|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
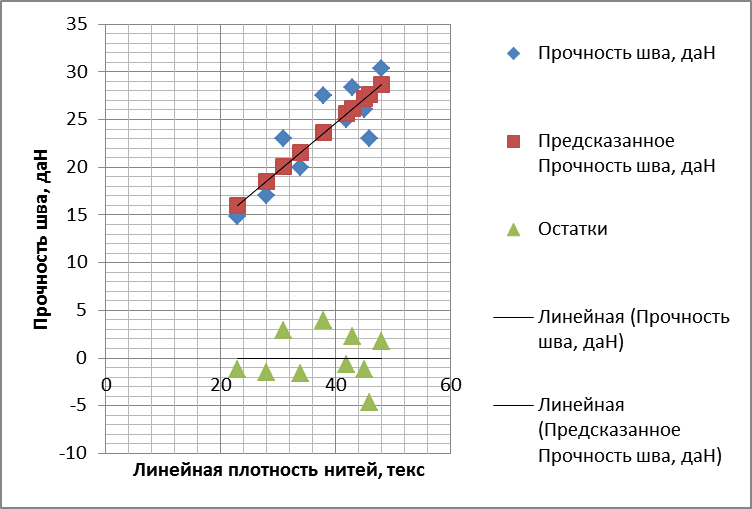
Построение уравнения и линии регрессииЗначит, уравнение регрессии будет иметь вид: y = a1 x + a0 = 0,50656x + 4,36215. Наверное, для полноты информации о рассматриваемом процессе следует начать с построения на графике опытных точек (xi, yi) по данным, полученным в замерах (Табл.1.1). Далее на этом же графике по расчетным точкам (xi, ŷi) следует построить линию регрессии. Линия регрессии, как уже было указано ранее, является графическим отображением уравнения регрессии. Для построения её нужно правильно выбрать масштабы по осям, чтобы обеспечить наглядность представления исследуемой зависимости.
Рисунок 1.3 – Объединённый график опытных данных, регрессионной зависимости (линия регрессии) и остатков
Выводы по работе В выводах должен быть описан вид полученного уравнения регрессии и характер связи между выходными и входными параметрами, оценена адекватность полученного уравнения и точность коэффициентов. Например: В лабораторной работе №1 была исследована зависимость прочности шва от линейной плотности ниток. Выявлено, что между этими параметрами существует устойчивая прямая положительная линейная взаимосвязь, описываемая коэффициентом корреляции rxy = 0,85331 и уравнением регрессии вида y = a1x + a0 = 0,50656x + 4,36215. То есть, с увеличением плотности ниток пропорционально (a1 = 0,50656) нарастает прочность шва (чего, впрочем, и следовало ожидать). Графически это представлено на рис. 1.3.
Эту же задачу можно решить с помощью инструмента "Анализ данных" программы MSExcel. Решение задачи Ввести исходные данные в MS Excel. Определить коэффициент корреляции rxy. Открыть меню «Сервис», выдать команду «Анализ данных…».  В окне «Анализ данных» среди Инструментов анализа выбрать «Корреляция» – ОК. В окне «Корреляция» курсор должен быть установлен в окошке «Входной интервал». В таблице исходных данных выделить все столбцы и строки (от наименований Х и Y до 16-й строки). – В окошке «Входной интервал» появится запись «$B$2:$C$17». Проверить указатель «Группирование: ◙ по столбцам». Установить указатель √ «Метки в первой строке». На новом листе появится таблица коэффициентов корреляции исследуемых случайных величин:
Определить коэффициенты регрессионной модели ŷ = a1x + a0 и оценить их достоверность. Открыть меню «Сервис», выдать команду «Анализ данных…». В окне «Анализ данных» среди Инструментов анализа выбрать «Регрессия» – ОК. В окне «Регрессия» курсор должен быть установлен в окошке «Входной интервал У». В таблице исходных данных выделить все значения переменной У (от наименования Y до 12-й строки). – В окошке «Входной интервал Y» появится запись «$С$2:$C$12». Аналогично ввести входной интервал для переменной Х. Установить указатель √ «Метки» и «Уровень надежности 95%». На новом листе появятся таблицы 3.3 и 3.4 «ВЫВОД ИТОГОВ» и : «РЕЗУЛЬТАТЫ ВЫЧИСЛЕНИЙ»: Таблица 3.3. Результаты вычислений
Таблица 3.4. Результаты вычислений
Таким образом, уравнение регрессии будет иметь вид: ŷ = ax + b = 0,506557×х + 4,36215. Но свободный член (У-пересечение) имеет низкую достоверность (высокую вероятность ошибки р-значение = 0,33246), следовательно, его лучше не включать в регрессионную модель: ŷ = ax = 0,506557×х.
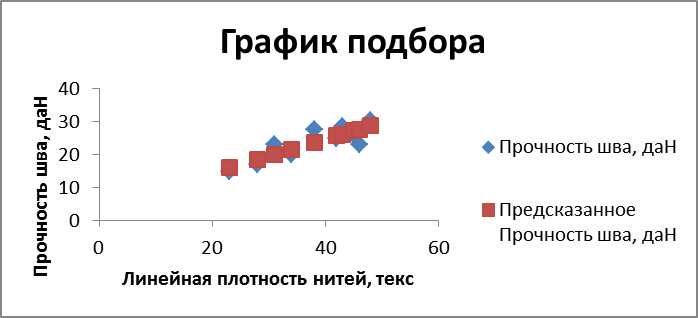
Описанные выше операции можно проделать с использованием пакета прикладных программ Statistica 6.0. Подготовить в пакете MSExcel исходные данные для анализа. Запустить ППП Statistica. В окне «STATISTICA»открыть меню «Файл» и выдать команду «Open …» или на панели «Стандартная» нажать кнопку «Openanexistingdocument». В окне «Open» указать нужную папку, тип файлов «DataFiles», файл с исходными данными задачи и выдать команду «Открыть». В окне «Открытие файла: Зад_3.xls» выбрать файл исходных данных задачи и нажать кнопку «Импорт выбранных страниц таблицы». В окне «SelectSheettoImport» выделить нужный лист книги MicrosoftExcel (как правило, это Лист1) – OK. В окне «Открытие файла Excel» проверить диапазон вводимых исходных данных и установить указатели √ «Получить имена регистра от первого столбца» и √ «Получить имена переменной от первой строки» - OK. Определить числовые характеристики переменных в каждой группе. В окне«STATISTICA» открыть меню «Статистика» и выдать команду «Основная статистика / Таблицы». Вокне«Basic Statistics and Tables»выбрать « Descriptive Statistics» –ОК. В окне«Select Variables (…)» выбрать все переменные Х, Y (или нажать кнопку «SelectAll») – OK. В окне «Descriptive Statistics» перейти на вкладку «Advanced» и выбрать требуемые числовые характеристики всех СВ (установить указатели √), нажать кнопку «SummaryDescriptivestatistics». В окне «Workbook Descriptive Statistics» просмотреть и оценить числовые характеристики всех СВ, затем нажать кнопку «Descriptive Statistics …» на панели внизу. Определить коэффициент корреляции rxy. Вокне«DescriptiveStatistics»нажатькнопку «Cancel». Вокне«Basic Statistics and Tables»выбрать «Correlation Matrices» –ОК. Вокне «Product Moment & Partial Correlations» нажатькнопку «Summery: Correlation Matrix». Вокне «Workbook: Correlations» просмотретькорреляционнуюматрицудляисследуемыхпеременных, затемнажатькнопку «Product Moment & Partial Correlations» напанеливнизу. Определить коэффициенты регрессионной модели ŷ = a1x + a0 и оценить их достоверность можно следующим образом: В окне«STATISTICA 6.0» открыть меню «Статистика» и выдать команду «Множественная статистика». Вокне«MultipleLinearRegression»нажатькнопку «Variables» ивокне«Selectdependentandindependentvariablelist»выбратьзависимуюпеременнуюУ и независимую Х – ОК. Вокне«MultipleLinearRegression»нажатькнопкуOK. Вокне«MultipleRegressionResults»нажатькнопку « Summary: RegressionResults». Вокне «Workbook: RegressionSummaryforDependentVariable» встолбцеВнайтизначениякоэффициентовуравнениярегрессии, затемнажатькнопку «MultipleRegressionResults « напанеливнизу. Вокне «Multiple Regression Results» нажатькнопку «Residual Analysis». Вокне «Residual Analysis» перейтинавкладку «Scatterplots» нажатькнопку «Predicted vs. Observed» – появитсяграфикисходныхданныхилиниирегрессии (см. выше).
Описанные выше операции можно проделать с использованием пакета прикладных программ Statistica 8.0. Подготовить исходные данные для анализа. Запустить ППП Statistica. В окне «STATISTICA»открыть меню «Файл» и выдать команду «Open …» или на панели «Стандартная» нажать кнопку «Openanexistingdocument». В окне «Open» указать нужную папку, тип файлов «DataFiles», файл с исходными данными задачи и выдать команду «Open». В окне «Открытие файла: Зад_4.xls» выбрать файл исходных данных задачи и нажать кнопку «ImportselectedsheettoaSpreadsheet». В окне «SelectSheettoImport» выделить нужный лист книги MicrosoftExcel (как правило, это Лист1) – OK. В окне «Открытие файла Excel» проверить диапазоны вводимых исходных данных и установить указатели √ «Getcasenamesfromfirstcolumn» и √ «Getvariablenamesfromfirstrow» – OK (цв.вклейки 3.9, 3.10). Определить числовые характеристики переменных в каждой группе. Вокне«STATISTICA»открытьменю «Statistics» ивыдатькоманду «MultipleRegression». Вокне«MultipleLinearRegression»нажатькнопку «Variables». Вокне«Selectdependentandindependentvariableslists»выбратьзависимуюпеременнуюY и все переменные Х, (или нажать кнопку «SelectAll») – OK (цв.вклейка 3.11). В окне «Descriptive Statistics» перейти на вкладку «Advanced» и выбрать требуемые числовые характеристики всех СВ (установить указатели √), нажать кнопку «SummaryDescriptivestatistics». В окне «Workbook Descriptive Statistics» просмотреть и оценить числовые характеристики всех СВ, затем нажать кнопку «Descriptive Statistics …» на панели внизу. Определить коэффициент корреляции rxy. В окне «DescriptiveStatistics» нажать кнопку «Cancel». Вокне«Basic Statistics and Tables»выбрать «Correlation Matrices» – ОК. Вокне «Product Moment & Partial Correlations» нажатькнопку «Summery: Correlation Matrix». Вокне «Workbook: Correlations» просмотретькорреляционнуюматрицудляисследуемыхпеременных, затемнажатькнопку «Product Moment & Partial Correlations» напанеливнизу (цв.вклейка 3.12). Определить коэффициенты регрессионной модели ŷ = a1x1 + a2x2 + a3x3 + a4x4 + a5x5 + a0 и оценить их достоверность можно следующим образом. Вокне«STATISTICA 8.0»открытьменю «Statistics» ивыдатькоманду «MultipleRegression». Вокне«MultipleLinearRegression»нажатькнопку «Variables» ивокне«Selectdependentandindependentvariablelist»выбратьзависимуюпеременнуюYинезависимуюХ – ОК. Вокне«MultipleLinearRegression»нажатькнопкуOK. Вокне«MultipleRegressionResults»навкладке «Quick»нажатькнопку «Summary: RegressionResults» (цв.вклейка 3.13).
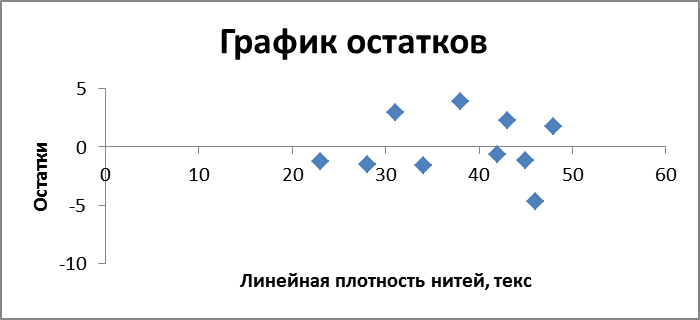
Дисперсионный анализ модели (критерий Фишера F = 21,42642, коэффициент детерминации R2 = 0,728135) показывает, что её можно считать значимой и достоверной. Вокне «Multiple Regression Results» нажатькнопку «Perform residual analysis» (цв.вклейка 3.15). В окне «ResidualAnalysis» перейти на вкладку «Quick», нажать кнопку «Summary: Residuals&Predicted» – появится таблица с исходными данными и значениями функции, рассчитанными по уравнению регрессии (см. выше) Здесь же (т.е. в ППП Statistica 8.0) можно получить дать прогноз параметра Y для заданных значений фактораX. Вокне«MultipleRegressionResults»нажатькнопку «Predictdependentvariable» В окне «Specify values for indep. vars» ввести значения переменнойХи нажать – ОК. В окне «Predicting values for…» в столбце «B-Weight*Value» получим ответ, там же приведены границы 95%-го доверительного интервала для этой величины (цв.вклейка 3.17). |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 317. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||