|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
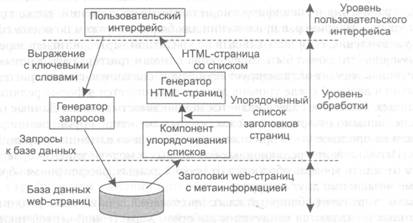
Разделение приложений по уровнямМодель клиент-сервер была предметом множества дебатов и споров. Один из главных вопросов состоял в том, как точно разделить клиента и сервера. Понятно, что обычно четкого различия нет. Например, сервер распределенной базы данных может постоянно выступать клиентом, передающим запросы на различные файловые серверы, отвечающие за реализацию таблиц этой базы данных. В этом случае сервер баз данных сам по себе не делает ничего, кроме обработки запросов. Однако рассматривая множество приложений типа клиент-сервер, предназначенных для организации доступа пользователей к базам данных, многие рекомендовали разделять их на три уровня. - уровень пользовательского интерфейса; - уровень обработки; - уровень данных. Уровень пользовательского интерфейса содержит все необходимое для непосредственного общения с пользователем, например, для управление дисплеем. Уровень обработки обычно содержит приложения, а уровень данных — собственно данные, с которыми происходит работа. В следующих пунктах мы обсудим каждый из этих уровней. Уровень пользовательского интерфейса Уровень пользовательского интерфейса обычно реализуется на клиентах. Этот уровень содержит программы, посредством которых пользователь может взаимодействовать с приложением. Сложность программ, входящих в пользовательский интерфейс, весьма различна. Простейший вариант программы пользовательского интерфейса не содержит ничего, кроме символьного (не графического) дисплея. Такие интерфейсы обычно используются при работе с мэйнфреймами. В том случае, когда мэйнфрейм контролирует все взаимодействия, включая работу с клавиатурой и монитором, мы вряд ли можем говорить о модели клиент-сервер. Однако во многих случаях терминалы пользователей производят некоторую локальную обработку, осуществляя, например, эхо-печать вводимых строк или предоставляя интерфейс форм, в котором можно отредактировать введенные данные до их пересылки на главный компьютер.  В наше время даже в среде мэйнфреймов наблюдаются более совершенные пользовательские интерфейсы. Обычно на клиентских машинах имеется как минимум графический дисплей, на котором можно задействовать всплывающие или выпадающие меню и множество управляющих элементов, доступных для мыши или клавиатуры. Типичные примеры таких интерфейсов — надстройка X-Windows, используемая во многих UNIX-системах, и более ранние интерфейсы, разработанные для персональных компьютеров, работающих под управлением MS-DOS и Apple Macintosh. Современные пользовательские интерфейсы значительно более функциональны. Они поддерживают совместную работу приложений через единственное графическое окно и в ходе действий пользователя обеспечивают через это окно обмен данными. Например, для удаления файла часто достаточно перенести значок, соответствующий этому файлу, на значок мусорной корзины. Аналогичным образом многие текстовые процессоры позволяют пользователю перемещать текст документа в другое место, пользуясь только мышью. Уровень обработки Многие приложения модели клиент-сервер построены как бы из трех различных частей: части, которая занимается взаимодействием с пользователем, части, которая отвечает за работу с базой данных или файловой системой, и средней части, реализующей основную функциональность приложения. Эта средняя часть логически располагается на уровне обработки. В противоположность пользовательским интерфейсам или базам данных на уровне обработки трудно выделить общие закономерности. Однако мы приведем несколько примеров для разъяснения вопросов, связанных с этим уровнем. В качестве первого примера рассмотрим поисковую машину в Интернете. Если отбросить все анимированные баннеры, картинки и прочие оконные украшательства, пользовательский интерфейс поисковой машины очень прост: пользователь вводит строку, состоящую из ключевых слов, и получает список заголовков web-страниц. Результат формируется из гигантской базы просмотренных и проиндексированных web-страниц. Ядром поисковой машины является программа, трансформирующая введенную пользователем строку в один или несколько запросов к базе данных. Затем она помещает результаты запроса в список и преобразует этот список в набор HTML-страниц. В рамках модели клиент-сервер часть, которая отвечает за выборку информации, обычно находится на уровне обработки. Эта структура показана на рис. 1.19.
Рис. 1.19. Обобщенная организация трехуровневой поисковой машины для Интернета
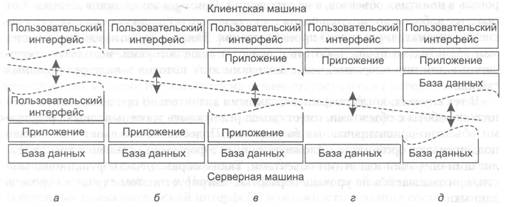
В качестве второго примера рассмотрим систему поддержки принятия решений для фондового рынка. Так же как и в поисковой машине, эту систему можно разделить на внешний интерфейс, реализующий работу с пользователем, внутреннюю часть, отвечающую за доступ к базе с финансовой информацией, и промежуточную программу анализа. Анализ финансовых данных может потребовать замысловатых методик и технологий на основе статистических методов и искусственного интеллекта. В некоторых случаях для того, чтобы обеспечить требуемые производительность и время отклика, ядро системы поддержки финансовых решений должно выполняться на высокопроизводительных компьютерах. Нашим последним примером будет типичный офисный пакет, состоящий из текстового процессора, приложения для работы с электронными таблицами, коммуникационных утилит и т. д. Подобные офисные пакеты обычно поддерживают обобщенный пользовательский интерфейс, возможность создания составных документов и работу с файлами в домашнем каталоге пользователя. В этом случае уровень обработки будет включать в себя относительно большой набор программ, каждая из которых призвана поддерживать какую-то из функций обработки. Уровень данных Уровень данных в модели клиент-сервер содержит программы, которые предоставляют данные обрабатывающим их приложениям. Специфическим свойством этого уровня является требование сохранности (persistence). Это означает, что когда приложение не работает, данные должны сохраняться в определенном месте в расчете на дальнейшее использование. В простейшем варианте уровень данных реализуется файловой системой, но чаще для его реализации задействуется полномасштабная база данных. В модели клиент-сервер уровень данных обычно находится на стороне сервера. Кроме простого хранения информации уровень данных обычно также отвечает за поддержание целостности данных для различных приложений. Для базы данных поддержание целостности означает, что метаданные, такие как описания таблиц, ограничения и специфические метаданные приложений, также хранятся на этом уровне. Например, в приложении для банка мы можем пожелать сформировать уведомление, если долг клиента по кредитной карте достигнет определенного значения. Это может быть сделано при помощи триггера базы данных, который в нужный момент активизирует процедуру, связанную с этим триггером. Обычно в деловой среде уровень данных организуется в форме реляционной базы данных. Ключевым здесь является независимость данных. Данные организуются независимо от приложений так, чтобы изменения в организации данных не влияли на приложения, а приложения не оказывали влияния на организацию данных. Использование реляционных баз данных в модели клиент-сервер помогает нам отделить уровень обработки от уровня данных, рассматривая обработку и данные независимо друг от друга. Однако существует обширный класс приложений, для которых реляционные базы данных не являются наилучшим выбором. Характерной чертой таких приложений является работа со сложными типами данных, которые проще моделировать в понятиях объектов, а не отношений. Примеры таких типов данных — от простых наборов прямоугольников и окружностей до проекта самолета в случае систем автоматизированного проектирования. Также и мультимедийным системам значительно проще работать с видео- и аудиопотоками, используя специфичные для них операции, чем с моделями этих потоков в виде реляционных таблиц. В тех случаях, когда операции с данными значительно проще выразить в понятиях работы с объектами, имеет смысл реализовать уровень данных средствами объектно-ориентированных баз данных. Подобные базы данных не только поддерживают организацию сложных данных в форме объектов, но и хранят реализации операций над этими объектами. Таким образом, часть функциональности, приходившейся на уровень обработки, мигрирует в этом случае на уровень данных. Варианты архитектуры клиент-сервер Разделение на три логических уровня, обсуждавшееся в предыдущем пункте, наводит на мысль о множестве вариантов физического распределения по отдельным компьютерам приложений в модели клиент-сервер. Простейшая организация предполагает наличие всего двух типов машин. ♦ Клиентские машины, на которых имеются программы, реализующие только пользовательский интерфейс или его часть. ♦ Серверы, реализующие все остальное, то есть уровни обработки и данных. Проблема подобной организации состоит в том, что на самом деле система не является распределенной: все происходит на сервере, а клиент представляет собой не что иное, как простой терминал. Существует также множество других возможностей, наиболее употребительные из них мы сейчас рассмотрим. Многозвенные архитектуры Один из подходов к организации клиентов и серверов — это распределение программ, находящихся на уровне приложений, описанном в предыдущем пункте, по различным машинам, как показано на рис. 1.20. В качестве первого шага мы рассмотрим разделение на два типа машин: на клиенты и на серверы, что приведет нас к физически двухзвенной архитектуре (physically two-tiered architecture). Один из возможных вариантов организации — поместить на клиентскую сторону только терминальную часть пользовательского интерфейса, как показано на рис. 1.20, а, позволив приложению удаленно контролировать представление данных. Альтернативой этому подходу будет передача клиенту всей работы с пользовательским интерфейсом (рис. 1.20, б). В обоих случаях мы отделяем от приложения графический внешний интерфейс, связанный с остальной частью приложения (находящейся на сервере) посредством специфичного для данного приложения протокола. В подобной модели внешний интерфейс делает только то, что необходимо для предоставления интерфейса приложения.
Рис. 1.20. Альтернативные формы организации архитектуры клиент-сервер
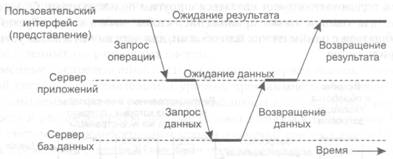
Продолжим линию наших рассуждений. Мы можем перенести во внешний интерфейс часть нашего приложения, как показано на рис. 1.20, в. Примером может быть вариант, когда приложение создает форму непосредственно перед ее заполнением. Внешний интерфейс затем проверяет правильность и полноту заполнения формы и при необходимости взаимодействует с пользователем. Другим примером организации системы по образцу, представленному на рис. 1.20, в, может служить текстовый процессор, в котором базовые функции редактирования осуществляются на стороне клиента с локально каптируемыми или находящимися в памяти данными, а специальная обработка, такая как проверка орфографии или грамматики, выполняется на стороне сервера. Во многих системах клиент-сервер популярна организация, представленная на рис. 1.20, г и д. Эти типы организации применяются в том случае, когда клиентская машина — персональный компьютер или рабочая станция — соединена сетью с распределенной файловой системой или базой данных. Большая часть приложения работает на клиентской машине, а все операции с файлами или базой данных передаются на сервер. Рисунок 1.20, д отражает ситуацию, когда часть данных содержится на локальном диске клиента. Так, например, при работе в Интернете клиент может постепенно создать на локальном диске огромный кэш наиболее часто посещаемых web-страниц. Рассматривая только клиенты и серверы, мы упускаем тот момент, что серверу иногда может понадобиться работать в качестве клиента. Такая ситуация, отраженная на рис. 1.21, приводит нас к физически трехзвенной архитектуре (physically three-tiered architecture). В подобной архитектуре программы, составляющие часть уровня обработки, выносятся на отдельный сервер, но дополнительно могут частично находиться и на машинах клиентов и серверов. Типичный пример трехзвенной архитектуры — обработка транзакций. В этом случае отдельный процесс — монитор транзакций — координирует все транзакции, возможно, на нескольких серверах данных.
Рис. 1.21. Пример сервера, действующего как клиент
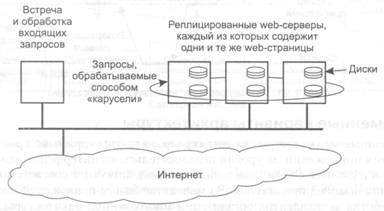
Современные варианты архитектуры Многозвенные архитектуры клиент-сервер являются прямым продолжением разделения приложений на уровни пользовательского интерфейса, компонентов обработки и данных. Различные звенья взаимодействуют в соответствии с логической организацией приложения. Во множестве бизнес-приложений распределенная обработка эквивалентна организации многозвенной архитектуры приложений клиент-сервер. Мы будем называть такой тип распределения вертикальным распределением (vertical distribution). Характеристической особенностью вертикального распределения является то, что оно достигается размещением логически различных компонентов на разных машинах. Это понятие связано с концепцией вертикального разбиения (vertical fragmentation), используемой в распределенных реляционных базах данных, где под этим термином понимается разбиение по столбцам таблиц для их хранения на различных машинах. Однако вертикальное распределение — это лишь один из возможных способов организации приложений клиент-сервер, причем во многих случаях наименее интересный. В современных архитектурах распределение на клиенты и серверы происходит способом, известным как горизонтальное распределение (horizontal distribution). При таком типе распределения клиент или сервер может содержать физически разделенные части логически однородного модуля, причем работа с каждой из частей может происходить независимо. Это делается для выравнивания загрузки. В качестве распространенного примера горизонтального распределения рассмотрим web-сервер, реплицированный на несколько машин локальной сети, как показано на рис. 1.22. На каждом из серверов содержится один и тот же набор web-страниц, и всякий раз, когда одна из web-страниц обновляется, ее копии незамедлительно рассылаются на все серверы. Сервер, которому будет передан приходящий запрос, выбирается по правилу «карусели» (round-robin). Эта форма горизонтального распределения весьма успешно используется для выравнивания нагрузки на серверы популярных web-сайтов. Таким же образом, хотя и менее очевидно, могут быть распределены и клиенты. Для несложного приложения, предназначенного для коллективной работы, мы можем не иметь сервера вообще. В этом случае мы обычно говорим об одноранговом распределении (peer-to-peer distribution). Подобное происходит, например, если пользователь хочет связаться с другим пользователем. Оба они должны запустить одно и то же приложение, чтобы начать сеанс. Третий клиент может общаться с одним из них или обоими, для чего ему нужно запустить то же самое приложение.
Рис. 1.22. Пример горизонтального распределения web-службы
Библиографический список 1. Таненбаум Э., ван Стеен М. Распределенные системы. Принципы и парадигмы. СПб.: Питер, 2003. — 877 с.
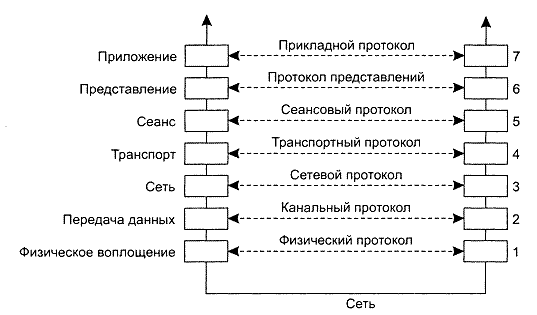
Лекция №11-12 Связь Уровни протоколов В условиях отсутствия совместно используемой памяти вся связь в распределенных системах основана на обмене (низкоуровневыми) сообщениями. Если процесс A хочет пообщаться с процессом B, он должен сначала построить сообщение в своем собственном адресном пространстве. Затем он выполняет системный вызов, который пересылает сообщение по сети процессу В. Хотя основная идея выглядит несложной, во избежание хаоса А и В должны договориться о смысле пересылаемых нулей и единиц. Если А посылает потрясающий новый роман, написанный по-французски, в кодировке IBM EBCDIC, а В ожидает результаты переучета в супермаркете, на английском языке и в кодировке ASCII, их взаимодействие будет не слишком успешным. Необходимо множество различных договоренностей. Сколько вольт следует использовать для передачи нуля, а сколько для передачи единицы? Как получатель узнает, что этот бит сообщения — последний? Как ему определить, что сообщение было повреждено или утеряно, и что ему делать в этом случае? Какую длину имеют числа, строки и другие элементы данных и как они отображаются? Короче говоря, необходимы соглашения различного уровня, от низкоуровневых подробностей передачи битов до высокоуровневых деталей отображения информации. Чтобы упростить работу с множеством уровней и понятий, используемых в передаче данных. Международная организация по стандартам (International Standards Organization, ISO) разработала эталонную модель, которая ясно определяет различные уровни, дает им стандартные имена и указывает, какой уровень за что отвечает. Эта модель получила название Эталонной модели взаимодействия открытых систем (Open Systems Interconnection Reference Model). Это название обычно заменяется сокращением модель ISO OSI, или просто модель OSI. Следует заметить, что протоколы, которые должны были реализовывать части модели OSI, никогда не получали широкого распространения. Однако сама по себе базовая модель оказалась вполне пригодной для исследования компьютерных сетей. Несмотря на то что мы не собираемся приводить здесь полное описание этой модели и всех ее дополнений, небольшое введение в нее будет нам полезно. Модель OSI разрабатывалась для того, чтобы предоставить открытым системам возможность взаимодействовать друг с другом. Открытая система — это система, которая способна взаимодействовать с любой другой открытой системой по стандартным правилам, определяющим формат, содержимое и смысл отправляемых и принимаемых сообщений. Эти правила зафиксированы в том, что называется протоколами (protocols). Для того чтобы группа компьютеров могла поддерживать связь по сети, они должны договориться об используемых протоколах. Все протоколы делятся на два основных типа. В протоколах с установлением соединения (connection-oriented) перед началом обмена данными отправитель и получатель должны установить соединение и, возможно, договориться о том, какой протокол они будут использовать. После завершения обмена они должны разорвать соединение. Системой с установлением соединения является, например, телефон. В случае протоколов без установления соединения (connectionless) никакой подготовки не нужно. Отправитель посылает первое сообщение, как только он готов это сделать. Письмо, опущенное в почтовый ящик, — пример связи без установления соединения. В компьютерных технологиях широко применяется как связь с установлением соединения, так и связь без установления соединения. В модели OSI взаимодействие подразделяется на семь уровней, как показано на рис. 2.1. Каждый уровень отвечает за один специфический аспект взаимодействия. Таким образом, проблема может быть разделена на поддающиеся решению части, каждая из которых может разбираться независимо от других. Каждый из уровней предоставляет интерфейс для работы с вышестоящим уровнем. Интерфейс состоит из набора операций, которые совместно определяют интерфейс, предоставляемый уровнем тем, кто им пользуется.
Рис. 2.1. Уровни, интерфейсы и протоколы модели OSI
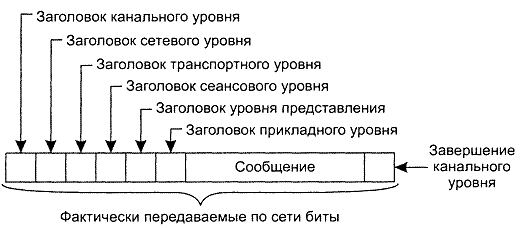
Когда процесс А на машине 1 хочет пообщаться с процессом B на машине 2, он строит сообщение и посылает его прикладному уровню своей машины. Этот уровень может представлять собой, например, библиотечную процедуру или реализовываться как-то иначе (например, внутри операционной системы или внешнего сетевого процессора). Программное обеспечение прикладного уровня добавляет в начало сообщения свой заголовок (header) и передает получившееся сообщение через интерфейс с уровня 7 на уровень 6, уровень представления. Уровень представления, в свою очередь, добавляет в начало сообщения свой заголовок и передает результат вниз, на сеансовый уровень и т. д. Некоторые уровни добавляют не только заголовок в начало, но и завершение в конец. Когда сообщение дойдет до физического уровня, он осуществит его реальную передачу, как это показано на рис. 2.2.
Рис. 2.2. Передача по сети типового сообщения
Когда сообщение приходит на машину 2, оно передается наверх, при этом на каждом уровне считывается и проверяется соответствующий заголовок. В конце концов сообщение достигает получателя, процесса B, который может ответить на него, при этом вся история повторяется в обратном направлении. Информация из заголовка уровня п используется протоколом уровня п. В качестве примера важности многоуровневых протоколов рассмотрим обмен информацией между двумя компаниями, авиакомпанией Zippy Airlines и поставщиком продуктов Mushy Meals, Inc. Каждый месяц начальник отдела обслуживания пассажиров Zippy просит свою секретаршу связаться с секретаршей менеджера по продажам Mushy и заказать 100 000 коробок «резиновых» цыплят. Обычно заказы пересылались почтой. Однако из-за постепенного ухудшения качества почтовых услуг в один прекрасный момент секретарши решают больше не писать друг другу письма, а связываться по факсу. Они могут делать это, не беспокоя своих боссов, поскольку протокол касается физической передачи заказов, а не их содержания. Точно так же начальник отдела обслуживания пассажиров может решить отказаться от цыплят и перейти на новый деликатес от Mushy, превосходные козьи ребра, это решение никак не скажется на работе секретарш. Это происходит потому, что у нас есть два уровня — боссы и их секретарши. Каждый уровень имеет свой собственный протокол (темы для обсуждения и технологию), который можно изменить независимо от другого. Эта независимость делает многоуровневые протоколы привлекательными. Каждый уровень при появлении новых технологий может быть изменен независимо от других. В модели OSI, как было показано на рис. 2.1, не два уровня, а семь. Набор протоколов, используемых в конкретной системе, называется комплектом, или стеком протоколов. Важно отличать эталонную модель от реальных протоколов. Как мы отмечали, протоколы OSI никогда не были популярны. В противоположность им протоколы, разрабатывавшиеся для Интернета, такие как TCP и IP, используются повсеместно. Удаленный вызов процедур Основой множества распределенных систем является явный обмен сообщениями между процессами. Однако процедуры send и receive не скрывают взаимодействия, что необходимо для обеспечения прозрачности доступа. Эта проблема была известна давно, но по ней мало что было сделано до появления в 1980 году статьи, в которой предлагался абсолютно новый способ взаимодействия. Хотя идея была совершенно простой (естественно, после того как кто-то все придумал), ее реализация часто оказывается весьма хитроумной. В этом разделе мы рассмотрим саму концепцию, ее реализацию, сильные и слабые стороны. Если не вдаваться в подробности, в упомянутой статье было предложено позволить программам вызывать процедуры, находящиеся на других машинах. Когда процесс, запущенный на машине A, вызывает процедуру с машины B, вызывающий процесс на машине A приостанавливается, а выполнение вызванной процедуры происходит на машине B. Информация может быть передана от вызывающего процесса к вызываемой процедуре через параметры и возвращена процессу в виде результата выполнения процедуры. Программист абсолютно ничего не заметит. Этот метод известен под названием удаленный вызов процедур (Remote Procedure Call, RPC). Базовая идея проста и элегантна, сложности возникают при реализации. Для начала, поскольку вызывающий процесс и вызываемая процедура находятся на разных машинах, они выполняются в различных адресных пространствах, что тут же рождает проблемы. Параметры и результаты также передаются от машины к машине, что может вызвать свои затруднения, особенно если машины не одинаковы. Наконец, обе машины могут сбоить, и любой возможный сбой вызовет разнообразные сложности. Однако с большинством из этих проблем можно справиться, и RPC является широко распространенной технологией, на которой базируются многие распределенные системы. |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 638. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |