|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
База знаний. Модели представления знаний.База знаний (БЗ; англ. knowledge base, KB) в информатике и исследованиях искусственного интеллекта — это особого рода база данных, разработанная для оперирования знаниями (метаданными). Полноценные базы знаний содержат в себе не только фактическую информацию, но и правила вывода, допускающие автоматические умозаключения о вновь вводимых фактах и, как следствие, осмысленную обработку информации. Область наук об искусственном интеллекте, изучающая базы знаний и методы работы со знаниями, называется инженерией знаний. Современные базы знаний обычно работают совместно с продвинутыми системами поиска информации и имеют тщательно продуманную структуру и формат представления знаний.
Первый подход, называемый эмпирическим, основан на изучении принципов организации человеческой памяти и моделировании механизмов решения задач человеком. На основе этого подхода в настоящее время разработаны и получили наибольшую известность следующие модели: · продукционные модели – модель основанная на правилах, позволяет представить знание в виде предложений типа: «ЕСЛИ условие, ТО действие». Продукционная модель обладает тем недостатком, что при накоплении достаточно большого числа (порядка нескольких сотен) продукций они начинают противоречить друг другу; · сетевые модели (или семантические сети) – в инженерии знаний под ней подразумевается граф, отображающий смысл целостного образа. Узлы графа соответствуют понятиям и объектам, а дуги – отношениям между объектами. Обладает тем недостатком, что однозначного определения семантической сети в настоящее время отсутствует;  · фреймовая модель – основывается на таком понятии как фрейм (англ. frame – рамка, каркас). Фрейм – структура данных для представления некоторого концептуального объекта. Информация, относящаяся к фрейму, содержится в составляющих его слотах. Слоты могут быть терминальными либо являться сами фреймами, т.о. образуя целую иерархическую сеть. Второй подход можно определить как теоретически обоснованный, гарантирующий правильность решений. Он в основном представлен моделями, основанными на формальной логике (исчисление высказываний, исчисление предикатов), формальных грамматиках, комбинаторными моделями, в частности моделями конечных проективных геометрий, теории графов, тензорными и алгебраическими моделями. В рамках этого подхода до настоящего времени удавалось решать только сравнительно простые задачи из узкой предметной области.
9 Проектирование распределенных баз данных
Распределенная база данных (РБД) - система логически интегрированных и территориально распределенных БД, языковых, программных, технических и организационных средств, предназначенных для создания, ведения и обработки информации. Это означает , что информация физически хранится на разных ЭВМ, связанных сетью передачи данных. Любой узел (участок) может выполнять приложение и участвовать в работе по крайней мере одного приложения. Большинство требований, предъявляемых к РБД, аналогично требованиям к централизованным БД, но их реализация имеет свою, рассматриваемую ниже специфику. В РБД иногда полезна избыточность. Дополнительными специфическими требованиями являются : 1) ЯОД в рамках схемы должен быть один для всех локальных БД; 2) доступ должен быть коллективным к любой области РБД с соответствующей защитой информации; 3) подсхемы должны быть определены в месте сосредоточения алгоритмов (приложений, процессов) пользователя; 4) степень централизации должна быть разумной; 5) необходимы сбор и обработка информации об эффективности функционирования РБД После размещения каждый узел имеет локальное, узловое представление (локальная логическая модель). Физическую реализацию (логического) фрагмента называют хранимым фрагментом. Иначе говоря, РБД можно представить в виде, показанном на рис. 12.3. Сеть в РБД образуют сетевые операционные системы (например, Windows NT, Novell NetWare). В качестве СУБД, изначально предназначавшихся для использования в сети, следует назвать BTrieve, Oracle, Interbase, Sybase, Informix. В силу распределенности данных особую значимость приобретает словарь данных (справочник) РБД, который в отличие от словаря централизованной БД, имеет распределенную, многоуровневую структуру . В общем случае могут быть выделены сетевой, общий внешний, общий концептуальный, локальные внешние, локальные концептуальные и внутренние составляющие словаря РБД. Естественно, что для работы в РБД необходимы администраторы РБД и локальных БД, рабочими инструментами которых являются перечисленные словари. Схема работы РБД показана на рис. 12.4. Пользовательский запрос, определяемый приложением, поступает в систему управления распределенной базы данных (СУРБД) и через сетевую и локальную операционные системы попадает в локальную СУБД. Если запрос связан с локализованными данными, СУБД осуществляет вызов данных из локальной БД, которые поступают пользователю. Если часть данных для выполнения приложения находится в другой локальной БД, локальная СУБД дополнительно через локальные и сетевые операционные системы осуществляет удаленный вызов процедуры (Remote Procedure Call - PRC), после выполнения которой данные передаются пользователю. Возможны четыре стратегии хранения данных: централизованная (часто обеспечиваемая архитектурой клиент/сервер), расчленение (фрагментации), дублирование, смешанная. 10 Взаимные блокировки в распределенных базах данных. Причины возникновения и способы их устранения.
Взаи́мная блокиро́вка (англ. deadlock) — ситуация в многозадачной среде или СУБД, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых самими этими процессами.
Шаг Процесс 1 Процесс 2 0 Хочет захватить A и B, начинает с A Хочет захватить A и B, начинает с B 1 Захватывает ресурс A 2 Захватывает ресурс B 3 Ожидает освобождения ресурса A 4 Ожидает освобождения ресурса B 5 Взаимная блокировка
Существуют алгоритмы удаления взаимной блокировки. В то же время, выполнение алгоритмов поиска удаления взаимных блокировок может привести к livelock — взаимная блокировка образуется, сбрасывается, снова образуется, снова сбрасывается и так далее.
Кроме того, эти алгоритмы реализуются менеджером ресурсов — программой, отвечающей за блокировку и разблокировку. Если же часть занятых в блокировке ресурсов распределяется кем-то другим, обнаружение взаимной блокировки невозможно. К примеру, СУБД Oracle обнаруживает взаимную блокировку запросов к её базам данных, но если в приведенном примере объекты — это поле базы и, к примеру, файл на жестком диске, взаимная блокировка обнаружена не будет — СУБД этот файл не обрабатывает и для неё взаимной блокировки нет.
Практически об устранении взаимных блокировок надо заботиться ещё на этапе проектирования системы — это единственный более-менее надежный способ с ними бороться. В крайнем случае, когда основная концепция не допускает возможности избежать взаимных блокировок, следует хотя бы строить все запросы ресурсов так, чтобы такие блокировки безболезненно снимались.
Классический способ борьбы с проблемой — разработка иерархии блокировок, установление правила, что некоторые блокировки никогда не могут захватываться в состоянии, в котором уже захвачены какие-то другие блокировки. Говоря точно, речь о разработке отношения сравнения между блокировками, и о запрете захвата «большей» блокировки в состоянии, когда уже захвачена «меньшая».
В некоторых случаях, особенно в поделенных на модули архитектурах, это является проблемой. Так, например, в межмодульном интерфейсе приходится вводить вызовы, которые не делают ничего, кроме захвата и освобождения неких блокировок в модуле. Такой подход используется в файловых системах Windows в интерфейсе их взаимодействия с подсистемами кэша и виртуальной памяти.
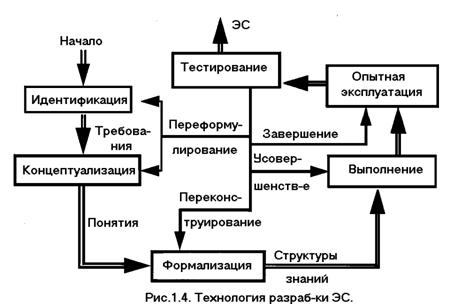
При разработке ЭС, как правило, используется концепция "быстрого прототипа". Суть этой концепции состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования. Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария. В ходе работ по созданию ЭС сложилась определенная технология их разработки, включающая шесть следующих этапов (рис. 1.4): идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификацииопределяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей.
На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. На этапе формализации выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями. На этапе выполнения осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач.
|
||
|
|
Последнее изменение этой страницы: 2018-05-27; просмотров: 489. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |