|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Интерпретация коэффициентов модели. Маржинальные эффекты.Найденные коэффициенты модели множественного выбора достаточно сложно интерпретировать с практической точки зрения, т.к. они не объясняют предельный эффект влияния объясняющих факторов на зависимую переменную. В этом случае обычно используют предельные эффекты каждого фактора (маржинальные эффекты). Предельный коэффициент каждого объясняющего фактора хj , j=1,..,k является непрерывным и зависит от значения остальных факторов и определяется: где f – плотность вероятности. Для логит-модели:
Для пробит-модели:
Для гомпит-модели:
Направление изменений эффекта зависит только от знака коэффициента регрессии. Порядок выполнения работы На первом этапе следует создать файла исходных данных в EViews. Для этого следует в открытом пакете выбратьFile→New →Workfile.Далее в появившемся диалоговом окне (рисунок 22) выбрать тип файла для рассматриваемой задачи Unstructured/Undated (Неструктурированный /Не датированный). Количество наблюдений (Observations) вводится равным количеству рассматриваемых пациентов.
Рисунок 22. Окно задания структуры данных в рабочем файле. Для добавления переменной следует выбрать: Object→ New Object →Series в открытом рабочем файле (рисунок 23).
Рисунок 23. Создание новых объектов. Далее в появившемся окне выбрать команду Series.(рисунок 24).
Рисунок 24 Определение структуры объекта. Имя объекта может содержать только латинские буквы и цифры, без пробелов. Примечание название переменной следует выбирать такое же, как в исходных данных (название столбца).  Для того, чтобы внести или скопировать значения переменных в таблицу, необходимо нажать кнопку Edit +/- в окне заполнения значений ряда (рисунок 25)
Рисунок 25 Редактирование переменной данных. Важно! В пакете EViews в качестве разделителя разрядов используется только «точка». В файле данных в Excel предварительно необходимо заменить все запятые на точки. Открыть любую переменную можно двойным щелчком. Для построения графика переменной ее следует открыть выбрать View→Graph. Нажав на клавиатуре Ctrl, выделить все переменные. Open→ as Group позволяет открыть все переменные в одной таблице (рисунок 26).
Рисунок 26 Редактирование группы переменных данных. Для проведения корреляционного анализа следует выбрать : View→ Covariance Analysis (рисунок 27). В появившемся диалоговом окне Covariance Analysis, например, для расчета частных парных коэффициентов корреляции следует выбрать команду Correlation.
Рисунок 27 Диалоговое окно для проведения корреляционного анализа. На рисунке 28 представлены результаты расчетов парных коэффициентов корреляции, оформленные в виде таблицы.
Рисунок 28 Таблица расчетов парных коэффициентов корреляции. Второй этап это построение модели.Для этого следуетна клавиатуре нажать Ctrl, выделить все переменные, начиная с зависимой. Щелкнуть правой кнопкой мыши и выбрать Open→ as Equation(рисунок 29).
Рисунок 29 Построение модели. Откроется диалоговое окно (рисунок 30), где в поле спецификации модели (Equation Specification) первой указана зависимая переменная, имеющая две альтернативы, и далее через пробел независимые переменные. Далее в поле Method следует выбрать модель оценивания BINARY, а затем указать переключателем какую из моделей пробит (Probit), логит (Logit) или гомпит (extreme Value)следует построить.
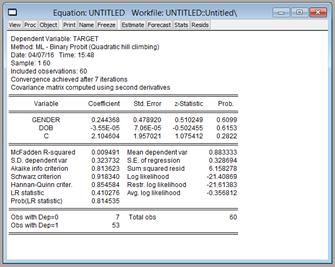
Рисунок 30 Диалоговое окно задания спецификации бинарных моделей. После задания спецификации модели появится окно результатов оценивания (рисунок 31).
Рисунок 31 Результаты оценивания бинарных моделей. Для каждой модели необходимо построить все три типа: логит-, пробит-, гомпит- модели. Выбор среди моделей логит-, пробит-, гомпит- осуществлять по информационным критериям Акайке, Шварца и Ханнана-Куинна - выбирается модель, имеющая наименьшие значения критериев. В моделях должны остаться только статистически значимые переменные(см. столбец Prob). Значения должны быть ≤α (α – уровень значимости или вероятность ошибки отклонения нулевой гипотезы о том, что коэффициент при данном факторе равен нулю, принимается как правило равным 0,05-0,1). Если значения Prob≥α , то данный фактор является не значимым и не оказывает влияния на зависимую переменную, и из модели исключается. Таким образом, на каждом этапе исключается переменная с наибольшим значением Prob и модель строится заново до тех пор, пока в модели не останутся только статистически значимые факторы. Данный метод построения модели называется методом «Пошаговое исключение» (Backward). Метод Backward начинается с построения модели, куда включены все переменные. Затем на каждом шаге из модели удаляется наименее полезная из переменных. Процедура останавливается, когда из модели больше нечего удалять (значения статистики для всех оставшихся независимых переменных ниже установленного порога). Для проверки модели можно построить ее с помощью метода «Пошаговое включение» (Forward). Метод пошагового включения (Forward) вводит переменные в модель по одной, шаг за шагом. На первом шаге вводится переменная, обычная корреляция которой с зависимой переменной максимальна (знак корреляции не важен). На каждом следующем шаге вводится переменная с самой сильной частной корреляцией. Если оба метода выбирают одни и те же переменные, вы можете быть уверены в том, что перед вами хорошая модель. При построении моделей не следует забывать обращать внимание на показатели качества модели. Необходимо построить качественную статистически значимую модель. Для этого следует рассматривать LR-статистику и соответствующую ей вероятность Prob ошибки отклонения нулевой гипотезы, о том что в модели все коэффициенты равны нулю (рисунок 31). Оценка качества построенной модели проводится на основании коэффициента R2 Мак-Фаддена, Prob (LR statistic), log likelihood и теста Хосмера-Лемешоу (рисунок 32).
Рисунок 32. Показатели качества построенной модели. 1) Коэффициент детерминации R2 Макфаддена. Коэффициент показывает, насколько изменения зависимой переменной (в процентах) объясняются изменениями совокупности независимых переменных. То есть это доля дисперсии зависимой переменной (признака), объясняемая влиянием независимых переменных (предикторов). Если значение R2 близко к единице, это означает, что построенная модель объясняет почти всю изменчивость зависимой переменной изменчивостью предикторов. И наоборот, значение R2, близкое к нулю, означает, что колебания зависимой переменной не обусловлены колебаниями предикторов. Если коэффициент близок хотя бы к 60%, это уже хорошо (оказывают влияние или нет, но при этом могут не объяснять). |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 414. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
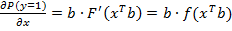 ,
, 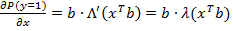 , где
, где  .
.  , где
, где  .
.  .
.