|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Достоїнства архітектури корпоративного сховища даних· несуперечність інформації; · один набір процесів витягу й бізнес-правил; · загальна семантика; · централізоване, кероване середовище; · легко створювані й наповнювані вітрини даних; · єдиний репозіторій метаданих; Недоліки такого архітектурного рішення СД · реалізація вимагає великих витрат; · висока ресурсоємність; · потреба в системах і ресурсах у масштабі всього підприємства; · ризикований сценарій («усе поставлено на карту»). Іноді архітектуру «зірка» називають підходом «зверху донизу», а шину вітрин даних - підходом «знизу нагору», тому що перша орієнтована на спочатку задану інфраструктуру й процеси, а шина вітрин даних – на розробку проекту, у якому вирішуються критичні бізнеси-завдання. Централізоване сховище даних (без залежних вітрин) Ця архітектура схожа на архітектуру «зірка» за винятком відсутності залежних вітрин даних. Сховище даних містить детальні дані, деяку кількість агрегованих даних і логічні представлення. Запити й застосування виконуються як на реляційних даних, так і на багатомірних представленнях. Федеративна архітектура У цій архітектурі використовуються вже існуючі структури підтримки прийняття рішень (операційні системи, вітрини й сховища даних). Дані витягають із перерахованих систем на основі бізнесів-вимог. Дані логічно або фізично інтегруються за допомогою метаданих, розподілених запитів і інших методів. Ця архітектура є практичним рішенням для компаній, які вже користуються аналітичними засобами й не хочуть від них відмовлятися. Достоїнства системи об'єднаних СД · загальна семантика й бізнес-правила;  · один набір процесів витягу й бізнес-правил; · децентралізовані ресурси й керування; · паралельна розробка. Недоліки такого архітектурного рішення · необхідність у координуванні робіт; · складності в подоланні «політичних» моментів і рішенні питань авторських прав; · потрібна погодженість серед різних відділів з питань архітектури, бізнес правил і семантики; · найскладніше технічне середовище; · дуже часта наявність численних репозіторіїв метаданих. Фактори, що впливають на вибір архітектури Відповідно до досліджень компанії TDWI, існує 10 основних факторів, що впливають на вибір архітектури. Раціональні фактори 1) Інформаційна залежність між організаційними підрозділами Високий рівень інформаційної залежності виникає в тих організаціях, де один підрозділ залежить від відомостей, що надходять із іншого. У цій ситуації можливість спільного використання й інтеграції інформації дуже важлива. 2) Інформаційні потреби керівництва Вищому керівництву часто потрібна інформація про більш низькі організаційні рівні. Іноді виникає потреба поглибитися в детальні дані й розібратися в діяльності конкретного підрозділу або переконатися, що компанія виконує необхідні нормативні вимоги. 3) Терміновість впровадження сховища даних 4) Характер користувальницьких задач Ряд користувачів виконує складні й нестандартні задачі. Для реалізації їхніх потреб недостатньо структурованих запитів і звітів. Їм необхідно аналізувати дані новими способами, а отже, мати в розпорядженні таку архітектуру, що дозволить аналізувати дані «на лету», нетривіальними методами. 5) Обмежені ресурси Деякі види сховищ даних вимагають більше ресурсів, ніж інші. У результаті на виборі архітектури може відбитися доступність IT-персоналу, бізнесів-співробітників і матеріальних засобів. 6) Стратегічне представлення сховища даних до впровадження Різні компанії мають різні плани застосування сховища даних. Іноді необхідно «точкове рішення» для конкретного підрозділу, а іноді – інфраструктура підтримки прийняття рішень, що містить множину застосувань. 7) Сумісність із існуючими системами 8) Можливості персоналу Впровадження деяких архітектур уважається більш складним залежно від навичок і досвіду технічного персоналу, наявності позитивного досвіду в аналогічних проектах і від рівня конфіденційності. Технічні фактори Вибір на користь тієї або іншої архітектури робиться залежно від важливості наступних технічних питань. 1) можливість інтеграції метаданих; 2) масштабованість користувачів; 3) обсяги даних; 4) ефективність запитів; 5) можливість підтримки історичних даних; 6) адаптація до змін (наприклад, у вихідних системах). Соціальні фактори Один із соціальних факторів – вплив експертів. Ухвалення рішення – це процес переговорів, створення коаліцій, де відіграє роль множина амбіційних цілей. Не можна сказати, що в кожної компанії є одне єдине завдання, що впливає на вибір архітектури. Для оптимізації й балансу цілей, а отже, і для вибору архітектури необхідно вдаватися до допомоги експертів. Іноді в ролі експертів виступають консультанти, іноді власні користувачі. У деяких випадках інформація черпається на семінарах, конференціях і інших заходах. Кожний із цих факторів до деякої міри впливає на вибір архітектури. Дуже часто цей суб'єктивний вплив, пов'язане з особистим успішним досвідом фахівця. У результаті досліджень і опитувань, проведених TDWI, було з'ясовано, що всі перераховані вище фактори (що ставляться до кожної із трьох груп) мають своє значення. Найважливіші фактори – взаємозалежність між організаційними підрозділами, стратегічне представлення про сховище даних до його впровадження й інформаційні потреби вищого керівництва. Можливості технічного персоналу – на останнім місці, однак вони мають певну вагу й грають далеко не найменшу роль.
Один із практичних фахівців в області впровадження BI Брайан Шварбрик (Brian Swarbrick) назвав питання, які необхідно розглянути при виборі кращої архітектури BI-рішення. 1. Чи продуманий і чи заданий масштаб проекту? Чи будується рішення для підтримки вимог відділу або як фундамент корпоративного проекту, якому необхідно поступово розширювати для підтримки майбутніх вимог і інших підрозділів? Якщо завдання обмежується одним відділом, то архітектура може бути простіше. Однак якщо передбачається довгострокове рішення, то підхід необхідно ретельно продумати. При виборі повинні враховуватися як архітектурні аспекти, так і погодженість із організаційними й IT-стратегіями й майбутніми планами. 2. Чи важливо відокремити компоненти інтеграції даних від аналітичних компонентів і чому? (Мова йде про корпоративні рішення як для короткострокових, так і для довгострокових завдань). Вхідні дані можуть надходити як зсередини організації, так і ззовні. Дані можуть уже існувати або з'явитися завтра, або надійти у віддаленому майбутньому. Правила інтеграції даних можуть бути складними. Крім того, необхідно враховувати вимоги до звітності. Зокрема, одним зі шляхів є поділ і моделювання шарів даних і шарів звітності. У результаті забезпечується гнучкість і облік постійно додаваних й змінюваних бізнесів-вимог. 3. Організаційний інтерес до якості даних. Якщо якість даних не грає принципової ролі, а звітні вимоги виходять від підрозділів (а не від компанії в цілому), то найкраще вибрати найпростіше звітне програмне забезпечення. Якщо ж завдання підвищення якості даних стоїть гостро, то краще вибрати рішення, описане в пункті 2. Розробка архітектурного шару, орієнтованого на збір і інтеграцію даних, має на увазі подальше розширення й впровадження підтримки якості. Така архітектура дозволяє підвищувати якість даних, а також звітності й аналітичних операцій. 4. Гнучкість для майбутнього росту. Часто збір і інтеграція даних, а також вітрини даних будуються на одній базі. Підготовчі шари звичайно тимчасові й використовуються для підтримки поточних вимог до звітності (заданих ще до початку проекту). У міру зміни вимог і надходження нових, вітрини даних розширюються. Але часто такі проекти не вдається розширити до корпоративних масштабів без істотної переробки. Якщо відповідно до нових вимог необхідні дані, недоступні у вітрині даних або доступні в іншому форматі, то вітрина даних втрачає зміст. Вітрини даних гарні для підтримки відомих бізнес-вимог, але при цьому недостатньо гнучкі при їхній зміні. 5. Бюджет. Корпоративні проекти бувають дорогими. Звичайно вони містять множину компонентів, і не завжди є час на розробку «одноразових» вітрин даних для підрозділів. Час на підтримку й розробку збільшується. Однак якщо грамотно продумати архітектуру, то проект можна виконати досить швидко. Кращим є ітеративний підхід, заснований на структурованій архітектурі й методології, що дозволяє швидко створювати корпоративну інфраструктуру й забезпечувати користь для бізнесу на кожному з етапів процесу. 6. Проект буває успішним лише тоді, коли в ньому використовуються необхідні ресурси й навички. Організація повинна забезпечити матеріальні можливості й кадри. Для локальних (усередині відділу) проектів зусиль буде потрібно менше. Успіх архітектур На думку TDWI, архітектурою, що домінує, є зірка, за нею йде шина вітрин даних і централізована архітектура, і лише невеликий відсоток проектів заснований на незалежних вітринах даних і федеративній архітектурі. Централізоване сховище даних частіше вибирають, коли впровадження потрібно провести терміново, обмеженість ресурсів вище й більше розрахунку на власний персонал. Архітектура «зірка» найчастіше використовується в корпоративних проектах для створення великих сховищ даних. Це самі довгострокові й дорогі проекти, однак і самі результативні. Функціональне охоплення таких проектів ширше, і розмір сховища даних більше. Ця архітектура вимагає більшого утягування керівництва й планування, а отже, матеріальних і часових ресурсів. Шина вітрин часто вибирається в тій ситуації, коли ресурсів цілком достатньо, представлення про сховище даних не носить чіткої стратегічної орієнтації, і сумісність із уже впровадженими засобами не грає принципової ролі. Лише деякі компанії вибирають федеративну архітектуру, зокрема, ті, хто обмежений по строках. У деяких організацій уже використовуються розрізнені платформи прийняття рішень у результаті злиттів і поглинань. Тому вони й застосовують федеративний підхід, найбільше швидко реалізований. Тут більшу роль грає фактор інформаційної залежності між підрозділами компанії й інформаційних потреб керівництва Незалежні вітрини даних мають найнижчі оцінки серед користувачів. Це зайвий раз підтверджує загальновідомий факт: ця архітектура далеко не найкраща. Якщо говорити про інформаційну й системну якість, а також про організаційний вплив, то про домінування однієї конкретної архітектури мова не йде. Вони розвиваються й згодом здобувають близькі риси. Наприклад, архітектура «зірка» часто включає вітрини даних, що лежать в основі архітектури «шина».
Крім фізичних СД, використовуються й віртуальні сховища даних. У такій системі дані з OLTP-системи не копіюються в єдине сховище. Вони витягають, перетворяться й інтегруються безпосередньо при виконанні аналітичних запитів у режимі реального часу. Фактично такі запити прямо передаються до OLTP-системи. В основі віртуального СД – репозіторій метаданих, які описують джерела інформації (БД транзакційних систем, зовнішні файли й ін.), SQL-запити для їхнього зчитування й процедури обробки й надання інформації. У цьому випадку надмірність даних нульова. Кінцеві користувачі фактично працюють із транзакційними системами прямо з усіма плюсами, що випливають звідси (доступ до «живого» даним у реальному часі) і мінусами (інтенсивний мережний трафік, необхідність постійної доступності всіх OLTP-джерел, зниження продуктивності OLTP-систем і реальна погроза їхньої працездатності внаслідок невдалих дій користувачів-аналітиків).
Питання для самоперевірки 1. Опишіть особливості архітектури «зірка». 2. У чому відмінність між архітектурами з незалежними вітринами даних і шиною вітрин даних? 3. Перелічіть раціональні фактори, що впливають на вибір архітектури СД. 4. Що важливо врахувати при виборі архітектури СД? 5. Чому архітектура «зірка» є домінуючою при розробці СД? 6. Чим віртуальне СД відрізняється від фізичного? Методичні вказівки до лекції:[2, с. 26–31]; [4, с. 889–896]; [5, с. 951]; [8, с. 33–34].
Вправи 1. Проаналізуйте, яку архітектуру краще вибрати для реалізації аналітичної системи діяльності ВЗН. 2. Дайте опис варіантів різних архітектур для предметної області «Медицина» (що могло б знаходиться в СД і у вітринах даних для кожної архітектури). Змістовний модуль 3 Лекція №5
Розглядаються наступні питання: · поняття багатомірного простору; · гіперкубічна й полікубічна моделі; · типи фактів.
Багатомірне моделювання є методом моделювання й візуалізації даних як множини числових показників або параметрів (measures), які описують загальні аспекти діяльності організації. Як правило, при багатомірному моделюванні основна увага фокусується на числових даних, таких як число продажів, баланс, прибуток, вага, або на об'єктах, які можна перерахувати, таких як статті, патенти, книги. Метод багатомірного моделювання базується на наступних основних поняттях: факти, атрибути, виміри, міри, ієрархія. Факт (fact) – це набір зв'язаних елементів даних, що містять міри й описові дані. Кожен факт звичайно представляє елемент даних, що чисельно описує діяльність організації, бізнес-операцію або подію, що може бути використане для аналізу діяльності організації або бізнес-процесів. Атрибут (Аttrіbute) - це опис характеристики реального об'єкта предметної області. Як правило, атрибут містить заздалегідь відоме значення, що характеризує факт. Звичайно атрибути представляються текстовими полями з дискретними значеннями. Наприклад, габарити впакування товару, запах товару. Вимір (dіmensіon) - це інтерпретація факту з деякого погляду в реальному світі. Виміри, подібно атрибутам, містять текстові значення, які сильно зв'язані за змістом між собою. Звичайно виміри представляються як осі багатомірного простору, крапками якого є пов'язані з ними факти. У багатомірній моделі кожен факт пов'язаний з однієї або декількома осями. Виміри звичайно представляють нечислові, лінгвістичні змінні, такі як філії організації, співробітники організації, покупці й т.д. Наприклад, при аналізі продажів продукції, виробленою або продаваною організацією, такими вимірами звичайно вступають час, покупці, продавці, місце продажу або складування товару. Виміри задаються перерахуванням своїх елементів (members). Елемент виміру (dіmensіonal member) - унікальне ім'я, використовуване для визначення позиції елемента. Наприклад, вимір «Час» може містити наступні елементи: «всі місяці», «квартали», «роки». Часто елементи виміру перебувають у відношенні «частина-ціле» або «батько-нащадок», що дозволяє ввести на вимірі одну або кілька ієрархій. Кожна ієрархія може мати кілька рівнів ієрархії (hіerarchy levels). Кожен елемент виміру повинен належати тільки одному рівню ієрархії, породжуючи в такий спосіб розбивка на непересічні підмножини. Прикладом може служити ієрархія на вимірі «Час»: рік, півріччя, квартал, місяць й день. Міра (параметр, метрика або показник) (measure) – це числова характеристика факту, що визначає ефективність діяльності або бізнес-дії організації з погляду виміру. Конкретні значення міри описуються за допомогою змінних. Наприклад, нехай мірою є чисельне вираження продажів товару в грошах, кількість проданих одиниць товару й т.д. Міра визначається за допомогою комбінації елементів вимірів й, таким чином, представляє факт. Багатомірна модель візуально представляється за допомогою куба (або у випадку більше трьох вимірів – гіперкуба). Куб OLAP – це структура, у якій зберігаються сукупності даних, отримані з бази даних OLAP шляхом всіх можливих сполучень вимірів з фактами. Багатомірний простір даних може мати будь-яку кількість вимірів. Такий простір дискретний й містить дискретну кількість значень на кожному вимірі. Розмірність простору математично визначається перемножуванням розмірів всіх вимірів. Оскільки кожний вимір дискретний, той простір є обмеженим (кінцевим). Виміри представлені осями куба, по яких відкладають значення, що відносяться до аналізованої предметної області, наприклад, назви товарів і назви місяців року. Такі значення, що «відкладаються» уздовж вимірів, називаються Членами або Мітками (members). Рис.2. Елементи багатомірного куба
На відміну від лінійних просторів багатомірні моделі, як правило, не передбачають функцій упорядкування або відстані для значень виміру. Єдине «упорядкування» полягає в тому, що значення більш високого рівня містять значення більш низьких рівнів. Однак для деяких вимірів, таких як час, упорядкованість значень розмірності може використовуватися для обчислення сукупної інформації, такої як загальний обсяг продажів за певний період. У різних БСКБД використовуються два основних варіанти організації даних: гіперкубічна модель і полікубічна модель. У другому випадку припускають, що в ББД може бути визначено кілька гіперкубів з різною розмірністю й з різними вимірами в якості їхніх граней. У полікубічній моделі в цьому випадку може бути оголошено два різних гіперкуби: · двомірний – для показника Робочий Час Менеджера, визначається Днем і Менеджером; · тривимірний – для показника Обсяг Продажів визначається Моделлю комп'ютера, Днем і Менеджером. У випадку ж гіперкубічної моделі передбачається, що всі показники повинні визначатися тим самим набором вимірів. Тобто тільки через те, що Обсяг Продажів визначається трьома вимірами, при описі Показника Робочий Час Менеджера доведеться також використовувати три виміри й уводити надлишкове для цього показника вимір Модель Комп'ютера. На перетинанні осей вимірів в комірках розташовуються дані, що кількісно характеризують аналізовані факти. Комірки куба можуть бути порожні або повні. Коли значне число комірок куба не містить даних, говорять, що він «розріджений». Цілком звичайні такі набори даних, які містять 1%, 0.01% і навіть меншу частку можливих даних. Кожний факт є сукупність однієї або декількох мер. Наприклад, окремий факт виготовлення містить у собі сукупність як мінімум трьох величин – вартість заготівки, вартість виготовлення й різні нарахування. Найбільше часто зустрічаються наступні 4 типи фактів: 1) факти, пов'язані із транзакціями (Transaction facts). Вони засновані на окремих подіях (типовими прикладами яких є телефонний дзвінок або зняття грошей з рахунку за допомогою банкомату); 2) факти, пов'язані з «моментальними знімками» (Snapshot facts). Засновані на стані об'єкта (наприклад, банківського рахунку) у певні моменти часу, наприклад на кінець дня або місяця. Типовими прикладами таких фактів є обсяг продажів за день або денний виторг; 3) факти, пов'язані з елементами документа (Line-item facts). Засновані на тім або іншому документі (наприклад, рахунку за товар або послуги) і містять докладну інформацію про елементи цього документа (наприклад, кількість, ціну, відсоток знижки); 4) факти, пов'язані з подіями або станом об'єкта (Event or state facts). Представляють виникнення події без подробиць про нього (наприклад, просто факт продажу або факт відсутності такого без інших подробиць). Таблиця фактів є основною таблицею сховища даних. Вона, як правило, містить унікальний складений ключ, що поєднує первинні ключі таблиць вимірів. Найчастіше це цілочислені значення або значення типу «дата/час» – адже таблиця фактів може містити сотні тисяч або навіть мільйони записів, і зберігати в ній повторювані текстові описи, як правило, невигідно – краще помістити їх у менші по обсягу таблиці вимірів. При цьому як ключові, так і деякі неключові поля повинні відповідати майбутнім вимірам OLAP-Куба. Крім цього таблиця фактів містить одне або кілька числових полів, на підставі яких надалі будуть отримані агрегатні дані. Як правило, у фактах немає надмірності, вона є тільки у вимірах. Куб OLAP також може розглядатися як багатомірний масив даних, як правило, розріджений і довгочасно збережений. Може бути реалізований на основі універсальних реляційних СУБД або спеціалізованим програмним забезпеченням. Індексам масиву відповідають виміри (dіmensіons) або осі куба, а значенням елементів масиву – міри (measures) куба. На відміну від звичайного масиву в мові програмування, доступ до елементів OLAP-куба може здійснюватися як по повному наборі індексів-вимірів, так і по їхній підмножині. Тоді результатом буде не один елемент, а їхня безліч, що є аргументом для агрегуючої функції.
Питання для самоперевірки 1. Назвіть основні компоненти кубу. 2. Як визначається розмірність кубу? 3. Як звичайно виглядає структура таблиці фактів? 4. Які типи фактів Ви знаєте? Методичні вказівки до лекції:[2, с. 40–44] ; [3, с. 80-86]; [5, с. 971–976, 984]; [8,с. 30–32].
Вправи 1. Наведіть приклади вимірів для предметної області «Деканат». 2. Наведіть приклади мір для предметної області «Телефонна компанія». 3. Надайте структуру таблиці фактів для предметної області «Поліклініка». Лекція №6
Розглядаються наступні питання: · класи параметрів; · ієрархії вимірів; · схеми «зірка» і «сніжинка»; · операції, виконувані над гіперкубом.
Параметри складаються із двох компонентів: - чисельна характеристика факту, наприклад, ціна або доход від продажів; - формула, звичайно проста агрегативна функція, наприклад, сума, що може поєднувати кілька значень параметрів в одне. Параметри, як правило, представляють властивості факту, який користувач хоче вивчити. Параметри приймають різні значення для різних комбінацій вимірів. Чисельна характеристика і формула вибираються таким чином, щоб представляти осмислену величину для всіх комбінацій рівнів агрегування. Можна визначити три різних класи параметрів за поводженням при обчисленнях. Аддитивні параметри можуть змістовним образом комбінуватися в будь-якому вимірі. Наприклад, має сенс підсумувати загальний обсяг продажів для продукту, місця розташування й часу, оскільки це не викликає накладення серед явищ реального миру, які генерують кожне із цих значень. Напіваддитивні параметри, які не можуть комбінуватися в одному або декількох вимірах. Наприклад, підсумовування запасів по різних товарах і складам має сенс, але підсумовування запасів товарів у різний час безглуздо, оскільки той самий фізичний предмет може враховуватися кілька разів. Неаддитивні параметри не комбінуються в будь-якому вимірі, зазвичай тому, що обрана формула не дозволяє, наприклад, об'єднати середні значення низького рівня в середнім значенні більше високого з. Аддитивні й неаддитивні параметри можуть описувати факти будь-якого роду, у той час як напіваддитивні параметри, як правило, використаються з миттєвими знімками або сукупними миттєвими знімками. Виміри організуються в ієрархію, що складається з декількох рівнів, кожний з яких представляє рівень деталізації, необхідний для відповідного аналізу. Об'єкти у вимірах можуть бути різного типу, наприклад «виробники» - «марки автомобіля» або «роки» - «квартали». Існують наступні типи ієрархій: - збалансовані (balanced); - незбалансовані (unbalanced); - нерівні (ragged).
Збалансована ієрархія – ієрархія, у якій число рівнів визначене її структурою й незмінно, і кожна галузь ієрархічного дерева містить об'єкти кожного з рівнів.
Для формування збалансованої ієрархії необхідна наявність зв'язку «один-до-багатьох» між об'єктами менш детального рівня стосовно об'єктів більш детального рівня. У принципі кожний рівень збалансованої ієрархії можна представити як окремий простий вимір, але тоді ці виміри виявляться залежними, а виходить, неминуче підвищення розрідженості куба. Незбалансована ієрархія – ієрархія, у якій число рівнів може бути змінено, і кожна галузь ієрархічного дерева може містити об'єкти, що належать не всім рівням, тільки декільком першим.
Типовий приклад незбалансованої ієрархії – ієрархія типу «начальник-підлеглий», де всі об'єкти мають той самий тип –«Співробітник».
Нерівна ієрархія - ієрархія, у якій число рівнів визначене її структурою й постійно, однак на відміну від збалансованої ієрархії деякі гілки ієрархічного дерева можуть не містити об'єкти якого-небудь рівня.
Типовим прикладом є географічна ієрархія, у якій є рівні «Країни», «Штати» і «Міста», але при цьому в наборі даних є країни, що не мають штатів або регіонів між рівнями «Країни» і «Міста».
|
|||||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 556. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
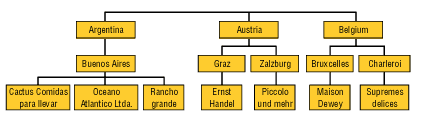 Рис.3. Приклад збалансованої ієрархії
Рис.3. Приклад збалансованої ієрархії
 Рис.4. Приклад незбалансованої ієрархії
Рис.4. Приклад незбалансованої ієрархії
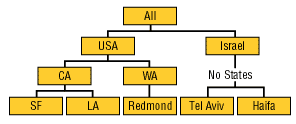 Рис.5. Приклад нерівної ієрархії
Рис.5. Приклад нерівної ієрархії