|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Формулы ошибки репрезентативности для стратифицированной выборки (пропорциональный отбор)
Где:
Ясно, что доверительный интервал при стратифицированной выборке будет меньше (выборка точней), чем при случайной выборке, т.к. средняя из внутригрупповых дисперсий меньше общей дисперсии[10]. Строгое математическое доказательство того, почему при стратифицированной выборке мы имеем право вместо общей дисперсии ставить среднюю внутригрупповых дисперсий и тем самым уменьшать величину доверительного интервала при сохранении той же надежности, можно найти. На «качественном» же уровне можно сказать следующее. Если представить доверительный интервал как дисперсию средней или как ошибку оценки этой средней ( То есть нам достаточно обеспечить несмещенную оценку всех групповых средних, чтобы обеспечить несмещенную оценку общей средней. А точность оценки групповых средних зависит только от дисперсии внутри наших групп и количества опрошенных. Другая составляющая общей дисперсии (межгрупповая дисперсия) не играет здесь никакой роли, т.к. если мы обеспечим попадание групповых средних в свои доверительные интервалы (которые зависят от внутригрупповых дисперсий), то мы автоматически добиваемся попадания общей средней в свой доверительный интервал.  Иными словами, за счет моделирования выборки мы «покрываем» межгрупповую дисперсию (исключаем возможность случайной ошибки в оценке межгрупповой дисперсии). Если же наше конструирование не будет соответствовать реальности, либо группы в самой генеральной совокупности окажутся размытыми[11], то величина межгрупповой дисперсии будет минимальной, что сводит на нет преимущества стратифицированной выборки. Таким образом, получаем, что дисперсия средней и, значит, величина доверительного интервала зависит лишь от внутригрупповых дисперсий. При пропорциональном отборе вместо общей дисперсии берется средняя внутригрупповых дисперсий, а при непропорциональном отборе – сумма взвешенных по объему всей генеральной совокупности внутригрупповых дисперсий. Теперь перейдем к непропорциональной выборке, т.е. выборке с неодинаковой удельной долей страт. В следующей таблице даны формулы ошибки репрезентативности для такой выборки. Таблица 8. Формулы ошибки репрезентативности для стратифицированной выборки (непропорциональный отбор).
Где:
Как видно из формул, при непропорциональном отборе вместо средней внутригрупповых дисперсий берется сумма взвешенных по объему генеральной совокупности внутригрупповых дисперсий. Стратифицированная выборка может проводиться пропорционально дисперсии признака в группах. Формулы ошибки репрезентативности для этого случая представлены в таблице 9. Таблица 9. Формулы ошибки репрезентативности для стратифицированной выборки (пропорционально колеблемости признака в группах).
Эти формулы являются просто преобразованными формулами ошибки репрезентативности для непропорционального отбора. Преобразование производится путем подстановки вместо
Определение объема выборки. Формулы для вычисления объема выборки за исключением отбора пропорционально дисперсии — легко получаются путем элементарных преобразований из формул ошибки репрезентативности. Таблица 10. Формулы для определения объема выборки при пропорциональном стратифицированном отборе.
Для непропорционального отбора число опрашиваемых в каждой страте определяется отдельно, исходя из их численности в генеральной совокупности. Отбор пропорционально колеблемости признака в группе вносит и другой критерий для определения величены страт в выборке – внутригрупповую дисперсию. Таблица 11. Формулы для определения объема выборки при стратифицированном отборе пропорционально колеблемости признака в группе.
Плюсы и минусы стратифицированного отбора. Стратифицированная выборка в любом случае оказывается точнее собственно-случайной. Этот метод особенно хорош, когда генеральная совокупность неоднородна. В этом случае собственно-случайный отбор крайне неэффективен (требует большого объема выборки). Однако стратифицированная выборка может быть применена лишь при наличии дополнительной информации о генеральной совокупности (например, нам необходимо процентное соотношение мужчин и женщин, в случае, если мы хотим стратифицировать выборку по полу). Отсутствие такой информации делает применение стратифицированной выборки невозможным. Еще один недостаток стратифицированного отбора – это возможность систематической ошибки. Далее на примерах попытаемся проиллюстрировать различные способы применения стратифицированной выборки. Пример: Возьмем опять данные о доходах из таблицы 1. Только теперь из этого же массива произведем не случайную, а стратифицированную выборку из четырех человек. Для возможности проведения стратифицированной выборки сделаем допущение, что из предыдущей переписи мы знаем доходы респондентов за предыдущий период и имеем основания предполагать, что к этому периоду они не изменились или изменились пропорционально. На основании этих данных можно стратифицировать генеральную совокупность по доходу. Результаты этого деления представлены в таблице 12. Таблица 12. Распределение респондентов по стратам.
Здесь в каждой группе (или страте) находятся люди с максимально близкими доходами. Необходимые нам четыре человека мы отбираем путем случайного отбора одного человека из каждой группы (т.е. проводим пропорциональную выборку). В итоге мы получаем вполне репрезентативную по доходу выборку, т.к. в нашей выборке будут в нужной пропорции представлены люди с различным материальным достатком. Более того, подобный отбор является надежнее случайного, т.к. при таком отборе не могут быть выбраны «плохие» выборки, т.е. выборки, содержащие только бедных или богатых (например, ADJL или BCEK). Однако стратифицированная выборка не всегда приносит выгоду, что показано в следующем примере. Пример:[6, 42]Допустим, что перед нами опять встала необходимость провести стратифицированную выборку из респондентов, представленных в таблице 1. Далее предположим, что за период между переписью и опросом доходы респондентов претерпели значительные изменения, то выделенные нами группы на основе данных переписи могут получиться не гомогенными (в одну страту попадут люди с разными доходами). Например, такими, которые представлены в таблице 13. Таблица 13. Распределение респондентов по стратам.
В этом случае практически никакой выгоды по сравнению с собственно-случайной выборкой стратифицированный отбор не принесет, т.к. вероятность отбора нами плохих выборок сохранится и здесь. Пример:Теперь рассмотрим случай с неоднородной генеральной совокупностью, т.е. совокупностью, в которой существуют отдельные резкие отклонения от средней тенденции. Например, генеральная совокупность, представленная в таблице 1, будет неоднородной, если, к примеру, респондент B вместо дохода в 6300 будет получать доход в 20000. Стратифицировать в этом случае можно двумя путями: так, как было стратифицировано в таблице 12 и так, как это сделано в таблице 14. Таблица 14. Распределение респондентов по стратам.
В первом случае, как уже было сказано, был проведен пропорциональный отбор, а в данном случае - соответственно непропорциональный. Пропорциональный отбор в данном случае (в случае с неоднородной генеральной совокупностью) не годится, т.к. он не обеспечит однородность страт (в какую бы страту ни попал B, эта страта сразу же станет неоднородной). Однако при непропорциональном отборе нарушается принцип равной вероятности попадания в выборку, т.к. респондент B попадает в нашу выборку при любом исходе. Для исправления этого обстоятельства при непропорциональном отборе применяется процедура взвешивания. Взвешивание призвано «восстановить» Взвешиванием мы увеличиваем удельный вес респондентов из больших страт. Для нашего примера средняя будет рассчитываться следующим образом:
Если отобрать все возможные выборки при данной стратификации (таб. 14), то без взвешивания мы получим смещенную выборочную оценку (генеральная средняя = 3817, а выборочная средняя = 6852). Однако если произвести взвешивание, то в данном случае непропорциональный отбор (стандартное отклонение = 277) будет эффективнее пропорционального (стандартное отклонение = 1878). Пример: Рассмотрим далее рассмотренный выше пример с микрорайонами. Решение проблемы может состоять в увеличении объема выборки или в проведении случайного опроса. Но последнее может привести к некоторым искажениям и неточностям, т.к. микрорайоны отличаются также и между собой. Первое же связано с дополнительными расходами. Здесь нам на помощь может прийти стратифицированная выборка. Ее можно осуществить если нам удастся объединить несколько микрорайонов как сходные. Разделив все микрорайоны на несколько относительно однородных групп, можно построить репрезентативную выборку, не увеличивая ее объем. Стратифицированная выборка может помочь нам и тогда, когда нет полного списка жителей города. В этом случае можно из каждой страты выбрать один микрорайон, в котором будет проводиться опрос, и собрать информацию о его жителях. Однако если мы неправильно выберем критерии для объединения микрорайонов, то это приведет к серьезной систематической ошибке. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 321. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |


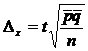

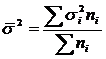 - средняя из внутригрупповых дисперсий, где
- средняя из внутригрупповых дисперсий, где  - дисперсия в группе i, а
- дисперсия в группе i, а  - численность группы i.
- численность группы i.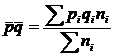 - средняя величина доли признака,
- средняя величина доли признака, - доля признака в группе i,
- доля признака в группе i,
 ), то при стратифицированном отборе эта ошибка оценки может быть выражена как «взвешенное среднее ошибок, сделанных при оценивании по отдельным слоям» [5, 106], что и будет средней из внутригрупповых дисперсий.
), то при стратифицированном отборе эта ошибка оценки может быть выражена как «взвешенное среднее ошибок, сделанных при оценивании по отдельным слоям» [5, 106], что и будет средней из внутригрупповых дисперсий.



 - объем страты в генеральной совокупности.
- объем страты в генеральной совокупности. - объем страты в выборке.
- объем страты в выборке.









