|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Меры по защите ЭВМ от заражения вирусами§ Оснащение ЭВМ современными антивирусными программами и регулярное обновление их версий. § Установка программы-фильтра при работе в глобальной сети. § Проверка дискеты на наличие вирусов перед считыванием с дискет информации, записанной на других ЭВМ. § При переносе на свой ПК файлов в архивированном виде проверка их сразу после разархивации. § Защита своих дискет от записи при работе на других ПК. § Создание архивных копий ценной информации на других носителях информации. § Не оставлять дискету в дисководе при включении или перезагрузки ПК, т.к. возможно заражение загрузочными вирусами. Наличие аварийной загрузочной дискеты, с которой можно будет загрузиться, если система откажется сделать это обычным образом. § При установке большого программного продукта вначале проверить все дистрибутивные файлы, а после инсталляции продукта повторно произвести контроль наличия вирусов. 30. Архивация информации – это такое преобразование информации, при котором объем информации уменьшается, а количество информации остается прежним. Методы сжатия данных В таблице 1 показаны два разных способа распределения алгоритмов сжатия по категориям. К категории (а) относятся методы, определяемые как процедуры сжатия без потерь и с потерями. При использовании метода сжатия без потерь восстановленные данные идентичны исходным. Этот метод применяется для обработки многих типов данных, например для исполняемого кода, текстовых файлов, табличных данных и т.д. При этом не допускается потеря ни одного бита информации. В то же время файлы данных, представляющие изображения и другие полученные сигналы, нет необходимости хранить и передавать без потерь. Любой электрический сигнал содержитшум. Если изменения в этих сигналах схожи с небольшим количеством дополнительного шума, вреда не наносится. Алгоритм, применение которого приводит к некоторому ухудшение параметров сигнала, называется сжатием с потерями. Методы сжатия с потерями намного эффективнее методов кодирования без потерь. Чем выше коэффициент сжатия, тем больше шума добавляется в данные. 
Алгоритм RLE В основе алгоритма RLE лежит идея выявления повторяющихся последовательностей данных и замены их более простой структурой, в которой указывается код данных и коэффициент повторения. Например, пусть задана такая последовательность данных, что подлежит сжатию: 1 1 1 1 2 2 3 4 4 4 В алгоритме RLE предлагается заменить ее следующей структурой: 1 4 2 2 3 1 4 3, где первое число каждой пары чисел - это код данных, а второе - коэффициент повторения. Если для хранения каждого элемента данных входной последовательности отводится 1 байт, то вся последовательность будет занимать 10 байт памяти, тогда как выходная последовательность (сжатый вариант) будет занимать 8 байт памяти. Коэффициент сжатия, характеризующий степень сжатия, можно вычислить по формуле:
где Vx- объем памяти, необходимый для хранения выходной (результирующей) последовательности данных, Vn- входной последовательности данных. Чем меньше значение коэффициента сжатия, тем эффективней метод сжатия. Понятно, что алгоритм RLE будет давать лучший эффект сжатия при большей длине повторяющейся последовательности данных. В случае рассмотренного выше примера, если входная последовательность будет иметь такой вид: 1 1 1 1 1 1 3 4 4 4, то коэффициент сжатия будет равен 60%. В связи с этим большая эффективность алгоритма RLE достигается при сжатии графических данных (в особенности для однотонных изображений). Алгоритмы группы KWE В основе алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике, на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь. Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW). Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает работу с почти пустым словарем, который содержит только одну закодированную строку, так называемая NULL-строка. При считывании очередного символа входной последовательности данных, он прибавляется к текущей строке. Процесс продолжается до тех пор, пока текущая строка соответствует какой-нибудь фразе из словаря. Но рано или поздно текущая строка перестает соответствовать какой-нибудь фразе словаря. В момент, когда текущая строка представляет собой последнее совпадение со словарем плюс только что прочитанный символ сообщения, кодер выдает код, который состоит из индекса совпадения и следующего за ним символа, который нарушил совпадение строк. Новая фраза, состоящая из индекса совпадения и следующего за ним символа, прибавляется в словарь. В следующий раз, если эта фраза появится в сообщении, она может быть использована для построения более длинной фразы, что повышает меру сжатия информации. Алгоритм LZW построен вокруг таблицы фраз (словаря), которая заменяет строки символов сжимаемого сообщения в коды фиксированной длины. Таблица имеет так называемое свойством опережения, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа К, фраза w тоже заносится в словарь. Если все части словаря полностью заполнены, кодирование перестает быть адаптивным (кодирование происходит исходя из уже существующих в словаре фраз). Алгоритмы сжатия этой группы наиболее эффективны для текстовых данных больших объемов и малоэффективны для файлов маленьких размеров (за счет необходимости сохранение словаря). Алгоритм Хаффмана В основе алгоритма Хаффмана лежит идея кодирования битовыми группами. Сначала проводится частотный анализ входной последовательности данных, то есть устанавливается частота вхождения каждого символа, встречащегося в ней. После этого, символы сортируются по уменьшению частоты вхождения. Основная идея состоит в следующем: чем чаще встречается символ, тем меньшим количеством бит он кодируется. Результат кодирования заносится в словарь, необходимый для декодирования. Рассмотрим простой пример, иллюстрирующий работу алгоритма Хаффмана. Пусть задан текст, в котором бурва 'А' входит 10 раз, буква 'В' - 8 раз, 'С'- 6 раз , 'D' - 5 раз, 'Е' и 'F' - по 4 раза. Тогда один из возможных вариантов кодирования по алгоритму Хаффмана приведен в таблицы 1. Таблица 1.
Как видно из таблицы 1, размер входного текста до сжатия равен 37 байт, тогда как после сжатия - 93 бит, то есть около 12 байт (без учета длины словаря). Коэффициент сжатия равен 32%. Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранение словаря). На практике программные средства сжатия данных синтезируют эти три "чистых" алгоритмы, поскольку их эффективность зависит от типа и объема данных. В таблице 2 приведены распространенные форматы сжатия и соответствующие им программыи-архиваторы, использующиеся на практике. 31.Ба́зада́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ).Классификация баз данных По типу хранимой информации БД делятся на
Среди документальных баз различают библиографические, реферативные и полнотекстовые. К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.). В системах фактографическоготипа в БД хранится информация об интересующих пользователя объектах предметной области в виде «фактов» (например, биографические данные о сотрудниках, данные о выпуске продукции производителями и т.п.); в ответ на запрос пользователя выдается требуемая информация об интересующем его объекте (объектах) или сообщение о том, что искомая информация отсутствует в БД. По характеру организации хранения данных и обращения к ним различают
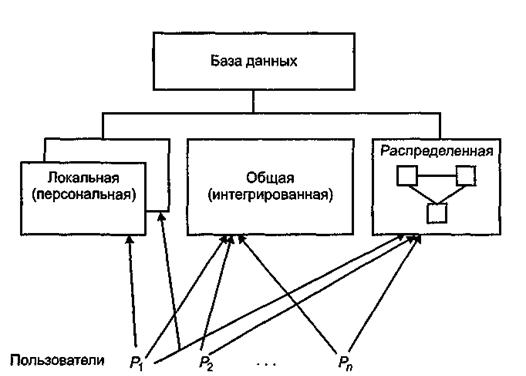
Персональная база данных -это база данных, предназначенная для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД. Интегрированные и распределенныеБД предполагают возможность одновременного обращения нескольких пользователей к одной и той же информации (многопользовательский, параллельный режим доступа). Это привносит специфические проблемы при их проектировании и в процессе эксплуатации БнД. РаспределенныеБД, кроме того, имеют характерные особенности, связанные с тем, что физически разные части БД могут быть расположены на разных ЭВМ, а логически, с точки зрения пользователя, они должны представлять собой единое целое. БД классифицируются по объему.Особое место здесь занимают так называемые очень большие базы данных. Это вызвано тем, что для больших баз данных по-иному ставятся вопросы обеспечения эффективности хранения информации и обеспечения ее обработки. По характеру организации данныхБД могут быть разделены на
Этот классификационный признак относится к информации, представленной в символьном виде. К неструктурированным БД могут быть отнесены базы, организованные в виде семантических сетей. Частично структурированными можно считать базы данных в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры БД. Только после этого базы данных такого типа могут быть заполнены данными.
Модель данных — совокупность структур данных и операций их обработки. Иерархическая модель данных Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево). К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Сетевая модель данных В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Реляционная модель данных Понятие реляционный (англ. relation — отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: каждый элемент таблицы — один элемент данных; все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину; каждый столбец имеет уникальное имя; одинаковые строки в таблице отсутствуют; порядок следования строк и столбцов может быть произвольным. 32.Система управления базами данных (СУБД) - совокупность языковых и программных средств, предназначенных для создания, наполнения, обновления и удаления баз данных. |
|||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 560. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |