|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Формулы ошибки репрезентативности для собственно случайного отбора.Стр 1 из 8Следующая ⇒ Практическое занятие Расчет ошибки выборки, показателей генеральной совокупности, объема выборки Генеральная совокупность Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей · Все жители Москвы (10,6 млн. человек по данным переписи 2002 года) · Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года) · Юридические лица России (2,2 млн. на начало 2005 года) · Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д. Выборка (Выборочная совокупность) Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности. Репрезентативность выборки Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей. · Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы. · Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России. · Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.  В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно. Ошибка выборки (доверительный интервал) Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности. · Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома). · Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%) В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично. Типы выборок Выборки делятся на два типа: · вероятностные · невероятностные 1. Вероятностные выборки 2.Невероятностные выборки Вычисление ошибки репрезентативности для собственно случайной выборки. Пусть нам необходимо оценить средний возраст некоторой группы людей по ограниченному числу наблюдений n. Оценкой среднего значения непрерывной случайной величины является математическое ожидание:
Естественной оценкой математического ожидания является среднее арифметическое:
От оценки необходимо потребовать следующие свойства: 1. состоятельность – оценка называется состоятельное, если при увеличении числа опытов оценка сходится по вероятности с искомым параметром, 2. несмещенность – оценка называется несмещенной, если выполнялось условие
3. эффективность – оценка называется эффективной, если ее дисперсия минимальна по сравнению с другими. Среднее арифметическое обладает этими свойствами[1]. Оценка параметра является функцией от случайных величин
и дисперсией
где Тогда можно рассчитать вероятность того, что
Рисунок 1. Распределение выборочной оценки среднего. Приведем это распределение к стандартному виду.
Произведем замену переменной:
Справа получили функцию Лапласа, которая табулирована (см. Приложение):
Нам не известно значение
где При больших объемах выборки вид распределения Стьюдента приближается к виду нормального распределения, поэтому для больших выборок также можно использовать функцию Лапласа. Для повторной выборки
Для бесповторной выборки необходимо внести поправку на конечность ГС
Для большой ГС (объем ВС составляет менее 5% от ГС) поправкой на конечность совокупности можно пренебречь. Про коэффициент доверия Пример 1. Пусть была произведена выборка 1600 человек. Средний возраст по выборке – 30 лет, среднеквадратическое отклонение – 10 лет. Необходимо найти доверительный интервал. Прежде всего, необходимо задать надежность оценки. Возьмем 95% надежность. Поскольку выборка большая, воспользуемся таблицей значений функции Лапласа и найдем коэффициент доверия Тогда
С вероятностью 95% истинное средний возраст по ГС находится в интервале от 29,51 лет до 30,49 лет. Для биномиального распределения
где Тогда для повторной выборки из (1)
для бесповторной выборки из (2)
Пример 2.Из 200 опрошенных 55% - женщины. Действуем аналогично примеру 1. Выборку также можно считать большой. Тогда
С вероятностью 95% доля женщин в ГС находится в интервале от 48% до 62%. Формулы ошибки репрезентативности для собственно случайного отбора.
Где: z – коэффициент доверия, n – объем выборки, N – объем генеральной совокупности,
Определение объема выборки. Определение объема выборки – это задача, обратная решенной выше задачи вычисления ошибки выборки. Формулы для вычисления объема выборки при случайном отборе – просто преобразованные формулы ошибки репрезентативности. Они представлены в таблице 4. Таблица 2. Формулы для определения объема выборки при собственно случайном отборе.
Из (1) легко получить искомое n
Для нахождения объема выборки необходимо знать выборочное значение дисперсии признака. Его можно оценить несколькими способами. 1. Отобрать некоторое количество 2. Воспользоваться результатами предыдущих исследований (если таковые проводились). 3. Для биномиального распределения
Произведение
Точность и надежность выборки мы задаем, исходя из целей исследования. Например, насколько важное управленческое решение будет принято на основе результатов исследования. Плюсы и минусы собственно случайной выборки. Плюсом данного метода является полное соблюдения принципа случайности и, как следствие – избежание систематических ошибок. Случайная выборка обладает рядом недостатков, которые затрудняют ее применение на практике. Эти недостатки можно представить в трех пунктах: 1. Необходимость наличия списка элементов генеральной совокупности. Обычно элементами генеральной совокупности являются люди; в этом случаев качестве списка могут выступать адреса, телефоны и т.д. Трудность здесь заключается в том, что получить такой список далеко не всегда представляется возможным. Следовательно, в тех случаях, когда невозможно получить список элементов генеральной совокупности, невозможно проводить и случайный отбор. 2. Сложность проведения опроса. Процедура опроса при случайном отборе является очень громоздкой и требующей много времени. Ведь в результате случайного отбора исследователь получает на выходе список фамилий респондентов (телефонов, адресов и т.д.), которых необходимо опросить. Иными словами, интервьюерам приходится «бегать» за каждым респондентом и добиваться от него согласия ответить на «парочку вопросов». Осложняет дело и то, что респондентов порой бывает не так просто достать; в случае отсутствия респондента его приходится посещать по нескольку раз (по крайней мере не менее трех раз). Все вышеперечисленное ведет к повышенным временным затратам на проведение опроса. Временные затраты можно уменьшить только благодаря привлечению дополнительных интервьюеров, т.е. только за счет дополнительных денежных расходов. Помимо этого возникает еще так называемая проблема неответивших. 3. Сравнительно большой объем выборки. Для получения результатов со сравнительно высокой степенью точности собственно случайный отбор требует достаточно большого объема выборки по сравнению с другими видами отбора. Другими словами, случайный отбор обладает меньшей степенью точности, что в конечном счете является причиной его меньшей эффективности[3]. Существует два способа повышения эффективности выборки, которые : 1. корректировка выборочных показателей, 2. использование методов построения выборки с внедрением элемента неслучайности [6, 34]. Рассмотрим их. |
||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 375. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
 .
. .
. ,
, ,
,  , … ,
, … ,  , поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
, поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
 [2],
[2], - генеральная дисперсия.
- генеральная дисперсия. попадет в интервал
попадет в интервал  . Поскольку нам неизвестна величина
. Поскольку нам неизвестна величина  , то мы будем говорить о вероятности, с которой интервал
, то мы будем говорить о вероятности, с которой интервал  накроет
накроет  .
.



 .
. .
.
 , поэтому заменим его на
, поэтому заменим его на  . Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента.
. Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента. ,
,
 (2).
(2). следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше
следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше  .
. ,
, – доля признака,
– доля признака,  .
.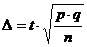 (3),
(3), (4).
(4). .
.

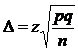

 - выборочная дисперсия,
- выборочная дисперсия, - доля признака в выборочной совокупности.
- доля признака в выборочной совокупности.



 .
. единиц из ГС. Рассчитать по полученной ВС
единиц из ГС. Рассчитать по полученной ВС  . Рассчитать необходимый объем
. Рассчитать необходимый объем  ВС и добрать недостающее число элементов
ВС и добрать недостающее число элементов  .
. , где
, где  . Тогда из (3)
. Тогда из (3) .
. максимально, когда
максимально, когда  . Таким образом, мы получаем выборку с некоторым запасом:
. Таким образом, мы получаем выборку с некоторым запасом: