они позволяют находить закономерности между связанными событиями. Примером такого правила служит утверждение, что в том случае, если произошло событие А, то произойдет и событие В с вероятностью C. Впервые это задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis). · Генетические алгоритмы. Они применяются при решении задач оптимизации. Эти методы были открыты при изучении эволюции и происхождения видов. Генетические алгоритмы нужны для настройки нейронных сетей, а также решения различных задач, когда можно составить описание возможных вариантов решения в виде вектора параметров, и известен критерий, определяющий эффективность каждого варианта. Генетические алгоритмы применяются для составления расписаний, портфелей ценных бумаг, заполнения контейнеров при перевозке (пересылке) грузов, выбор маршрутов движения, конфигурации оборудования и т.д. · Нейронные сети. Они реализуют алгоритмы на основе сетей обратного распространения ошибки, самоорганизующихся карт Кохонена, RBF-сетей, сетей Хэмминга и других подобных алгоритмов анализа данных. Нейронные сети применяются для решения самых различных задач - восстановление пропусков в данных, поиск закономерностей, классификация и кластеризация данных, прогнозирование и моделирование. Инструменты добычи данных поставляются заказчикам двумя способами: · в составе OLAP-систем, · в виде самостоятельных систем Data Mining. Функциональность Data Mining в той или иной степени полноты реализации включена в аналитические системы различных производителей – Oracle, Hyperion, SAS и т.д. Однако, наиболее «продвинутыми» в этом плане являются специализированные системы математического анализа данных. В России авторитетным разработчиком систем в технологии KDD является компания "Лаборатория BaseGroup". Средства построения Хранилищ и Витрин данных Хранилища и Витрины данных создаются с применением специализированных средств построения Хранилищ\витрин данных. К этим средствам относятся: · средства проектирования Хранилищ данных, · средства извлечения, преобразования и загрузки данных, · готовые предметно-ориентированные ХД. Средства проектирования Хранилищ данных входят в состав реляционных и многомерных СУБД от таких производителей как Microsoft, Oracle, IBM, Sybase и других. Также часто применяются универсальные CASE-инструменты, такие как BPWin и ErWin. После описания структур хранения данных специальными системными утилитами выполняется их генерация. Такой подход к созданию Хранилища данных позволяет построить индивидуальное Хранилище или Витрину данных в сжатые сроки. В тоже время такой подход затрудняет перенос наработок от одного заказчика к другому и обмен практическим опытом в решении аналитических задач. Альтернативным способом построения Хранилищ данных является применение других специализированных средств – Студий для построения Хранилищ данных. Такие продукты предлагают набор шаблонов и заготовок для быстрого создания Хранилища. В составе Студии может предоставляться базовая модель Хранилища данных, ориентированная на определенную бизнес-сферу. С помощью таких инструментов можно значительно быстрее создать Хранилище данных, воспользовавшись опытом предыдущих решений и начать его эксплуатацию. Продукты этого класса, в частности, предлагает компания Sybase – это продукт Industry Warehouse Studio. ETL-средства (extraction, transformation, loading) - средства извлечения, преобразования и загрузки данных) обеспечивают три основных процесса, используемые при переносе данных из одного приложения или системы в другие. ETL-средства извлекают информацию из исходной базы данных, преобразуют ее в формат, поддерживаемый базой данных назначения, а затем загружают в нее преобразованную информацию. Эти средства обычно входят в состав функциональности реляционных и многомерных СУБД или Студий для построения Хранилищ данных. Однако существуют и специализированные системы, реализующие только ETL-функции. Классической ETL-системой является, например, продукт Ascential DataStage компании Ascential Software. И, наконец, существует еще один способ построения Хранилищ и Витрин данных – это применение готовых предметно-ориентированных Хранилищ данных. Это самый надежный способ построить Хранилище данных в сжатые сроки. Готовые к эксплуатации Хранилища данных характеризуются наличием в них механизмов средств построения Хранилищ/Витрин данных, взаимосвязанных посредством единого словаря метаданных. К ним относятся - процедуры извлечения, преобразования, очистки и загрузки данных, функции генерации баз данных и процедур обработки, механизмы построения выборок данных, интерфейсы просмотра и анализа данных. Ограничением в применении готовых Хранилищ данных является их предметная ориентация. Например, финансовое Хранилище данных невозможно применить для решения задач оптимизации химического производства. Примером готового предметно-ориентированного Хранилища данных является система Контур Корпорация от компании Intersoft Lab. Применение предметно-ориентированных Хранилищ данных отражает общемировую тенденцию развития рынка BI, наметившуюся в последнее время – предоставления платформ для "быстрой" разработки аналитических приложений. Управленческие информационные системы и приложения Существует еще один очень разносторонний класс аналитических систем. Это – конечные решения для управленцев и аналитиков. Исторически сложилось так, что технологическая основа реализации таких систем существенно различается. Одни из них построены на современных аналитических инструментах, другие – с применением базовых информационных технологий. Чтобы легче ориентироваться в этих системах вводится 3 классификации: · по виду решаемой задачи, · по масштабу решаемой задачи, · по технологическому построению.
Аналитические системы классифицируются по виду задач, решаемых с их помощью. Среди видов задач можно выделить: · Анализ финансового состояния банка или предприятия, выполняемый по внешним публичным данным, таким как баланс, отчет о финансовых результатах, иногда - приложение к балансу и отчет о движении денежных средств. Системы - Audit Expert (Про-Инвест), Альт-финансы (Альт), АБФИ (Вестона), Аналитик, АФСП, АДП (ИНЭК) и другие. · Инвестиционный анализ – для комплексной оценки эффективности инвестиционных проектов и принятия решения об их финансировании, Project Expert (Про-Инвест), Альт-Инвест (Альт) и другие. · Подготовка бизнес-планов, учитывающих вариации схем производства, сбыта и финансирования, комплексного анализа маркетинговой ситуации, чувствительности проекта по основным параметрам. Системы - Project Expert (Про-Инвест), Альт-Инвест (Альт) и другие. · Маркетинговый анализ, позволяющий оценить положение компании на рынке, провести сравнительный анализ ее сбытовой деятельности с конкурентами, сформировать оптимальную структуру сбыта, определить доходность различных сегментов рынка и товаров, долю рынка компании, темпы роста и другое. Системы - Marketing Expert (Про-Инвест), Касатка и другие. · Управление проектами, применяемое для разработки расписания исполнения проекта, определения критического пути и резервов времени исполнения операций проекта; потребности проекта в финансировании, материалах и оборудовании, анализ рисков и планирование расписания с учетом рисков и так далее. Системы - MS Project (Microsoft), Open Plan (Welcom Software Technology) и другие. · Бюджетирование, обеспечивающее планирование, учет и анализ по центрам финансовой ответственности, бизнесам, продуктам в разрезе активов и пассивов, доходов и расходов, выполнение аллокаций и расчет финансового результата. Системы - Hyperion Pillar, Comshare MPC, Контур Корпорация. Бюджет (Intersoft Lab) и другие. · Финансовое управление, включающее помимо задач бюджетирования задачи финансового планирования, управленческого учета, трансфертного управления ресурсами, оценки бизнесов по методу ABC, анализа активов, пассивов, рисков. Системы - Oracle Financial Services Applications (Oracle), Контур Корпорация. Финансовое управление (Intersoft Lab) и другие.
На практике встречается гораздо больше видов задач, но здесь был перечислен ряд только тех задач, которые нашли свое воплощение в тиражных аналитических системах. Некоторые из этих систем могут решать только одну задачу, другие являются комплексом, включающим в себя широкий перечень взаимосвязанных задач. Аналитические системы также классифицируются по масштабу решаемой задачи: · Системы автоматизации труда одного специалиста. Это так называемые DeskTop-системы, предназначенные для автоматизации труда узкого специалиста. Как правило, для эксплуатации таких систем не требуется помощь службы автоматизации. · Системы для коллективной работы группы сотрудников. Такие системы содержат средства, обеспечивающие коллективную работу пользователей в режиме реального времени с единой базой данных в рамках прав доступа. Такие системы уже требуют выполнения функций администрирования и сопровождения. · Системы для применения в территориально распределенной корпорации. Эти системы включают в себя свойства аналитических систем для групп пользователей, а также средства взаимодействия с удаленными подразделениями корпорации (филиалами) в виде технологий сбора данных, дистрибуции НСИ и отчетов. Системы данного класса сложны в эксплуатации, но при этом обеспечивают наиболее полное решение аналитических и управленческих задач. По технологическому построению аналитические системы можно условно разделить на монолитные и настраиваемые: · Монолитные аналитические системы характеризуются тем, что аналитическая методика в них реализуется в коде самой программы, а не в виде настройки универсального аналитического инструмента. В этом случае аналитическая система не требует, как правило, выполнения существенных работ по своей настройке (за исключением систем класса Data Mining). Она может использоваться практически сразу после установки. В то же время такие системы не "гибкие" и плохо поддаются изменениям в соответствии с требованиями пользователя. Монолитные системы разрабатываются с применением базовых средств программирования и СУБД. · Настраиваемые аналитические системы характеризуются тем, что при их создании применяются универсальные аналитические инструменты и специализированные средства, такие как OLAP, Студии, ETL, Data Mining. Их применение позволяет повысить качество аналитической системы, дает перспективы развития, но в то же время приводит к удорожанию конечного решения. Прикладные аналитические системы, выполненные в виде настроек универсальных аналитических инструментов, требуют большего объема работ при внедрении, однако позволяют реализовывать уникальные аналитические методики, принятые в организации.
Компромиссом между этими двумя классами систем является реализация аналитической методики в виде Приложения универсальной аналитической системы. Такой подход позволяет выполнять их тиражирование независимо друг от друга. Но подобных систем в настоящее время на рынке представлено крайне мало.
Инструменты конечного пользователя для выполнения запросов и построения отчетов Системы данного класса (Query & Reporting) предназначены для формирования запросов к информационным системам в пользовательских терминах, а также их исполнение, интеграцию данных из разных источников, просмотр данных с возможностями детализации и обобщения и построение полноценных отчетов, как экранных, так и печатных. Предполагается, что уровень подготовки специалиста, создающего отчеты, может быть приравнен к опыту среднего пользователя Excel. Поэтому пользователь составляет запрос к источнику данных, используя заранее подготовленный программистом каталог терминов (семантический слой). Визуализация результатов запроса может быть представлена пользователю в различном виде – плоские или многомерные таблицы, графики, диаграммы, различные специализированные интерфейсы. Инструменты конечного пользователя для выполнения запросов и построения отчетов поставляются двумя способами: · в составе OLAP-систем, · в виде специализированных систем Query & Reporting.
Практически каждая система класса OLAP снабжена средствами Query & Reporting. Эти средства могут быть как встроенными в основной продукт (примеры – Business Objects, "Контур Стандарт", Oracle Discoverer), так и выделенными в отдельный продукт (например, система Impromptu в составе продуктов Cognos). Также существуют и специализированные системы генерации и дистрибуции отчетов. Наиболее распространенные из них – это продукты компаний Crystal Decisions и Actuate. В то же время эти системы имеют в своем составе собственные OLAP-средства. Поэтому провести четкую грань между OLAP-системами и системами класса Query & Reporting практически невозможно. Пример – продукты компании MicroStrategy, которые различные аналитики и издания с равной регулярностью относят к продуктам обоих классов.
4. Концепции построения ИАС Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и управления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения. В последние годы в мире оформился ряд новых концепций хранения и анализа корпоративных данных: 1) Хранилища данных, или Склады данных (Data Warehouse); 2) Оперативная аналитическая обработка (On-Line Analytical Processing, OLAP); 3) Интеллектуальный анализ данных - ИАД (Data Mining).
Технологии OLAP тесно связаны с технологиями построения Data Warehouse и методами интеллектуальной обработки - Data Mining. Поэтому наилучшим вариантом является комплексный подход к их внедрению. Для того чтобы существующие хранилища данных способствовали принятию управленческих решений, информация должна быть представлена аналитику в нужной форме, то есть он должен иметь развитые инструменты доступа к данным хранилища и их обработки. Очень часто информационно-аналитические системы, создаваемые в расчете на непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы называются в литературе Информационными системами руководителя (ИСР), или Executive Information Systems (EIS). Они содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатом работы такой системы, как правило, являются многостраничные отчеты, после тщательного изучения которых у аналитика появляется новая серия вопросов. Однако каждый новый запрос, непредусмотренный при проектировании такой системы, должен быть сначала формально описан, закодирован программистом и только затем выполнен. Время ожидания в таком случае может составлять часы и дни, что не всегда приемлемо. Таким образом, внешняя простота статических ИСР, за которую активно борется большинство заказчиков информационно-аналитических систем, оборачивается катастрофической потерей гибкости. Динамические ИАС, напротив, ориентированы на обработку нерегламентированных запросов аналитиков к данным. Работа аналитиков с этими системами заключается в интерактивной последовательности формирования запросов и изучения их результатов. Но динамические ИАС могут действовать не только в области оперативной аналитической обработки (OLAP); поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах: 1. Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных. 2. Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP). Здесь можно или ориентироваться на специальные многомерные СУБД, или оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД. 3. Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining), главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
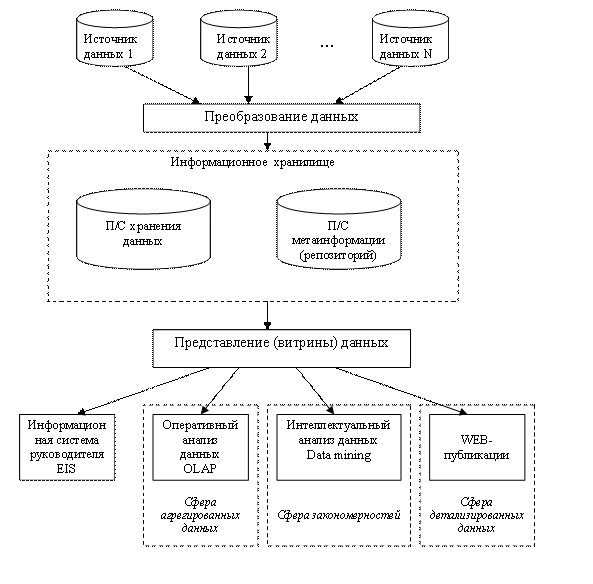
5. Общая структура информационной аналитической системы Полная структура информационно-аналитической системы, построенной на основе хранилища данных, показана на рисунке 1. В конкретных реализациях отдельные компоненты этой схемы часто отсутствуют.
Рисунок 1. Структура информационной аналитической системы (ИАС)
Рассмотрим состав основных подсистем. Подсистема хранения данных Многомерное хранилище данных может быть организовано в виде одной из следующих структур: 1. физической структуры, называемой MOLAP, в которую с определенной периодичностью загружаются данные из файлов – источников, принадлежащих базам оперативных данных 2. виртуальной структуры, называемой ROLAP, которая динамически используется при запросах. ROLAP – система рассматривается просто как надстройка над реляционными базами данных, обеспечивающая удобный интерфейс пользователя. Типичными инструментальными средствами, поддерживающими ROLAP, является Business Objects. 3. гибридной структуры, называемой НOLAP, которая используется при построении многоуровневых информационных хранилищ, применяемых на разных уровнях управления больших корпораций.
Анализ параметров использования ROLAP и MOLAP информационных хранилищ показывает, что внедрение и эксплуатация ROLAP - систем является более простым и дешевым по сравнению с MOLAP – системами, но уступают последним в эффективности оперативного анализа данных.
Подсистема метаинформации Репозиторий представляет собой описание структуры информационного хранилища: состава показателей, иерархии агрегаций измерений, форматов данных, используемых функций, физического размещения на сервере, прав доступа пользователей, частоты обновления. В репозитории задается схема отображения структуры файлов-источников данных на структуре ИХ, а также схема отображения структуры ИХ на витринах данных. Через репозиторий осуществляется интерпретация запросов к ИХ на проведение оперативного анализа данных.
Подсистема преобразования данных (загрузки хранилища) Подсистема загрузки ИХ создается только для MOLAP – систем. Для ROLAP – систем в процессе выполнения запросов осуществляется преобразование данных из файлов – источников. В том и другом случаях требуется выполнение следующих основных функций: · сбор данных · очистка данных · агрегирование данных
Сбор данных предполагает передачу данных из источников в ИХ в соответствии со схемой отображения, представленной в репозитории. В процессе очистки данных осуществляется проверка целостности, исключение дублирования данных, отбраковка случайных данных, восстановление отсутствующих данных, приведение данных к единому формату. В случае необходимости агрегирования данных осуществляется суммирование итогов по заданным в репозитории признакам.
Подсистема представления данных (организация витрин данных) Под витриной данных понимается предметно-ориентированное хранилище данных, как правило, агрегированной информации, предназначенное для использования группой пользователей в рамках конкретного вида деятельности предприятия, например маркетинга и т.д. Как правило, витрины данных являются подмножествами общего хранилища данных компании, которое служит для них источником. Обычно общее ИХ и витрины данных разрабатываются параллельно.
Подсистема оперативного анализа данных Подсистема оперативного анализа данных, как правило, используется лицами, подготавливающими информацию для принятия решений, путем выполнения различных статистических группировок исходных данных. В рамках пользовательского интерфейса для оперативного анализа данных используются следующие базовые операции: · Поворот. Добавление нового признака анализа. · Проекция. Выборка подмножества по задаваемой совокупности измерений. При этом значения, лежащие на оси проекции, суммируются. · Раскрытие. Осуществляется декомпозиция признака агрегации на компоненты, например, признак года разбивается на кварталы. При этом автоматически детализуются числовые показатели. · Свертка. Операция обратная раскрытию. При этом значения детальных показателей суммируются в агрегируемый показатель. · Сечение или срез. Выделение подмножества данных по конкретным значениям одного или нескольких измерений.
Подсистема интеллектуального анализа данных Подсистема интеллектуального анализа данных используется специальной категорией пользователей – аналитиков, которые на основе ИХ обнаруживают закономерности в деятельности предприятия и на рынке, используемые в дальнейшем для обоснования стратегических и тактических решений. Интеллектуальный анализ требует более сложных методов анализа по сравнению со статическими группировками и выполняется путем проведения множества сеансов. Типичными задачами интеллектуального анализа данных являются: · Установление корреляций, причинно-следственных связей и временных связей событий, например определение местоположения прибыльных предприятий. · Классификация ситуаций, позволяющая обобщать конкретные события в классы, например определение типичного профиля покупателя конкретных видов продукции. · Прогнозирование развития ситуаций, например прогнозирование цен, объемов продаж, производства. К основным методам интеллектуального анализа данных относятся: - Методы многомерного статистического анализа, - Индуктивные методы построения деревьев решений, - Нейронные сети. Подсистема «Информационная система руководителя» Информационная система руководителя предназначена для лиц, непосредственно принимающих решения. Поэтому интерфейс таких систем должен быть в наибольшей степени упрощенным. Обычно в качестве интерфейса руководителям предприятия предлагается набор стандартных отчетов и графиков, настраиваемых на потребности руководителя через систему меню. Часто в качестве интерфейса предлагаются диаграммы Ишикава, представляющие собой саморазворачивающееся дерево показателей, в котором листья ветвей раскрашиваются в разные цвета, символизирующие характер состояния показателя (нормальный, тревожный, кризисный). Лист любой ветви дерева может быть развернут а таблицу значений показателя или график. Подсистема WEB – публикации Подсистема WEB – публикации предполагает преобразование полученной из ИХ информации в HTML – вид, доступный для ее просмотра удаленными клиентами с помощью браузеров Интернета.
Тема 4. Хранилища данных 1. Пространственная интерпретация данных 2. Понятие хранилища данных 3. Структура хранилищ данных 4. Вопросы реализации Хранилищ Данных 5. Хранилище данных предприятия
1. Пространственная интерпретация данных Программные инструментальные средства, обеспечивающие автоматизацию аналитических работ в целях поддержки принятия решений, в литературе получили два распространенных названия: ОLАР - системы и информационные Хранилища. Как правило, все инструментальные средства, предназначенные для автоматизации аналитических работ, приспособлены для обработки многомерных массивов информации, для хранения которых используются многомерные базы данных. Информационное пространство, отображающее функционирование объекта, многомерно. Естественно стремление аналитика и ЛПР к тому, чтобы иметь дело с моделью данных в наиболее естественном виде. Это обстоятельство привело к тому, что с помощью современных программно-технических средств, имеющих широкие возможности интерпретации данных, были созданы соответствующие многомерные модели. В последнее десятилетие XX века основной моделью данных использованной в многочисленных инструментальных средствах создания и поддержки баз данных - СУБД была реляционная модель. Данные в ней представлены в виде множества связанных ключевыми полями двумерных таблиц – отношений (табл. 1). Таблица 1 Реляционная модель представления данных
А теперь представим, что у нас не три модели, а 30 и не три, а 12 различных месяцев. В случае построчного (реляционного) представления мы получим отчет в 360 строк (30х12), который займет не менее 5-6 страниц. В случае же многомерного (в нашем случае двухмерного) представления мы получим достаточно компактную таблицу 12 на 30, которая вполне уместится на одной странице и которую, даже при таком объеме данных, можно реально оценивать и анализировать (табл. 2). Таблица 2 Многомерная модель представления данных
И когда говорится о многомерной организации данных, вовсе не подразумевается то, что данные представляются конечному пользователю (визуализируются) в виде четырех или пятимерных гиперкубов. Это невозможно, да и пользователю более привычно и комфортно иметь дело с двухмерным табличным представлением и двухмерной бизнес - графикой. Многомерная модель данных представляет исследуемый объект в виде многомерного куба, чаще используют трехмерную модель. По осям или граням куба откладываются измерения или реквизиты - признаки. Реквизиты - основания являются наполнением ячеек куба. Многомерное представление при описании структур данных Основными понятиями, с которыми оперирует пользователь и проектировщик в многомерной модели данных, являются: · измерение (Dimension); · ячейка (Cell). Иногда вместо термина "Ячейка" используется термин "Показатель" (Measure).
Измерение - это множество однотипных данных, образующих одну из граней гиперкуба. Например - Дни, Месяцы, Кварталы, Годы - это наиболее часто используемые в анализе временные Измерения. Примерами географических измерений являются: Города, Районы, Регионы, Страны и т.д. В многомерной модели данных Измерения играют роль индексов, используемых для идентификации конкретных значений (Показателей), находящихся в Ячейках гиперкуба. В свою очередь, Показатель - это поле (обычно цифровое), значения которого однозначно определяются фиксированным набором Измерений. В зависимости от того, как формируются его значения, Показатель может быть определен, как: · Переменная (Variable) - значения таких Показателей один раз вводятся из какого-либо внешнего источника или формируются программно и затем в явном виде хранятся в многомерной базе данных (МБД); · Формула (Formula) - значения таких Показателей вычисляются по некоторой заранее специфицированной формуле.
То есть для Показателя, имеющего тип Формула, в БД хранится не его значения, а формула, по которой эти значения могут быть вычислены. Заметим, что это различие существует только на этапе проектирования и полностью скрыто от конечных пользователей. В примере каждое значение поля Объем продаж однозначно определяется комбинацией полей: Модель автомобиля; Месяц продаж. Но в реальной ситуации для однозначной идентификации значения Показателя, скорее всего, потребуется большее число измерений, например: Модель автомобиля; Менеджер; Время (например, Год). Измерения: Модель автомобиля – «1», «2», «3» Время (Год) - 1994, 1995, 1995 Менеджер - Петров, Смирнов, Яковлев Показатель: Объем Продаж И в терминах многомерной модели речь будет идти уже не о двухмерной таблице, а о трехмерном гиперкубе: o первое Измерение - Модель автомобиля; o второе Измерение - Менеджер, продавший автомобиль; o третье Измерение - Время (Год); на пересечении граней которого находятся значения Показателя Объем продаж.
Заметим, что, в отличие от Измерений, не все значения Показателей должны иметь и имеют реальные значения. Например, Менеджер Петров в 1994 г. мог еще не работать в фирме, и в этом случае все значения Показателя Объем продаж за этот год будут иметь неопределенные значения.
Гиперкубические и поликубические модели данных В различных МСУБД используются два основных варианта организации данных: · Гиперкубическая модель; · Поликубическая модель.
В чем состоит разница? Системы, поддерживающие Поликубическую модель предполагают, что в МБД может быть определено несколько гиперкубов с различной размерностью и с различными Измерениями в качестве их граней. Например, значение Показателя Рабочее Время Менеджера, скорее всего, не зависит от Измерения Модель Автомобиля и однозначно определяется двумя Измерениями: День и Менеджер. В Поликубической модели в этом случае может быть объявлено два различных гиперкуба: Двухмерный - для Показателя Рабочее Время Менеджера; Трехмерный - для Показателя Объем Продаж. В случае же Гиперкубической модели предполагается, что все Показатели должны определяться одним и тем же набором Измерений. То есть только из-за того, что Объем Продаж определяется тремя Измерениями, при описании Показателя Рабочее Время Менеджера придется также использовать три Измерения и вводить избыточное для этого Показателя Измерение Модель Автомобиля.
Методы извлечения информации из кубов данных
Для извлечения информации из кубов данных используются различные операции манипулирования Измерениями: 1) Формирование "Среза". Пользователя редко интересуют все потенциально возможные комбинации значений Измерений. Более того, он практически никогда не работает одновременно сразу со всем гиперкубом данных. Подмножество гиперкуба, получившееся в результате фиксации значения одного или более Измерений, называется Срезом (Slice). Например, если мы ограничим значение Измерения Модель Автомобиля = "ВАЗ2108", то получим подмножество гиперкуба (в нашем случае - двухмерную таблицу), содержащее информацию об истории продаж этой модели различными менеджерами в различные годы. 2) Операция "Вращение". Изменение порядка представления (визуализации) Измерений (обычно применяется при двухмерном представлении данных) называется Вращением (Rotate). Эта операция обеспечивает возможность визуализации данных в форме, наиболее комфортной для их восприятия. Например, если менеджер первоначально вывел отчет, в котором Модели автомобилей были перечислены по оси X, а Менеджеры по оси Y, он может решить, что такое представление мало наглядно, и поменять местами координаты (выполнить Вращение на 90 градусов). 3) Отношения и Иерархические Отношения. В нашем примере значения Показателей определяются только тремя измерениями. На самом деле их может быть гораздо больше и между их значениями обычно существуют множество различных Отношений (Relation) типа "один ко многим". Например, каждый Менеджер может работать только в одном подразделении, а каждой модели автомобиля однозначно соответствует фирма, которая ее выпускает: Менеджер ->Подразделение; Модель Автомобиля ->Фирма-Производитель. Заметим, что для Измерений, имеющих тип Время (таких как День, Месяц, Квартал, Год), все Отношения устанавливаются автоматически, и их не требуется описывать. В свою очередь, множество Отношений может иметь иерархическую структуру - Иерархические Отношения (Hierarchical Relationships). Вот только несколько примеров таких Иерархических Отношений: День -> Месяц -> Квартал -> Год; Менеджер -> Подразделение -> Регион -> Фирма -> Страна; Модель Автомобиля -> Завод-Производитель -> Страна. И часто более удобно не объявлять новые Измерения и затем устанавливать между ними множество Отношений, а использовать механизм Иерархических Отношений. В этом случае все потенциально возможные значения из различных Измерений объединяются в одно множество. Например, мы можем добавить к множеству значений Измерения Менеджер ("Петров", "Сидоров", "Иванов", "Смирнов"), значения Измерения Подразделение ("Филиал 1", "Филиал 2", "Филиал 3") и Измерения Регион ("Восток", "Запад") и затем определить между этими значениями Отношение Иерархии. 4) Операция Агрегации. С точки зрения пользователя, Подразделение, Регион, Фирма, Страна являются точно такими же Измерениями, как и Менеджер. Но каждое из них соответствует новому, более высокому уровню агрегации значений Показателя Объем продаж. В процессе анализа пользователь не только работает с различными Срезами данных и выполняет их Вращение, но и переходит от детализированных данных к агрегированным, т.е. производит операцию Агрегации (Drill Up). Например, посмотрев, насколько успешно в 2014 г. Петров продавал модели "1" и "3", управляющий может захотеть узнать, как выглядит соотношение продаж этих моделей на уровне Подразделения, где Петров работает. А затем получить аналогичную справку по Региону или Фирме. 5) Операция Детализации. Переход от более агрегированных к более детализированным данным называется операцией Детализации (Drill Down). Например, начав анализ на уровне Региона, пользователь может захотеть получить более точную информацию о работе конкретного Подразделения или Менеджера.
2. Понятие хранилища данных Термин "OLAP" неразрывно связан с термином "хранилище данных" (Data Warehouse). Приведем определение, сформулированное "отцом-основателем" хранилищ данных Биллом Инмоном: "Хранилище данных - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений". Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов. Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию, которая и так "живет" в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных "уголках" корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Таким образом, задача хранилища - предоставить "сырье" для анализа в одном месте и в простой, понятной структуре. Есть и еще одна причина, оправдывающая появление отдельного хранилища - сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера. Под хранилищем можно понимать не обязательно гигантское скопление данных - главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин - Data Marts (киоски или витрины данных). В основе концепции Хранилищ Данных лежат две основополагающие идеи: · Интеграция ранее разъединенных детализированных данных: ¾ исторические архивы, ¾ данные из традиционных СОД, ¾ данные из внешних источников в едином Хранилище Данных, их согласование и возможно агрегация. · Разделение наборов данных используемых для операционной обработки и наборов данных используемых для решения задач анализа.
Предметом концепции Хранилищ Данных являются сами данные. То есть, её предметом являются не способы описания и отображения объектов предметной области, а собственно данные, как самостоятельный объект предметной области, порожденной в результате функционирования ранее созданных информационных систем. Основные требования к данным в хранилищах приведены в таблице 2. Таблица 2. Основные требования к данным в Хранилище Данных
Для правильного понимания данной концепции необходимо понимание следующих принципиальных моментов: Концепция Хранилищ Данных - это концепция подготовки данных для анализа. · Концепция Хранилищ Данных не предопределяет архитектуру целевой аналитической системы. Она говорит о том, какие процессы должны выполняться в системе, но не о том, где конкретно и как эти процессы должны выполняться. · Концепция Хранилищ Данных предполагает не просто единый логический взгляд на данные организации. Она предполагает реализацию единого интегрированного источника данных. Без поддержки хронологии (наличия исторических данных) нельзя говорить о решении задач прогнозирования и анализа тенденций. Но наиболее критичными и болезненными, оказываются вопросы, связанные с согласованием данных.
Основным требованием аналитика, является даже не столько оперативность, сколько достоверность ответа. Но достоверность, в конечном счете, и определяется согласованностью. Пока не проведена работа по взаимному согласованию значений данных из различных источников, сложно говорить об их достоверности. Реализация ИХ может быть осуществлена несколькими способами: Централизованное хранилище данных Такой подход означает, что при нескольких источниках информации - операционных базах данных создаётся единое централизованное хранилище (рис. 1).
Рисунок 1. Единое централизованное хранилище
Вся поступающая в ИХ информация должна быть преобразована в принятую в данном ИХ структуру. Передача данных из операционных БД в ИХ, которая сопровождается доработкой, может быть организована по заданному временному графику и правилам доработки Распределенное хранилище данных Возможен и имеет место противоположный подход к хранению данных на основе распределения функций ИХ по местам их возникновения или группировки нескольких операционных БД вокруг локального или регионального информационного хранилища. Эти хранилища могут быть ориентированы на определённую предметную область или на регион в корпоративных структурах. Система локальных хранилищ действует в качестве распределённого хранилища (рис. 2).
Рисунок 2. Распределенное хранилище данных
Не исключается и наличие центрального хранилища, но в такой структуре требования к его размерности значительно облегчаются. Автономные витрины данных Одним из вариантов организации централизованного хранения и представления информации является концепция витрин данных. При таком подходе информация, относящаяся к крупной предметной области – например, информационному пространству крупной корпоративной системы, имеющей несколько достаточно самостоятельных направлений деятельности, группируется по этим направлениям в специально организованных базах данных, которые называют витринами данных. Этот подход является развитием концепции распределенного ИХ в части придания функций предметной ориентированности некоторым локальным ИХ. Такой подход позволяет обойтись сравнительно менее ресурсоемкими аппаратными и программными средствами, обеспечивает повышение адаптируемости системы к изменяющимся условиям, расширяет доступность для внедрения. Пользователь предприятия или другого подразделения корпорации получает своё ИХ, обслуживающее местные потребности. Единое интегрированное хранилище и много витрин данных Эта структура ИХ объединяет две концепции: единого интегрированного хранилища и связанных с ним и получающих из него информацию витрин данных. В таком варианте имеется крупное информационное хранилище агрегированной и подработанной информации, которое может удовлетворить потенциальные запросы по отдельным направлениям деятельности. Здесь очевидны преимущества: данные заранее агрегируются, обеспечивается единая хронология, согласованы различные форматы, устраняются противоречивость и неоднозначность данных - информация приобретает необходимую кондицию для быстрого и достаточно полного удовлетворения необходимого множества запросов, |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 770. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||