|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
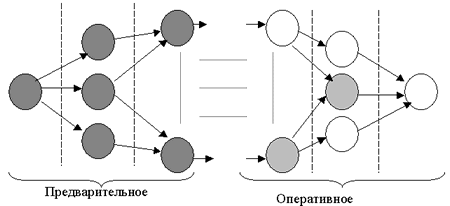
Процедура оперативного формування агрегатівБудемо розуміти під процедурою оперативного формування агрегатів процедуру одержання результуючого набору агрегатів при виконанні користувальницького запиту. При розрахунку результуючого набору агрегатів будуть використовуватися підходящі попередньо сформовані агреговані значення показників. Якщо результуючий набір агрегатів попередньо сформований, то витрати на оперативне формування агрегатів рівні 0. Ясно, що для одержання множини агрегатів певного рівня, необхідно спочатку одержати множини агрегатів більшого рівня деталізації. Однак на відміну від процедури попереднього формування агрегатів при одержанні результуючого набору немає необхідності формувати всілякі агрегати певного рівня деталізації. Досить формувати по одній множини певного рівня на основі множини більш детального рівня. Нехай у результаті процедури попередньо формування агрегатів одержали всілякі множини мінімального рівня деталізації l. Нехай у результаті необхідно сформувати множину агрегатів · вхідна множина агрегатів повинна задовольняти умові твердження 2. · вхідна множина агрегатів повинна забезпечувати мінімальні витрати на формування результуючої множини, тобто необхідно визначити найкоротший шлях у мережному графі до результуючої множини (рис.14).
Рис.14. Попереднє й оперативне формування агрегатів у мережній моделі
Така процедура оперативного формування забезпечить мінімальний час виконання користувальницьких запитів. Однак багато чого залежить від множини попередньо сформованих агрегатів. Вони повинні бути сформовані так, щоб обчислювальні витрати на оперативне формування всіляких множин були мінімальні.  Питання для самоперевірки 1. Поясніть, як розраховується кількість усіляких агрегатів для куба із простими вимірами. 2. Поясніть, як розраховується кількість усіляких агрегатів для куба з ієрархічними вимірами. 3. Як визначаються обчислювальні витрати на агрегування? 4. Які принципи використовуються під час виконання процедури попереднього формування агрегатів? 5. Назвіть особливості процедури оперативного формування агрегатів. Методичні вказівки до лекції:[9].
Вправи 1. Визначите міру й три виміри для куба із предметної області «Лікарня». Розрахуйте кількість усіляких агрегатів для випадку із простими вимірами. 2. Додайте ієрархію у виміри із вправи 1. Розрахуйте кількість усіляких агрегатів. 3. Розрахуйте обчислювальні витрати для агрегації по одному з вимірів для куба із вправи 2. 4. Намалюйте граф, що визначає шляхи формування агрегатів для куба із вправи 3.
Семестровий модуль 2 ЛЕКЦІЯ №9
Розглядаються наступні питання: · стадії процесу завантаження; · процес витягу даних і його підпроцеси; · методи прискорення процесу перевантаження даних.
Витяг, перетворення й завантаження, відомі під абревіатурою ETL (extraction, transformation, loading), – це основні етапи переносу інформації з одного застосування в інше. У загальному випадку ETL витягають інформацію з вхідної бази даних, перетворять її у формат, підтримуваний базою даних призначення, а потім завантажують у неї перетворену інформацію. Щоб витягти дані з вхідної бази даних, можна вибрати один із трьох варіантів – створити власні програми, звернутися до готового спеціалізованого інструментарію ETL або використовувати сполучення й того й іншого. Програміст ETL може уявляти собі архітектуру СД у вигляді сукупності трьох областей: джерело даних (сукупність таблиць оперативної системи й додаткових довідників (класифікаторів, таблиць узгодження), що дозволяє створити багатомірну модель даних з необхідними вимірами), проміжна область (сукупність таблиць, що використовуються винятково як проміжні при завантаженні СД) і приймач даних. Якщо зустрічаються джерела інформації, що надходить у різний час або з різних оперативних систем, але ідентичної за структурою, наприклад, однотипні відомості з різних філій, то такі джерела варто вважати не різними, а одним розподіленим. Витяг даних із всіх частин розподіленого джерела виконується в одну таблицю проміжної області. Для збереження інформації, звідки надійшли дані, у структуру цієї таблиці додається поле з позначенням вхідної оперативної системи або філії.
У свою чергу, процес витягу включає наступні підпроцеси: - вивантаження; - структурування; - обробка; - пересилання; - імпорт. Залежно від характеру джерела даних можуть використовуватися такі методи організації вивантаження даних: - із СКБД – звичайно не викликає утруднень, можна використовувати власні утиліти СКБД; - зі структурованого джерела – для вивантаження використовуються відповідні драйвера, наприклад, ODBC; може знадобитися попередня підготовка структурованого файлу людиною або сторонньою програмою; - з неструктурованого джерела - потрібні додаткові утиліти для експорту даних, у ході якого дані організуються у тверду структуру. Повинна бути також врахована глибина вибірки даних за часом. Як правило, це 2 режими роботи процедури вивантаження: вивантаження всієї інформації, без урахування часу її надходження, і вивантаження за деякий останній період (наприклад, за останній закритий день). Універсальним засобом рішення є можливість завдання, як параметр процедури, дати, починаючи з якої будуть вибиратися дані. Структуровані дані можуть зажадати додаткової обробки (очищення, фільтрації, узгодження, і т.д.) для підвищення якості інформації. В обробці даних можуть бути задіяні різні інструменти: від ручного виправлення текстового файлу аналітиком до утиліт, що застосовують просунуті методи аналізу даних (нейронні мережі, тезаурус, кластерізація й ін.). У ході проектування процедур витягу даних необхідно врахувати умови забезпечення безпеки при пересиланні й обробці даних. Дані джерела не завжди можуть бути оброблені на сервері постачальника даних. Тоді їх необхідно переслати для обробки на сервер консолідації даних, що також вимагає наявності захищених каналів зв'язку й адміністративних ресурсів. У цьому випадку, етап пересилання виконується раніше структурування даних. Для подальшої обробки, структуровані дані необхідно імпортувати у відповідну таблицю СКБД (яку потрібно попередньо очистити). При цьому існує ймовірність, що окремі записи не зможуть, у силу фізичних обмежень або несумісності типів даних, бути вставлені. По можливості, такі «невідповідні» записи потрібно зберігати в окремий файл тієї ж структури, що й імпортований, з метою подальшого аналізу й підвищення якості даних. Помилки можуть з'являтися в кожному з підпроцесів стадії витягу даних. Відстежити їхнє виникнення – завдання, що слабко формалізується. Крім того, найчастіше вся відповідальність за забезпечення коректної роботи процедур витягу даних покладається на програмістів, що може бути виправдано тільки для жорстко структурованих джерел даних (наприклад, коли завантаження виконується прямо із СКБД). Приклади фатальних помилок: - відсутність файлів джерела даних; - помилка доступу до даних; - виникнення системної помилки операційної системи.
Очищення даних полягає у фільтрації тих даних, які, у якому-небудь змісті, не задовольняють існуючим фізичним обмеженням або бізнес-правилам. Категорії критеріїв оцінки якості даних можна звести до наступних класів: 1) по критичності: - критичні помилки в даних (дані, які не відповідають цьому критерію, не можуть бути завантажені в CД), наприклад, числове вираження, що містить букву; - некритичні помилки в даних (дані, які можуть бути завантажені в CД, але не є якісними), наприклад, порожнє (NULL) значення в полі ім'я; - якісні дані. 2) по об’єктам, що перевіряються: - коректність форматів і представлень даних; - унікальність первинних і альтернативних ключів; - повнота даних; - повнота зв'язків; - відповідність даних аналітичним обмеженням. Фізична модель СД часто не збігається зі структурою оперативних джерел даних. Тому виникає потреба в перетворенні даних, які надходять із оперативних джерел у структури, що відповідають таблицям СД. Перетворення даних зводиться до декількох елементарних операцій: - обчислення; - агрегація; - узгодження ключів; - генерація сурогатних ключів. Обчислення – це операція, що може бути реалізована на рівні скалярних функцій. Узгодження ключів – операція приведення ідентифікаторів набору даних джерела до виду, що відповідає ідентифікаторам СД. Генерація сурогатних ключів – операція зіставлення природному ключу (найчастіше - складеному) унікального сурогатного ключа – ідентифікатора набору даних СД. Найчастіше застосовуються наступні способи: послідовна нумерація або кодування природного ключа (сурогатний ключ обчислюється із природного за допомогою деякої функції).
Розподіл даних на кілька потоків перед вставкою в СД потрібний для того, щоб розділити нові дані й записи, які повинні обновити або доповнити раніше інформацію, що надійшла, у СД. Завдяки цьому завантаження даних у СД проходить простими запитами, без додаткової фільтрації.
Процесперевантаження даних джерел у сховище даних, з технічної точки зору, є послідовністю SQL-запитів до СКБД над досить великими об’ємами даних (від 1 до 100 мегабайт за один сеанс). Тому, виконання неоптимізованих процесів перевантаження може на порядки збільшити час виконання за рахунок зайвих або повторних обробок або пересилань даних. Зокрема, можна врахувати наступні методи прискорення процесу: - наявність у таблиці індексів або представлень може сильно збільшити час вставки даних у цю таблицю – перед заповненням необхідно, по можливості, видалити всі індекси й представлення й створити їх заново після заповнення; - швидкість передачі даних по мережі набагато менше швидкості передачі даних усередині одного сервера СКБД – на етапі вивантаження даних із джерела варто застосувати всі можливі фільтри й процедури агрегації, щоб прискорити проходження даних по мережі; - застосування оператора distinct сильно сповільнює виконання запиту в деяких СКБД – замість оператора distinct використовувати group by, наприклад, замість оператора SELECT DISTINCT Ід_Товару FROM Продаж використовувати оператор SELECT Ід_Товару FROM Продаж group by Ід_Товару; - у деяких СКБД відсутній окрема операція очищення таблиці, яка не журналізується, а застосування оператора DELETE FROM може виконуватися повільно – можна застосувати парні операції видалення й наступного створення таблиці, при цьому прийдеться заново створити залежні об'єкти, наприклад, індекси. У процесах перевантаження даних є й інші вузькі місця, які можна оптимізувати. Це фаза очищення даних, етап генерації сурогатних ключів і фаза вставки даних у СД. Наприклад, один зі способів оптимізації очищення даних полягає в наступному. При очищенні даних виконується перевірка кожного запису на відповідність ряду заздалегідь обраних критеріїв і правил. Оскільки перевірка одних критеріїв може залежати від результатів перевірки інших (наприклад, перевірка обмеження на значення числа, що втримується в поле з типом даних char(10), залежить від перевірки, чи є вміст цього текстового поля числом), те рекомендується за результатами перевірки критеріїв з більш високим пріоритетом (у наведеному прикладі перевірка, чи є значення поля числом, має більш високий пріоритет) формувати проміжні (тимчасові) таблиці, які будуть потім перевірятися на відповідність іншим критеріям. У результаті запит на перевірку кожного наступного критерію буде обробляти все менший об’єм даних. Цей спосіб має й недоліки: відсутність виграшу при надходженні якісних даних, і навіть програш по швидкості за рахунок потреби в очищенні проміжних таблиць; збільшення числа об'єктів проміжної області; збільшення числа кроків. Для часткового усунення цього недоліку формування додаткових проміжних таблиць варто вводити тільки для перевірки критеріїв, що забирає значний час.
Одна із самих повільних операцій у СКБД - це операція відновлення UPDATE. Один з методів обійти використання UPDATE – заміна її на операції видалення й вставки. Можливі два варіанти заміни: 1) стандартний a) видалення із СД рядків, які підлягають відновленню; b) вставка всіх рядків з новими значеннями в СД; 2) оптимізований a) перенос рядків, які не підлягають відновленню, із СД у тимчасову таблицю з рядками, які підлягають відновленню; b) очищення всієї таблиці СД; c) вставка в СД всієї тимчасової таблиці. Подібна заміна буде ефективна при великій кількості обновлюваних полів таблиці СД (більше 10). Однак, ця заміна неможлива для випадків, коли обмеження посилальної цілісності створені фізично в базі даних. Для таких випадків UPDATE – єдиний спосіб відновлення даних. ETL-процес є вузьким місцем концепції сховищ даних для рішення багатьох задач. При побудові СД найбільші витрати, як правило, доводяться саме на етап ETL. Правильний підхід у реалізації процесів ETL дозволять істотно оптимізувати витрати при побудові сучасного аналітичного інформаційного комплексу й підвищити його ефективність.
Питання для самоперевірки 1. Що таке ETL? 2. Назвіть основні етапи витягу даних. 3. Які фатальні помилки можуть виникати на стадії витягу даних? 4. Назвіть критерії оцінки якості даних. 5. Які способи прискорення перевантаження даних у СД Ви знаєте? Методичні вказівки до лекції: [3, с. 345–348];[4, с. 886–888]; [5,с. 960–962]; [6, с. 83–91].
Вправи 1. Розробіть реляційну БД для обліку оперативної інформації в предметній області «Поліклініка». Розробіть для даної предметної області структуру реляційних таблиць для СД типу «зірка» із трьома вимірами. Напишіть оператори SQL для перенесення даних з оперативної БД у СД. 2. Виконайте вправу 1 для предметної області «Телефонна компанія». ЛЕКЦІЯ №10
Розглядаються наступні питання: · проблеми окремого джерела даних на рівні схеми; · проблеми окремого джерела даних на рівні елемента даних; · проблеми очищення даних з множини джерел.
Оскільки сховища даних завантажують і постійно обновляють величезні об’єми даних з різних джерел, імовірність влучення в них «брудних даних» досить висока. Більш того, СД використовуються для прийняття рішень, отже, щоб некоректні дані не привели до некоректних висновків, просто життєво необхідно проводити коректування таких даних. Наприклад, інформація, що дублюється, або втрачена може стати причиною некоректної або неадекватної статистики. Очищення даних звичайно виконується в окремій області підготовки даних до завантаження перетворених даних у СД. Існує багато засобів з різною функціональністю, призначених для підтримки подібних завдань, однак часто досить великий обсяг роботи з очищення й перетворення доводиться виконувати вручну або низькорівневими програмами, важкими для написання й використання. |
||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 423. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
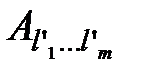 рівня деталізації l’, l’< l. Необхідно на підставі однієї з множин
рівня деталізації l’, l’< l. Необхідно на підставі однієї з множин 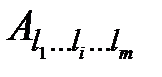 l-го рівня одержати результуючу множину. При цьому:
l-го рівня одержати результуючу множину. При цьому: