|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Оценка качества модели (или мониторинг модели).Стр 1 из 3Следующая ⇒ Задание выполняется на лабораторной работе № 2: Построение регрессионных моделей с бинарной зависимой переменной Базовый уровень: 1. Провести предварительный анализ исходных данных. Исключить аномальные наблюдения (если такие есть), заполнить пропуски (если они имеются). Провести корреляционный анализ независимых переменных, исключив переменные, значительно коррелирующие с другими переменными (>0,9). 2. Построить статистически значимую модель бинарной регрессии, оценив параметры методом максимального правдоподобия, применяя метод пошагового исключения, в которой все переменные будут статистически значимы. Подобрать функцию распределения, описывающую вероятность положительной альтернативы между нормальным распределением (пробит), логистическим (логит) и экстремальным (гомпит) на основе минимума информационных критериев. 3. Проверить качество отобранной модели, подтвердив его значениями коэффициентов R2 МакФаддена, тестом отношения правдоподобия (LR-тестом), результатами теста Хосмера-Лемешоу и любым тестом на нормальность распределения остатков (например, Колмогорова-Смирнова или Бера-Жарка). 4. Рассчитать маржинальные эффекты и провести интерпретацию коэффициентов модели. 5. Оформить отчет о выполнении задания с приведением условия задачи, результатов решения и выводов. В качестве информационных средств выполнения задания рекомендуется использовать Eviews, R. Повышенный уровень:Проверка статистической значимости и условий ограничения на коэффициенты бинарной модели с помощью теста Вальда Результатом выполнения кейс-задания является отчет по лабораторной работе № 2. К отчету предъявляются следующие требования:  1.Четкое формулирование поставленной цели исследования 2.Формулирование задач, решение которых необходимо для достижения поставленной цели. 3.Описание в виде пунктов, тех действий, которые требуются для решения поставленных задач. Все рисунки и таблицы последовательно нумеруются и описываются. Каждый пункт решения поставленных задач сопровождается анализом принятого решения. При проведении статистических тестов, обязательно выписывается нулевая и альтернативная гипотеза, формулируется принятие решения на обосновано выбранном уровне значимости, указывается критическая область отказа от нулевой гипотезы в пользу альтернативной. 4.В заключении выписывается отобранная адекватная модель с оцененными коэффициентами с указанием под оценками коэффициентов значений t-статистик в скобках или стандартных ошибок коэффициентов. Также приводятся значения маржинальных эффектов и дается их интерпретация. Построение регрессионных моделей с бинарной зависимой переменной Осваивается умение строить адекватные модели бинарной регрессии и проводить интерпретацию результатов моделирования на основе маржинальных эффектов влияния факторов на результат. Теоретические предпосылки: Цель бинарного регрессионного анализа— описание зависимости между объектом наблюдения (зависимой или результирующей переменной, имеющей только две неупорядоченные альтернативы) и факторами, воздействующими на него (независимыми переменными, предикторами, регрессорами), с тем чтобы построить модель, позволяющую по значениям регрессоров получить оценки значений зависимой переменной. Применительно к анализу риска в медицине чаще всего используется метод бинарной логистической регрессии, когда исследуется зависимость дихотомической результирующей переменной (т.е. принимающей только два значения, например — это статус выживаемости, подразумевающий два класса: выживет или умрет) от переменных с любым типом шкалы (пол, возраст, наличие осложнений, инфаркт миокарда в анамнезе и др.). Для оценки и построения модели риска применяются модели бинарного выбора – пробит, логит, гомпит. Логит-модель. Если бинарная модель имеет в качестве функции распределения функцию вида (1), то эта модель называется Логит-моделью. Функция стандартного логистического распределения:
Для оценки параметров используется метод максимального правдоподобия. Пробит-модель. Если бинарная модель имеет в качестве функции распределения функцию вида (2), то эта модель называется Пробит-моделью. Функция стандартного нормального распределения:
Стандартное нормальное распределение подразумевает, что математическое ожидание равно М=0, а среднее квадратичное отклонение s=1. Гомпит-модель. Если бинарная модель имеет в качестве функции распределения функцию вида (3), то эта модель называется экстрим-моделью или гомпит-моделью. Функция экстремального (или Гомперца) распределения:
Селекция моделей, проводится исходя из критериев Акайке, Шварца и Ханнана-Куинна, т.е. выбиралась модель, где наименьшие значения критериев. Оценка качества модели (или мониторинг модели). Если необходимо сравнить нескольких альтернативных моделей бинарного выбора с разным количеством объясняющих переменных, то, как и в случае обычных линейных моделей, сравнивать качество альтернативных моделей можно, опираясь на значения информационных критериев Акайке (4) и Шварца (5):
а также информационного критерия Ханнана-Куинна (6):
Здесь Метод максимального правдоподобия или метод наибольшего правдоподобия в математической статистике — это метод оценивания неизвестного параметра путём максимизации функции правдоподобия. Для оценки параметров бинарных моделей применяют метод максимального правдоподобия с функцией правдоподобия:
Прологарифмируем выражение. Логарифмическая функция правдоподобия имеет вид:
Функция правдоподобия в математической статистике — это совместное распределение выборки из параметрического распределения, рассматриваемое как функция параметра. Для нахождения максимума функции правдоподобия необходимо найти частные производные по параметрам и приравнять их к «0». Решаем дифференциальное уравнение правдоподобия:
Гипотеза относительно значимости построенной модели бинарного выбора: тест отношения правдоподобия Likelihood ratio test (LR), высчитывается в статистике, которые сравниваются с табличным значением χ2(n), где n – число степеней свобод, равное числу ограничений в гипотезе. Для LR-теста LR- статистика в случае значимости построенной модели близка к 1. 1) Показатели качества подгонки: 1.1) Псевдо коэффициент детерминации где n– количество наблюдений, l – логарифмическая функция правдоподобия, l со штрихом – ограниченная логарифмическая функция правдоподобия, в которой все параметры кроме свободного члена равно нулю. 1.2) Коэффициент Макфаддена Чем ближе показатели качества к единице, тем сильнее «объясняющая сила» модели. Для проверки адекватности подобранной модели имеющимся данным имеется ряд статистических критериев согласия; одним из них является критерий Хосмера–Лемешоу. Критерий согласия Хосмера–Лемешоу исследует расстояние между наблюдаемыми и ожидаемыми распределениями частот «плохих» и «хороших» заемщиков. Если уровень значимости является большим, то модель хорошо откалибрована и достаточно точно описывает реальные данные. Значение статистики Хосмера–Лемешова не должно быть меньше уровня значимости 0,05. Оптимальными считаются значения не меньше 0,5–0,6. |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 503. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
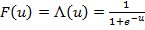 (1)
(1)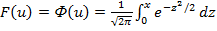 (2)
(2)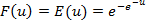 (3)
(3)  (4)
(4)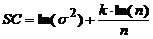 (5)
(5)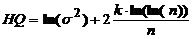 (6)
(6)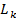 – максимальное значение функции правдоподобия для k –й из альтернативных моделей, а p – количество объясняющих переменных в этой модели, n – общее число наблюдений ряда данных. При этом среди нескольких альтернативных моделей выбирается та, которая минимизирует значение статистики критерия.
– максимальное значение функции правдоподобия для k –й из альтернативных моделей, а p – количество объясняющих переменных в этой модели, n – общее число наблюдений ряда данных. При этом среди нескольких альтернативных моделей выбирается та, которая минимизирует значение статистики критерия.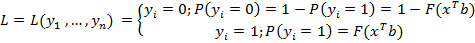
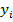 рассмотрим как n случайных величин
рассмотрим как n случайных величин 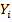 с одним возможным значением
с одним возможным значением 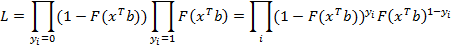
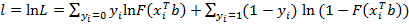
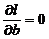 или
или 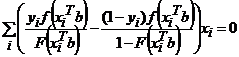 .
.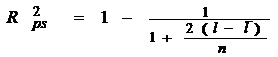 ,
,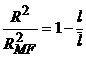 .
.