|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
КОРОТКІ ТЕОРЕТИЧНІ ВІДОМОСТІСтр 1 из 4Следующая ⇒ МІНІСТЕРСТВО ОСВІТИ І НАУКИ, МОЛОДІ ТА СПОРТУ УКРАЇНИ Запорізький національний технічний університет
МЕТОДИЧНІ ВКАЗІВКИ до лабораторних робіт з дисципліни «Теорія прийняття рішень» для студентів спеціальності 7.05010301 “Програмне забезпечення систем” всіх форм навчання
2012 ЗМІСТ Вступ. 2 Лабораторна робота № 1. Евристичний алгоритм класифікації з використанням даних навчального експерименту 4 Лабораторна робота № 2. Оптимальна оцінка значення прогнозованого параметра 8 Лабораторна робота № 3. Оптимальна класифікація. 12 Лабораторна робота № 4. Метод дискримінантних функцій. 19 Лабораторна робота № 5. Метод потенціальних функцій. 23 Література. 28 ВСТУП
Для завоювання українським виробником твердих позицій на європейському ринку необхідно пройти певні етапи, а саме, позбутися такого серйозного недоліку, як високий рівень дефектності вітчизняної продукції. Ефективним засобом проти даного недоліку є діагностика процесів і виробів [1-13]. Ефективним елементом технічної діагностики є методи й алгоритми розпізнавання. Великий внесок у розвиток теорії й практики розпізнавання образів внесли вітчизняні й закордонні вчені: В.М. Глушков, Н.П. Бусленко, О.Г. Івахненко, М.А. Айзерман, Е.М. Браверман, В.Н. Вапник, М.Г. Загоруйко, В.С. Михалевич, В.С. Пугачов, Ю.І. Журавльов, Я.З. Ципкін, М.М. Бонгард, В.Л. Матросов, Л.А. Растрігін, О.Л. Горелик, І.Б. Гурвич, В.О. Скрипкін, О.Я. Червоненкис, С.А. Айвазян, В.М. Васильєв, О.О. Харкевич, Ф. Розенбат, Р. Гонсалес, Х. Гренандер, Р. Дуда, Г. Себестіан, Дж. Ту, К. Фу, П. Харт, К. Фукунага та ін. [14-59].  У даному лабораторному практикумі представлено ряд методів і алгоритмів теорії розпізнавання образів. При відборі цих методів і алгоритмів для включення в даний цикл лабораторних робіт враховувався той факт, що зусилля потрібно спрямовувати, у першу чергу, на створення простих не елітарних методик, адресно розрахованих на певні категорії працівників (топ-менеджерів, інженерів, технологів, робітників). Спрощена й навіть менш ефективна методика за рахунок масовості її застосування виграє у більш ефективної, але складної.
Лабораторна робота № 1.
Мета роботи – вивчити один із евристичних алгоритмів індивідуального прогнозування – класифікацію за однією ознакою з використанням даних навчального експерименту; навчитися обирати оптимальне порогове значення ознаки.
КОРОТКІ ТЕОРЕТИЧНІ ВІДОМОСТІ
Дана робота відкриває цикл робіт, присвячених вирішенню задачі індивідуального прогнозування. У наш час чималі можливості прогнозування привертають увагу широкого кола фахівців як в області дослідження, розробки й теоретичного обґрунтування методів прогнозування, так і в області їхнього практичного застосування у виробництві й експлуатації. Використання індивідуального прогнозування у виробництві дозволяє усунути потенційно ненадійні вироби з готової продукції, що саме по собі є дуже важливим, тому що сприяє підвищенню ефективності експлуатації. Крім того, аналіз причин випуску потенційно ненадійних виробів дозволяє оперативно впливати на виробництво, тому що з'являється можливість науково обґрунтованого керування якістю продукції, що випускається, за рахунок введення зворотного зв'язку від прогнозування до виробництва. Мета індивідуального прогнозування в експлуатації полягає в запобіганні відмовам і збільшенні строків між профілактичними роботами шляхом виявлення й виключення з експлуатації потенційно ненадійних екземплярів з погіршеними значеннями параметрів і інтенсивним старінням. При оптимальній класифікації за однією ознакою для вирішення задачі індивідуального прогнозування необхідно знати двовимірну густину розподілу ознаки й параметру, що прогнозується. В методі оптимальної класифікації аналітично знаходиться таке порогове значення ознаки, при якому величина середніх втрат мінімальна. Однак аналітичні перетворення, необхідні при цьому, навіть при одній ознаці й нормальному спільному законі є досить складними. Якщо ж спільна густина невідома, то необхідно провести статистичний експеримент для визначення оцінки густини розподілу. У даній лабораторній роботі розв'язання задачі класифікації за однією ознакою здійснюється за даними навчального експерименту. При цьому немає необхідності прибігати до складних аналітичних перетворень і статистичних експериментів з визначення оцінки спільної густини, якщо вона невідома. В даній роботі безпосередньо за даними навчального експерименту в ході іспиту підбирається таке порогове значення ознаки, при якому необхідна ймовірність помилкових рішень мінімальна відповідно до обраного критерію (зазвичай в якості такого критерію для підбора порогового значення ознаки обирається мінімум ризику споживача).
ДОМАШНЄ ЗАВДАННЯ
Використовуючи конспект лекцій та рекомендовану літературу, вивчити метод класифікації за однією ознакою з використанням даних навчального експерименту. Ознайомитися зі змістом і порядком виконання роботи.
ПОРЯДОК ВИКОНАННЯ РОБОТИ
3.1. Провести класифікацію резисторів, прийнявши в якості ознаки, що характеризує їхню стабільність, напругу фліккерного шуму Uш, а в якості прогнозованого параметру – коефіцієнт старіння α. Масив вихідних даних, отриманих у результаті навчального експерименту, приведено в таблиці 1.
Таблиця 1 – Дані навчального експерименту
При виконання завдання значення Uш помножити на номер варіанту. Порогове значення прогнозованого параметру Uш.кл дорівнює номеру варіанту. 3.2. Написати й налагодити програму в пакеті Matlab, яка реалізує: - побудову поля кореляції; - визначення числа вірних і помилкових рішень про віднесення екземплярів до того або іншого класу; - визначення ймовірностей помилкових і вірних рішень; - протоколювання результатів розрахунків у вигляді таблиці . 3.3. За даними навчального експерименту програмно реалізувати побудову поля кореляції ознаки X і прогнозованого параметра Y. 3.4. Задавшись одним з можливих порогових значень ознаки Xкл, для заданого порогового значення прогнозованого параметра Yгр виділити області рішень за класами К1 і К2, а також області (ріш К1/К2), (ріш К1/К1), (ріш К2/К2) , (ріш К2/К1). 3.5. Для заданого в п.3.4 Xкл знайти значення імовірності прийняття помилкових рішень Pпом . 3.6. Для значень Xкл у діапазоні від Xmin до Xmax визначити число вірних і помилкових рішень, що полягають у віднесенні екземплярів до класів К1 або К2, тобто n (ріш К1/К1), n (ріш К2/К2), n (реш К1/К2), n (ріш К2/К1), а також загальне число рішень, прийнятих про віднесення екземплярів, відповідно, до класу К1 і К2 – n (ріш К1), n (ріш К2). 3.7. Для значень Xкл у діапазоні від Xmin до Xmax знайти імовірності помилкових і вірних рішень Р(К1/ріш К2), Р(К2/ріш К1), Р(ріш К1/К2), Р(ріш К2/К1), Рпом , Рвірн , а також імовірності Р(ріш К1), Р(ріш К2). 3.8. Результати, отримані в п.п. 3.6 та 3.7, програмно представити у вигляді таблиці. 3.9. Представити результати, отримані у п.3.8, у графічному вигляді. 3.10. Проаналізувати отримані результати й вибрати оптимальне значення Xкл(опт), при якому імовірність прийняття вірних рішень буде максимальною.
ЗМІСТ ЗВІТУ 4.1. Сформульована мета роботи. 4.2. Текст програми, що реалізує етапи роботи, зазначені в п.п. 3.2, 3.6, 3.7, 3.8. 4.3. Роздруківки результатів роботи програми, таблиця, графіки. 4.4. Аналіз отриманих результатів і висновки.
КОНТРОЛЬНІ ЗАПИТАННЯ 1. Для вирішення задачі оптимальної класифікації за однією ознакою повинна бути відома двовимірна густина розподілу ознаки й прогнозованого параметру. Що є вихідною інформацією при вирішенні задачі класифікації за однією ознакою з використанням евристичного алгоритму? 2. Що є критерієм для вибору порогового значення ознаки при класифікації за однією ознакою з використанням евристичного алгоритму? 3. У чому полягає навчальний експеримент при прогнозуванні стабільності резисторів? Що при цьому є ознакою й прогнозованим параметром? 4. Охарактеризуйте імовірності прийняття помилкових і вірних рішень при класифікації за однією ознакою з використанням евристичного алгоритму. 5. Назвіть способи зменшення ризику споживача й імовірності прийняття помилкових рішень 6. Яким повинен бути об'єм навчальної вибірки для вирішення задачі класифікації? Від яких факторів він залежить? Лабораторна робота № 2.
Мета роботи– вивчити індивідуальне прогнозування за ознаками з оцінкою значення прогнозованого параметра із використанням теорії статистичних оцінок; для оптимального прогнозування у випадку, коли ознака й прогнозований параметр мають спільний нормальний розподіл, детально дослідити властивості оптимальної оцінки прогнозованого параметра, а також вплив на неї конкретного значення ознаки.
КОРОТКІ ТЕОРЕТИЧНІ ВІДОМОСТІ
У даній лабораторній роботі досліджується класичний статистичний метод, що базується на теорії статистичних оцінок і дає оптимальне розв’язання задачі індивідуального прогнозування. Для дослідження цього методу фахівець повинен мати у своєму розпорядженні багатовимірні умовні густини розподілу прогнозованого параметра та ознак.
ДОМАШНЄ ЗАВДАННЯ
Використовуючи конспект лекцій та рекомендовану літературу, вивчити теорію статистичного оцінювання і її використання при вирішенні задачі індивідуального прогнозування за ознаками з оцінкою значення прогнозованого параметра. Ознайомитися зі змістом і порядком виконання роботи.
ПОРЯДОК ВИКОНАННЯ РОБОТИ
3.1. За номером у журналі обрати варіант завдання для оптимального оцінювання прогнозованого параметра Y, коли початковий стан виробу оцінюється однією ознакою X, і спільна густина розподілу цієї ознаки й прогнозованого параметра підкоряється двовимірному нормальному закону. Вихідними даними є наступні параметри: - математичне сподівання ознаки Mx; - математичне сподівання прогнозованого параметру My; - дисперсія ознаки D[x]; - дисперсія прогнозованого параметра D[y]; - коефіцієнт кореляції між ознакою й прогнозованим параметром r; - значення ознаки X(J). 3.2. Написати й налагодити програму в пакеті Matlab, яка знаходить: - спільну густину розподілу ознаки й прогнозованого параметру W(x,y) ; - одновимірні густини розподілу ознаки й параметру W(x) , W(y); - умовну густину розподілу прогнозованого параметра за умови, що ознака прийняла деяке значення W(y/x); - дисперсію похибки прогнозування D[ D - умовне математичне сподівання прогнозованого параметра M[ - умовну дисперсію прогнозованого параметру D[ 3.3. Визначити залежність дисперсії похибки прогнозування від величини коефіцієнта кореляції r між ознакою й прогнозованим параметром і від дисперсії прогнозованого параметру D[y]. Значення дисперсії похибки прогнозування визначити для | r | = 0; 0.1; 0.2; 0.3; 0.4; 0.5; 0.6; 0.7; 0.8; 0.9; 1.0 і для D[y]1= D[y], D[y]2=2·D[y], D[y]3=4·D[y]. Розраховані залежності надати у вигляді таблиці й графіка. Проаналізувати одержані результати. 3.4. Розрахувати значення кривої безумовної густини розподілу прогнозованого параметра W(y) для y=My; My ± 0.2sy; My ± 0.4sy; My ± 0.6sy; My ± 0.8sy; My ± sy; My ± 2sy; My ± 3sy. 3.5. Розрахувати значення кривих густин умовного розподілу W(y/x(j)) для двох значень коефіцієнта кореляції між ознакою й прогнозованим параметром r1 і r2 і чотирьох значень ознаки X(1), X(2), X(3), X(4) для y = M[ Результати розрахунків надати у вигляді таблиці. 3.6. Показати графічно розраховані в п.п.3.4. і 3.5. густини розподілу. Проаналізувати, як змінюється розташування умовної густини відносно одномірної безумовної густини розподілу прогнозованого параметру в залежності від коефіцієнта кореляціїr і конкретного значення ознаки j-го екземпляру X(j). Проаналізувати, як впливає ступінь залежності ознаки й прогнозованого параметра на дисперсію умовного розподілу параметра. 3.7. Використовуючи спільну густину розподілу ознаки й прогнозованого параметру W(x,y) для значення ознаки Х(2) визначити оптимальну оцінку значення прогнозованого параметра Y*(j)опт. Нагадаємо, що в якості Y* (j)опт прогнозованого параметра Y(j) береться найбільш імовірне значення випадкової величини Для знаходження оптимальної оцінки прогнозованого параметру використати наступні методи одномірного пошуку оптимуму: - метод розподілу інтервалу навпіл; - метод Пауела; - метод Ньютона-Рафсона. 3.8. Беручи до уваги той факт, що для нормального розподілу мода умовної густини розподілу W(y/x(j)) (найбільш імовірне значення випадкової величини 3.9. З огляду на те, що знайдене в пункті 3.8. значення є оптимальною оцінкою прогнозованого параметру, оцінити точність використаних (див. п. 3.7) методів пошуку оптимуму (знайти абсолютну й відносну похибки).
ЗМІСТ ЗВІТУ
4.1. Сформульована мета роботи. 4.2. Текст програми, що реалізує етапи роботи зазначені в п.3.2. 4.3. Роздруківки результатів роботи програми, таблиці, графіки. 4.4. Аналіз отриманих результатів і виводи.
КОНТРОЛЬНІ ЗАПИТАННЯ
1. Яку інформацію повинен мати дослідник для вирішення задачі індивідуального прогнозування за ознаками з оцінкою значення прогнозованого параметра методами теорії статистичних оцінок? 2. У якому випадку доцільно ставити задачі прогнозування значення параметра за ознаками? 3. Який вигляд має багатовимірна густина розподілу при незалежності прогнозованого параметра від кожної з ознак? 4. Що береться в якості кількісної міри точності прогнозування? 5. Який вигляд має аналітична залежність між багатовимірною спільною густиною розподілу значень ознак і прогнозованого параметра, умовною густиною розподілу прогнозованого параметра та густиною спільного розподілу ознак? 6. Чому дисперсія, обчислена за умовною густиною розподілу прогнозованого параметра, буде менше дисперсії, обчисленої за одновимірною густиною розподілу прогнозованого параметра? Від чого залежить розходження між цими дисперсіями? 7. Який параметр обирається в якості кількісної міри оптимальної оцінки прогнозованого параметра? 8. Проілюструйте графічно ефективність прогнозування за допомогою умовної густини в порівнянні з оцінкою параметра за безумовною густиною розподілу прогнозованого параметра? 9. Чим визначається розташування умовної густини відносно безумовної густини розподілу прогнозованого параметра? 10. У якому випадку моди умовної й безумовної густин збігаються? 11. З якими проблемами доводиться мати справу дослідникові при практичному використанні оптимальної оцінки прогнозованого параметра? Лабораторна робота № 3.
Мета роботи – вивчити теорію статистичної класифікації; навчитися застосовувати теорію статистичної класифікації для вирішення задач індивідуального прогнозування за ознаками.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 324. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
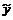 ];
];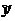 /
/ 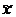 ];
];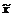 ].
].