|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
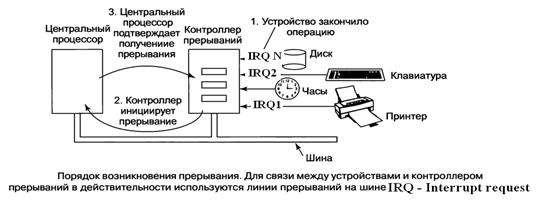
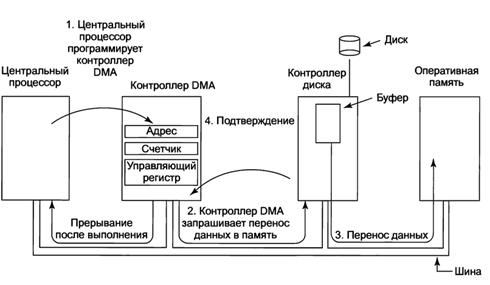
Организация взаимодействия процессора с ПУ.Программный ввод – вывод. Процессор постоянно опрашивает устройство и отслеживает его состояние(обычно готовность устройства определяется состоянием специального бита контроллера Ввода - Вывода). При готовности устройства процессор записывает или считывает данные с устройства. Недостаток - процессор постоянно занят только анализом состояния устройства. Ввод – вывод по прерываниям. Когда устройство ввода-вывода завершает порученную ему работу, оно инициирует прерывание (при условии, что прерывания разрешены операционной системой). Это делается путем выставления сигнала на специально выделенной линии шины. Этот сигнал обнаруживается микросхемой контроллера прерываний, расположенной на системной плате. Если не было никаких других отложенных прерываний, контроллер прерываний немедленно обрабатывает инициированное прерывание. Если он находится в процессе обработки другого прерывания или какие-нибудь другое устройство в то же самое время выставило на шине запрос на прерывание более высокого приоритетного уровня, то прерывание от устройства с более низким приоритетом на некоторое время игнорируется. В таком случае оно продолжает выставлять на шину сигнал на прерывание до тех пор, пока оно не будет обслужено центральным процессором. Для обработки прерывания контроллер прерываний передает процессору номер устройства запросившего прерывание (помещает его на линии шины адреса), указывая, какое устройство требует к себе внимания, и выставляет сигнал на прерывание работы центрального процессора (рис. 2.18). Сигнал на прерывание приводит к тому, что центральный процессор прерывает работу и приступает к обработке запроса на прерывание. Номер устройства запросившего прерывание используется в качестве индекса в таблице, называемой вектором прерываний. Соответствующая ячейка в таблице хранит адрес памяти с которого начинается программа обработки прерывания. Этот адрес загружается в счетчика команд и начинает работать программа обслуживания прерывания.  Практически сразу после запуска процедура обработки прерывания подтверждает получение прерывания, записывая определенное значение в один из портов ввода-вывода контроллера прерываний. Это подтверждение сообщает контроллеру, что он может выдавать новое прерывание. Информация о прерванном процессе(программе) может храниться либо в стеке процесса либо в стеке ядра(системном стеке) ПрямойдоступкпамятиDMA (Direct Memory Access). Операционная система может использовать DMA только при наличии аппаратного DMA-контроллера, Он может располагаться на материнской плате (в северном мосту, один для всех устройств) либо может быть встроен в контроллеры внешних устройств (но такая конструкция требует отдельного DMA-контроллера для каждого устройства.) Сначала центральный процессор программирует DMA-контроллер, устанавливая значения его регистров , начальный адрес памяти с которого данные будут записываться в память, и количество передаваемых данных(записываются в счетчик.)таким образом, чтобы он знал, что и куда нужно передать (рис. 2.16). Он также выдает команду контроллеру диска на чтение данных с диска во внутренний буфер контроллера. После того как в буфере контроллера окажутся данные, к работе приступает DMA. Он формирует адрес памяти и команды записи данных с буфера контроллера внешнего устройства в память. По окончании передачи всех данных буфера контроллер Внешнего устройства сообщает об этом контроллеру DMA. DMA может работать в двух режимах : пословном(передается слово ) и поблочном(передается блок).При работе в режиме DMA данные могут передаваться не сразу от контроллера ВУ в ОП а считываться в контроллер DMA, а из него в память.
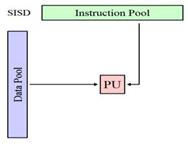
11.Классификация вычислительных систем по Флину. В 1969 М.Флинном была предложена общ классиф-я арх-р ЭВМ по призн-м наличия параллелизма в потоках команд и данных (по сп-бамобраб-ки команд и данных). Арх-ра SISD ( Single Instruction, Single Data - одиночный поток команд, одиночный поток данных)— это традиционный комп-р фон Неймановской арх-ры с 1проц-ром, кот-й вып-ет последов-но одну инстр-ю за другой, работая с одним потоком данных. В данном классе не использ-ся параллелизм ни данных, ни инструкций, и следов-но SISD-машина не явл-сяпараллельной. К этому классу также принято относить конвейерные, сурерскалярные VLIW-проц-ры.
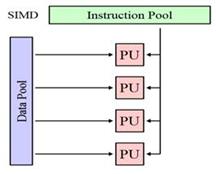
SIMD(Singleinstruction, multipledata) –арх-ра с одинарным потоком команд и множественным потоком данных. Типичными представителями SIMD явл-сявекторныепроц-ры, обычные соврем проц-ры, когда работают в режиме выполн-я команд векторных расшир-й, а также особый подвид с большим кол-вом проц-ров — матричные проц-ры. Проц-р таких машин имеет матричную стр-ру, в узлах кот-й включенное большое кол-во сравн-но простых быстродействующих процессорных эл-тов, кот-е могут иметь собств или общую память данных.В SIMD-машинах один процессор загружает одну инструкцию, набор данных к ним и выполняет операцию, описанную в этой инструкции, над всем набором данных одновременно.
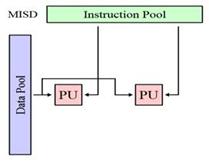
MlSD (Multiple Instruction stream, Single Data stream) - архитектура с множественным потоком команд и одинарным потоком данных, которая получила также название конвейера обработки данных (рис.2.5). Она составляет цепочку последовательно соединенных процессоров (микропроцессоров), которые управляются параллельным потоком команд. На вход конвейера из памяти подается одинарный поток данных, которые проходят последовательно через все процессоры, любой из которых делает обработку данных под управлением своего потока команд и передает результаты следующему по цепочке процессору, который использует их как входные данные. Отказоустойчивые компьютеры, выполняющие одни и те же команды избыточно с целью обнаружения ошибок, как следует из определения, принадлежат к этому типу. К этому типу иногда относят конвейерную архитектуру, но не все с этим согласны, так как данные будут различаться после обработки на каждой стадии в конвейере. Было создано немного ЭВМ с MISD-архитектурой, поскольку MIMD и SIMD чаще всего являются более подходящими для общих методик параллельных данных. Они обеспечивают лучшее масштабирование и использование вычислительных ресурсов, чем архитектура MISD. можно считать, что реальных систем — представителей данного класса не существует.
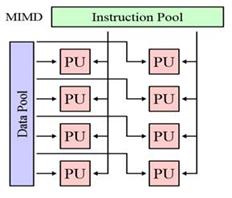
MIMD ( MultipleInstructionstream, MultipleDatastream )- архитектура с множественными потоками команд и банных. К таким структурам относятся многопроцессорные и многомашинные вычислительные системы. Они могут отличаться принципом управления (централизованное или распределенное), организацией памяти (общая, распределенная или комбинированная) и структурой связей между компьютерами или процессорами.
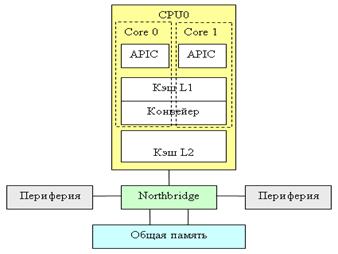
Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных. Сюда принято относить традиционные мультипроцессорные машины, многоядерные и многопоточные процессоры, а также компьютерные кластеры. По работе с памятью этот класс делится на под-классы. SM-MIMD (shared memory MIMD). В эту группу попадают многопроцессорные машины с общей памятью, многоядерные процессоры с общей памятью.Классический и самый распространенный пример — мультипроцессоры — многопроцессорные SMP-сервера. В таких машинах память каждому процессору видна как общее адресное пространство, и процессоры обмениваются данными друг с другом данными по общей адресной шине через общие переменные (sharedvariables). Для каждого процессора доступ к любому участку памяти является одинаковым. DM-MIMD (distributed memory MIMD). В этот под - класс попадают многопроцессорные MIMD-машины с распределенной памятью. 12.Характеристики процессора: аппаратная многопоточность и аппаратная виртуализация ,и принципы работы. назначение кэша L1,L2,L3. Аппаратная многопоточность. Суть многопоточности состоит в том, что когда процессору необходимо получить данные из медленной основной памяти, он вместо того, чтобы простаивать в ожидании этих данных, переключается на выполнение другого программного потока, который готов к исполнению. Многопоточность увеличивает пропускную способность всей системы. Концептуально операции многопоточного процессора эквивалентны переключению контекста (процесса или потока) на уровне операционной системы. Различие состоит в том, что многопоточный процессор производит переключение активного потока за один такт, в то время как программная реализация на уровне ОС требует на несколько порядков больших временных затрат. Это достигается путём аппаратной репликации регистрового контекста для каждого потока. Аппаратная многопоточность получила свое развитие в технологии Hyper-Threading.когда одно физическое ядро представляет из себя несколько «виртуальных» (рис. 2.15)
Технология виртуализации, компонент многоядерной технологии поддержки виртуализации на аппаратном уровне, обеспечивает поддержку виртуальных машин на уровне процессора с помощью специального режима и дополнительных команд процессора. При этом повышаются как надежность и производительность работы приложений, так и уровень общей безопасности. Аппаратная виртуализация обеспечивает производительность, сравнимую с производительностью невиртуализованной машины, что дает виртуализации возможность практического использования и влечет её широкое распространение. Наиболее распространены технологии виртуализации Intel -VT и AMD-V. В совр-х комп-х кэш бывает 3ур-й.Самым быстрым явл-ся кэш 1ур-ня — L1 cache (level 1 cache). Он явл-ся неотъемлемой частью проц-ра, поскольку расположена на одном с ним кристалле и входит в состав функц-х блоков. В совр-х процесс-х обычно L1 разделен на два кэша — кэш команд (инструкций) и кэш данных (Гарвардская архитектура). Большинство процессоров без L1 не могут функционировать. L1 работает на частоте процессора, Вторым по быстродействию явл-ся кэш 2ур-ня — L2 cache, кот-й обычно, как и L1, расположен на одном кристалле с проц-ром. В ранних версиях проц-ров L2 реализован в виде отдельного набора микросхем памяти на материнской плате. Объём L2 от 128 кбайт до 1−12 Мбайт. В соврем-х многоядерных процессорах кэш второго уровня, находясь на том же кристалле, может являтся памятью раздельного пользования — при общем объёме кэша в nM Мбайт на каждое ядро приходится по nM/nCМбайта, где nC — количество ядер процессора. Кэш 3ур-ня наименее быстродействующий, но он мбочень большим — > 24 Мбайт. L3 медленнее предыдущих кэшей, но всё равно значительно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании и предназначен для синхронизации данных различных L2. В многопроцессорных (многоядерных системах) неск-ко процессорных узлов работают одновр-но, поэтому возможна сит-я параллельного доступа к 1 ячейке памяти. При усл-и, что ни один из них не меняет знач-е данной ячейки, они могут свободно пользоваться ей совместно, кэшируя по своему усмотр-ю. Но как только один из них обновляет знач-е ячейки, данные в локальных кэшах других узлов могут оказаться устаревшими. Следов-но, необх-м мех-змуведомл-я всех узлов об измен-и знач-я в общей памяти; такой мех-змназ-ся протоколом когерентности. Если подобный протокол применён, то говорят, что система имеет «когерентную память.
13.Понятие интерфейса (шины). Классификация интерфейсов (магистральный(общая шина) и радиальный интерфейс(звезда) ),понятие системной шины, шины ввода/вывода, шины периферийных устройств. Технические средства и правила, обеспечивающие взаимосвязь устройств между собой, называются интерфейсом. В интерфейсе стандартизируются: - назначение и количество линий интерфейса. - параметры электрических сигналов. - протоколы обмена информацией и выполнения функций интерфейса. - конструктивные параметры. Интерфейс включает физическую и логическую части. Логическая часть – набор правил (протоколов) обмена сигналами между устр-вами. Физическая часть –реализуется в виде электрических линий для передачи сигналов и набора микросхем, обеспечивающих выполнение основных функций интерфейса. |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 609. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |