|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
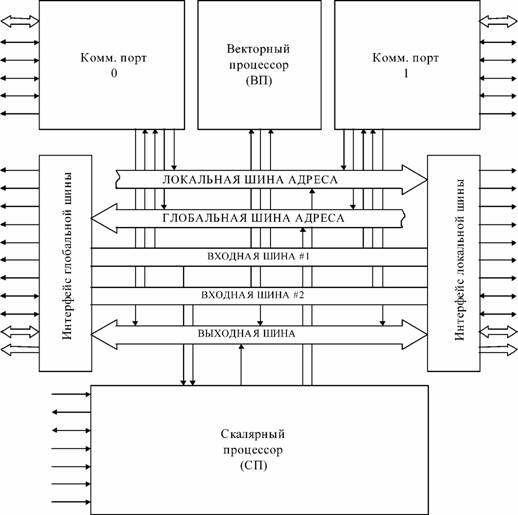
Внешний интерфейс процессораСтруктура процессора, описанная в данном разделе, отражает взгляд программиста, поэтому некоторые понятия, которые не используются при программировании, опущены. Процессор NM6403 имеет четыре канала, по которым он может обмениваться данными с внешними устройствами (см. Рис. 1-1). Рис. 1-1 Схема каналов доступа к данным со стороны процессора NM6403.
Глобальная и локальная шина используются для доступа к внешней памяти. Память, которая доступна через глобальную шину, называется глобальной памятью. Память, доступная через локальную шину, называется локальной. Помимо работы с внешней памятью процессор может принимать и передавать данные через коммуникационные порты. Коммуникационные порты связывают данный процессор с другими такими же, или с процессорами TMS320C4х, которые имеют аналогичный интерфейс обмена данными. Внутренней памяти в обычном понимании в процессоре нет. Общее описание внутренней структуры процессора Процессор NM6403 имеет следующие внутренние блоки (Рис. 1-2): - скалярный процессор (СП); - векторный процессор (ВП); - два DMA-сопроцессора, управляющие работой коммуникационных портов; - два таймера; -регистры управления интерфейсом доступа к внешней памяти. Рис. 1-2 Блочная структура процессора NeuroMatrix NM6403.
Процессор NM6403 имеет 64-х разрядный интерфейс работы с внешней памятью. За одно обращение к памяти он позволяет записать или прочитать одно 64-х разрядное число по каждой из шин. Описание основных элементов скалярного процессора Скалярный процессор представляет собой RISC ядро, отвечающее за подготовку данных для векторного процессора. Он также может использоваться и как самостоятельный вычислительный блок.  СП имеет 8 адресных регистров и 8 регистров общего назначения. Помимо этого, существует набор специализированных регистров. СП позволяет осуществлять следующие операции: - различные виды адресации с модификацией адресных регистров; - чтение/запись в память как 32-х разрядных слов, так и пар слов, образующих 64-х разрядное число; - все виды арифметических и логических операций над регистрами общего назначения с модификацией и без модификации флагов состояния; - различные типы сдвигов, в том числе на произвольное количество битов; - условные и безусловные переходы, в том числе отложенные переходы; - вызовы функций с записью в стек адреса возврата, в том числе и отложенные вызовы функций; - пошаговое умножение; - управление таймерами; - настройка регистров управления доступом к внешней памяти на тип, используемый в конкретном устройстве; - управление векторным процессором путем задания его конфигурации. Описание основных элементов векторного процессора ВП представляет собой специализированный матричный узел – операционное устройство (ОУ) для выполнения операций умножения с накоплением, арифметических и логических операций, маскирования, функций активации над векторами и матрицами. Под векторами понимаются одномерные массивы однородных данных, расположенные в памяти в виде непрерывного блока. Матрица - это массив векторов. Разрядность всех узлов ВП составляет 64 бита. ВП осуществляет обработку целочисленных данных, которые упакованы в 64-х разрядные слова с помощью простой конкатенации (см. Рис. 1-3). В общем случае слово упакованных данных представляет собой вектор D = {D k...D 1}, содержащий k элементов, суммарная разрядность которых составляет 64 бита. Причем в одном слове Dмогут быть упакованы данные, имеющие разную разрядность. Количество элементов k, упакованных в одном слове, зависит от их разрядностей и может принимать целочисленное значение в диапазоне от 1 до 64. Рис. 1-3 Формат слова упакованных векторных данных.
В состав ВП входят следующие компоненты: Рабочая матрица- операционный узел, в котором осуществляются операции умножения с накоплением. С рабочей матрицей связана пара регистров, которые определяют её разбиение на столбцы и строки. Описание функционирования рабочей матрицы приведено в параграфе 1.4.1. Взвешенное суммирование; Теневая матрица- устройство, используемое для ускорения закачки весовых коэффициентов в рабочую матрицу. В то время, как рабочая матрица участвует в операции умножении с накоплением, в теневую может параллельно подкачиваться новая порция весовых коэффициентов. После того, как теневая матрица загружена, она в течение одного процессорного такта может быть перегружена в рабочую. С теневой матрицей связана своя пара регистров, определяющая ее разбиение на столбцы и строки. Это разбиение может быть отличным от того, которое использовалось в рабочей матрице на предыдущем этапе; Векторное АЛУ- устройство, позволяющее совершать стандартный набор арифметических и логических операций над парами 64-х разрядных слов, каждое из которых разделено на малоразрядные элементы. При арифметических операциях в случае переполнения внутри диапазона, отведенного под один малоразрядный элемент, блокируется перенос битов в соседний элемент. Более подробное описание работы векторного АЛУ приведено в параграфе 1.4.2. Выполнение операций на векторном АЛУ; Буфер весовых коэффициентов (wfifo)- очередь глубиной в 32 64-х разрядных слова, организованная по принципу FIFO. В нее подгружаются весовые коэффициенты, и в ней они хранятся, прежде чем происходит их загрузка в теневую матрицу. Загрузка данных и их выгрузка из wfifo может осуществляться по частям, то есть, например, в wfifo можно загрузить сначала 8 слов, а затем еще 24, но так, чтобы не произошло переполнения; Буфер внутренней памяти(ram) - очередь глубиной в 32 64-х разрядных слова, организованная по принципу FIFO. Используется, как один из аргументов в операциях умножения с накоплением, а также в операциях на векторном АЛУ. В ram может быть загружено от 1 до 32 слов. Буфер может использоваться многократно, однако в операциях должны участвовать все данные, хранящиеся в ram. Не допускается использование только части хранящихся там данных; Псевдобуфер шины данных(data) используется для обозначения данных, находящихся на шине данных непосредственно в процессе их загрузки из памяти в ВП. Позволяет обрабатывать данные на проходе. Псевдобуфер имеет глубину в 32 64-х разрядных слов и организован по принципу FIFO. Используется, как один из аргументов в операциях умножения с накоплением, а также в операциях на векторном АЛУ; Буфер накопления результатов(afifo) - очередь глубиной в 32 64-х разрядных слова, организованная по принципу FIFO. Результат любой операции на ВП сохраняется в afifo. Может также использоваться, как один из аргументов в операциях умножения с накоплением и в операциях на векторном АЛУ. Для того, чтобы получить доступ к результатам вычислений на векторном процессоре, хранящимся в afifo, необходимо выгрузить их в память; Векторный регистр(vr) - 64-х разрядный регистр, используемый в качестве определенного операнда в операции умножения с накоплением. Можно представить его, как буфер, состоящий из заданного количество одинаковых слов. Может быть загружен из СП. Доступен только на запись; Устройства, обеспечивающие выполнение функции активациинад входными векторами. В ВП содержится два устройства, работающих независимо. Они позволяют активировать входные данные перед выполнением операции умножения с накоплением или перед подачей их на векторное АЛУ; Устройства, обеспечивающие выполнение операции маскированиянад входными векторами. Более подробное описание выполнения операции маскирования дано в разделе Операция маскирования; Устройство, обеспечивающее циклический сдвиг вправо на один битслова данных, подаваемого на вход Xрабочей матрицы в операции взвешенного суммирования. Более подробное описание работы устройства циклического сдвига дано в разделе 1.4.5. Циклический сдвиг вправо операнда Х при взвешенном суммировании. |
||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 440. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |