|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Оценка «нормальности» исходных данныхСтр 1 из 4Следующая ⇒ Представление исходных данных Для исследования принята концепция «черного ящика», по которой производится «абстрагирование» от физической природы процессов, происходящих на предприятии (на объекте исследования), и переходу к заключениям о его функционировании только по значениям независимых переменных х, называемых далее факторами, и зависимых переменных у, называемых далее откликами. Отклики – это результативные показатели эффективности функционирования предприятия. Они представляют собой результаты его деятельности в денежном выражении. Факторы, которые мы можем менять для обеспечения требуемых значений откликов, будем называть управляемыми (оптимизируемыми) факторами. Факторы, характеризующие среду, в которой функционирует предприятие и которые мы не имеем возможности менять, будем называть объективными факторами. Пример представления исходных данных приведён в таблице 1.1.1. Таблица 1.1.1. Пример представления исходных данных
Описательная статистика. Вычисление основных статистических характеристик (ИСД) Исходные статистические данные должны являться случайными, количественными и непрерывными величинами. Применим к ним математические методы статистической обработки данных и их анализа. Для этого можно воспользоваться функцией ППП Statistica 6.0 – основная статистика. Ее можно реализовать с помощью меню “Статистика – описательная статистика”, выбрав там пункт с одноименным названием (рис.1.2.1) и далее следовать инструкциям Statistica 6.0. 
Рис. 1.2.1. Окно приглашения опции «Статистика/Основная статистика»
Вычисленные основные статистические характеристики распределений случайных величин представлены в табл.1.2.1. Рассмотрим их подробнее.
Таблица 1.2.1. Результаты вычислений по процедуре «Описательная статистика»
Среднее - среднее (арифметическое) своих аргументов(оценка математического ожидания). Стандартное отклонение - это мера того, насколько широко разбросаны точки данных относительно их среднего. Стандартная ошибка (среднего) - отношение стандартного отклонения к корню из количества экспериментов. Дисперсия –математическое ожидание квадрата центрированной случайной величины. Асимметрия - характеризует степень несимметричности распределения относительно его среднего. Положительная асимметрия указывает на отклонение распределения в сторону положительных значений. Отрицательная асимметрия указывает на отклонение распределения в сторону отрицательных значений. Медиана- это число, которое является серединой распределения случайных чисел, то есть половина чисел имеют значения меньшие, чем медиана, а половина чисел имеют значения большие, чем медиана. Эксцесс характеризует относительную остроконечность или сглаженность распределения по сравнению с нормальным распределением. Положительный эксцесс обозначает относительно остроконечное распределение. Отрицательный эксцесс обозначает относительно сглаженное распределение. Минимум – минимальное значение. Максимум– максимальное значение. Сумма- сумма всех значений генеральной совокупности. По таблице 1.2.1 оценок математических ожиданий, можно сделать предварительное заключение о подчинении исходных статистических данных нормальному закону. Для нормального закона асимметрия и эксцесс должны равняться нулю. Считается, что если асимметрия и эксцесс по абсолютной величине не превосходят двух «своих» стандартных ошибок, то это свидетельствует о возможности подчинения распределения случайных чисел нормальному закону.
Оценка «нормальности» исходных данных Выскажем гипотезу, что ИСД, представленные в таблице 1.1.1 подчинены нормальному закону и в качестве параметров нормального закона примем оценки математического ожидания и среднего квадратического отклонения (стандартного отклонения), представленные в таблице 1.2.1. «Нормальность» исходных данных весьма существенна для откликов, т.к. наличие этого свойства позволяет использовать дисперсионный анализ для оценки качества уравнений регрессии. Функция плотности нормального закона имеет вид:
где: yj- j-тый отклик (показатель эффективности); m1 – математическое ожидание; s - среднее квадратическое отклонение.
Для проверки гипотезы о соответствии распределения случайной величины какому-либо закону распределения в пакете Statistica 6.0, после ее запуска, необходимо выбрать пункт меню Statistics/Distribution Fitting, как показано на рис.1.3.1. Необходимо выбрать пункт проверки гипотезы о соответствии распределения случайной величины какому-либо закону распределения (Distribution Fitting) и запустить его, нажав на кнопку <OK>.
Рис.1.3.1. Окно выбора закона распределения в STATISTICA 6.0
Если количество экспериментальных значений, как в нашем случае, сравнительно невелико, используется критерий согласия Колмогорова-Смирнова, вычисляемый по формуле для всех имеющихся экспериментальных значений.
где: N – общее количество реализаций случайной величины; F*(yj) – эмпирическое значение функции распределения; F(yj) – гипотетическое значение функции распределения. Щелкнув по кнопке <Plot of observedand expected distribution> вы сможете увидеть график функции распределения для выбранной величины (рис.1.3.2). В «шапке» графика указана величина критерия Колмогорова-Смирнова d =
Рис.1.3.2. График оценки “нормальности” переменной х1
Кластерный анализ Часто возникает ситуация, когда необходимо разбить факторы на несколько групп. В этом случае проводится кластерный анализ. В строке меню из пункта Статистика выбирается модуль Многомерные исследовательские методы подмодуль Анализ кластеров (Cluster Analysis). Откроется стартовая панель модуля Анализ кластеров (Cluster Analysis):
Рис. 1.4.1 Стартовая панель модуля Кластерный анализ Выбирается метод. В главной части панели находится список методов кластерного анализа, реализованных в STATISTICA 6.0. После выбора метода необходимо нажать кнопку
Рис. 1.4.2. Диалоговое окно метода k-means Необходимо выбрать переменные для анализа. Нажать кнопку Variables (Переменные) в левом верхнем углу текущего окна и откроется диалоговое окно: Select variables for the analysis (Выбор переменных для анализа), выбрать переменные, а затем нажать кнопку
Рис.1.4.3. Выбор переменных для Кластерного анализа После этого необходимо установить начальные значения. на поле, находящееся ниже кнопкиVariables (Переменные). Нажав на стрелку в поле Cluster (Кластер), можно выбрать кластеризацию по строкам или столбцам. В поле Number of clusters (Число кластеров) нужно определить число групп, на которые хотим разбить факторы. · В строке Number of(iterations) (Число итераций) задается максимальное число итераций, используемых при построении классов. Группа опций Начальные центры кластера (Initial cluster centres) позволяет задать начальные центры кластеров. После того как все установки сделаны, необходимо нажать кнопку В окне результатов в верхней части приведена следующая информация (см. рис. 1.4.4): · Количество переменных (Number of variables) – 4; · Число регистров (Number of cases) – 64; · K-means clustering of cases – Метод кластеризации k-means clustering; · Количество групп (Number of cluster) – 3; · Solution was obtained after 3 iterations – Решение найдено после 3 итераций.
Рис. 1.4.4. Окно результатов кластеризации районов по методу средних Для получения более подробной информации выбирается закладка Расширенный (Advanced). Данное диалоговое окно состоит из двух частей: верхней – информационной, и нижней, где содержатся функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа. Факторный анализ Основная цель факторного анализа в том, чтобы обнаружить скрытые общие факторы, объясняющие связи между наблюдаемыми признаками (параметрами) объекта. Для этого в строке меню из пункта Статистиканеобходимо выбрать модуль Многомерные исследовательские методыи открыть модуль Факторный анализ или Анализ особенности (Factor Analysis), на экране появится стартовая панель модуля:
Рис. 1.5.1. Стартовая панель модуля Факторного анализа Прежде всего, в строке Файл входных данных (Input File) указывается тип исходного файла, с которым будет идти работа. В модуле возможны следующие типы исходных данных: |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 363. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |



 ,
,
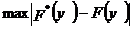 = 0.14380 и степень доверия p = n.s. Степень доверия p = n.s. показывает, что статистические данные не противоречат гипотезе о их подчинении нормальному закону.
= 0.14380 и степень доверия p = n.s. Степень доверия p = n.s. показывает, что статистические данные не противоречат гипотезе о их подчинении нормальному закону.

 в правом верхнем углу панели. Например, диалоговое окно метода k-means(см. рис. 1.4.2):
в правом верхнем углу панели. Например, диалоговое окно метода k-means(см. рис. 1.4.2):
 .
.
 в верхнем правом углу окнаk-means clustering (метод k-средних)и запустить вычислительную процедуру.
в верхнем правом углу окнаk-means clustering (метод k-средних)и запустить вычислительную процедуру.
