|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Use Socket; #загрузить inet_addrs{ # ( #Сохранить имя хоста в $1 (?: #Группирующие скобки (?! [-_] ) #ни подчеркивание, ни дефис [\w-] + #кусок имени хоста \. #и точка домена )+ #повторить несколько раз [A-Za-z] #следующий символ - буква [\w-]+ #домен верхнего уровня ) #конец записи $1 }{ #Заменить следующим: "$1" . #исходн часть + пробел (($addr = gethostbyname($1)) #Если имеется адрес ? "[" . inet_ntoa($addr). "]"#отформатировать : "[???]" #иначе пометить как сомнительный ) }gex
Переписываем исходную программу с учетом вышеприведенного кода:
#!/usr/bin/perl -wT $url0="http://www.job.ru/cgi/list1.cgi?GR_NUM="; $url1="%31&TOPICID=9&EDUC=2&TP=&Gr=&SEX=&AGEMIN=23&AGEMAX=&MONEY=200&CDT="; $url2="&LDAY=99&ADDR=%ED%CF%D3%CB%D7%C1&KWORD=&KW_TP=AND"; use Socket; use LWP::Simple; foreach($i=1; $i<=57; $i++){ $plus.="%31%2B"; $test=$url0.$plus.$url1.$url2,"\n"; @mass=grep{s/(.*) ([\w+\-\.]+\@[\w+\-\.]+\.\w{2,3})(.*)/$2/ig} split /\n/, get "$test"; $test1.=join "\n", @mass; $test1.="\n"; } @res=split /\n/, $test1; @un=grep{!$test{$_}++} @res; foreach $file(@un){ $file=~s/(.*)\@(.*)/www\.$2/; =pod $file=~s{((?:(?![-_])[\w-]+\.)+[A-Za-z][\w-]+)} {"$1".(($addr=gethostbyname($1))?"[".inet_ntoa($addr)."]":"[???]")}gex; print $file,"\n" if($file !~/\?\?\?/); =cut $file=~s{ ( (?: (?![-_]) [\w-]+ \. )+ [A-Za-z] [\w_]+ ) }{ "$1". (($addr = gethostbyname($1)) ? "[".inet_ntoa($addr)."]" : "[???]" ) }gex; print $file,"\n" if($file !~/\?\?\?/); }
Между строчками можно комментировать целые куски кода.
=pod $file=~s{((?:(?![-_])[\w-]+\.)+[A-Za-z][\w-]+)}  {"$1".(($site=gethostbyname($1))?"[".inet_ntoa($site)."]":"[???]")}gex; print $file,"\n" if($file !~/\?\?\?/); =cut
Эта программа успешно удалила некоторые из адресов, которые Socket.pm показались подозрительными. Если научится читать сложные регулярные выражения, то можно написать полный регексп е-mail адресов, который занимается тем, что выделяет адреса в точности с соответствующим RFC(занимает это регулярное выражение несколько страниц). Ключи, которые использовались в вышеприведенном регулярном выражении g - глобальная замена е – выполнение x - улучшенное форматирование. Если написать это регулярное выражение в одну строчку, то оно вряд ли там поместится:
s{((?:(?![-_])[\w-]+\.)+[A-Za-z][\w-])}#здесь силовой перевод каретки {"$1".(($addr=gethostbyname($1))?"[".inet_ntoa($addr)."]":"[???]")}gex
Разберем один интересный момент в данном регекспе:
s/regex/условие?да:иначе/
Тут проявляется, пожалуй, одна из действительно сильнейших особенностей regex, возможность в одном регулярном выражении избежать многострочных условий с циклом. В приведенном примере работает все примерно так: Если $addr=gethostbyname($1) - да, то ставить ip-адрес(inet_ntoa($addr)), если нет(не откликнулся сервер, сбой на линии и т. д.) то отметить этот урл как подозрительный [???]. В принципе в программе ничего человеку делать не нужно, т.к. подозрительные отметаются условием print $file,"\n" if($file !~/\?\?\?/); Общее время работы программы 10-15 минут. Простое решение для зеркала новостной ленты Допустим, нужно сделать зеркало какой-либо зарубежной новостной ленты вместе с загрузкой картинок с удаленного сервера, чтобы не ждать по несколько минут отображения содержимого полностью загруженной большой таблицы. Приведенный скрипт запускается при помощи crontab каждые 5 часов:
#!/usr/bin/perl -w $/="\001"; print "content-type: text/html\n\n"; $dir="/var/www/docs/html/news/images"; $imgurl="http://www.qwerty.ru/news/images"; use LWP::Simple; use LWP::UserAgent; $page=get "http://www.astronomynow.com"; $page=~s/face="(.*?)"//igs; &getimg($page); $page=~s!/images/grafix/listdot.gif!../../listdot.gif!igs; $page=~s!/images/grafix/spacer.gif!../../spacer.gif!igs; $page=~s!images/grafix/spacer.gif!../../spacer.gif!igs; if($page=~m!<TABLE BORDER="0" CELLPADDING="0" CELLSPACING="0">(.*?)</TD></TR></TABLE>!igsm){ $file=$1; &getlink($page); foreach $names(@res){ $names=~s|.*/||ig; $file=~s|src="http://(.*?)$names"|src=$imgurl/$names|igs; } $html=qq~ <TABLE BORDER="0" CELLPADDING="0" CELLSPACING="0"> $file </TD></TR></TABLE>~; } open F, ">$dir/news.txt"; print F $html or die "\n\n\n ERROR: $!\n\n\n"; close F; sub getimg{ &getlink($_[0]); foreach $img(@res){ my $res = LWP::UserAgent->new->request(new HTTP::Request GET => $img); if ($res->is_success) { $img=~s|.*/||; open (ABC, ">$dir/$img") or die "\n\n\nERROR: $!\n\n\n"; binmode(ABC); print ABC $res->content; close ABC or die "\n\n\nERROR: $!\n\n\n"; } else { print $res->status_line; } } return @res; } sub getlink{ local $_=$_[0]; push(@res, "http://$2") while m{SRC\s*=\s*(["'])http://(.*?)\1\s*(.*?)HEIGHT="100"(.*?)>}igs; return @res; }
Вывод результатов поиска Предположим, есть необходимость подсветить результаты поиска в файлах, подобно тому, как это делает поисковик aport. Данное регулярное выражение позволяет реализовать эту красивую функцию для поисковика, но оно имеет очень большой минус, при обработке текста машина начинает тормозить, но мы рассмотрим этот регексп из общих соображений:
$sn=4; { local $_=$description1; print "...$1<font color=red>$3</font>$4..." while(m/(([\s,\.\n^]*\w*){$sn})(\s*$query\s*)(([\s,\.\n^]*\w+){$sn})/ig); } $_="";
Исходная задача состоит в следующем: вывести по 4 слова спереди и сзади результата поиска, причем так, чтобы если слово находится первым, то будет видно 4 слова позади него. В точности такое же условие и для последнего слова. Соответственно из вида регекспа понятно, что разделителями слов могут быть символы [\s,\.\n^]*, в том числе и символ перевода каретки ^. Комбинация (\d\d\d){$sn} значит, что нужно найти 3 цифры три раза.
Задания для выполнения
Разработать perl-скрипты в соответствии с вариантом задания. Для второго задания из каждого варианта осуществить вывод результата в файл.
Варианты индивидуальных заданий.
1. Задание 1. Даты три номерных знака автомашин. Найти номерной знак, содержащий буквы "МОН" и вывести его на печать. Если такого знака среди заданных нет, то напечатать соответствующее сообщение. Задание 2. Даны x1, x2, …, x10.Определить: 2. Задание 1. Даны три марки автомашин. Определить, есть ли среди них марка "ВАЗ2101". Вывести соответствующее сообщение. Задание 2. Даны y1, y2, …, y9.Определить:
3. Задание 1. Даны четыре слова одинаковой длины. Напечатать сообщение о наличии или отсутствии одинаковых слов и это слово. Задание 2. Даны x1, x2, …, x5 ;y1, y2, …, y8.Определить:
4. Задание 1. Даны четыре фамилии. Определить, есть ли среди них фамилия ИВАНОВ. Напечатать соответствующее сообщение. Задание 2. Даны массивы L1, …, L7 и Y1, …, Y5.Определить:
5. Задание 1. Даны наименования трёх вузов. Определить, есть ли среди них МАДИ. Напечатать соответствующее сообщение. Задание 2. Даны α1, α2, …, α8; γ1, γ2, …, γ5.Определить:
6. Задание 1. Даны наименования четырех факультетов. Определить, имеется ли среди них ДСФ и вывести об этом соответствующее сообщение. Задание 2. Даны x1, x2, …, x8 ; y1, y2, …, y8. Определить:
7. Задание 1. Даны три слова. Определить и вывести слова, которые состоят из пяти букв. Задание 2. Даны а1, а2, …, а6.Определить:
8. Задание 1. Даны три слога, каждый из двух букв и слово из 6 букв. Составить из слогов возможные слова и определить, получается ли заданное слово. Вывести соответствующее сообщение. Задание 2. Даны x1, x2, …, x10; y1, y2, …, y5.Определить:
9. Задание 1. Дано слово из пяти букв. Сколько раз встречаются идущие подряд буквы "НН"? Задание 2. Даны x1, x2, …, x10; l1, l2, …, l10.Определить:
10. Задание 1. Даны номерные знаки 4 автомашин. Определить, имеются ли среди них одинаковые, вывести их или сообщение, что таких - нет. Задание 2. Даны l1, l2, …, l8; n1, n2, …, n5; m1, m2, …, m5.Определить:
11. Задание 1. Даны номерные знаки трёх автомашин. Определить, есть ли среди них знак Задание 2. Даны m1, m2, …, m7.Определить:
12. Задание 1. Даны три фамилии Р1, Р2, Р3 и три имени М1, М2, М3 соответственно фамилиям. Определить, есть ли среди них фамилия и имя Р4 М4. Задание 2. Даны β1, β2, …, β8; γ1, γ2, …, γ7 .Определить:
13. Задание 1. Даны три английских слова А1, А2, А3 и их русских перевод Р1, Р2, Р3. Напечатать перевод заданного английского слова А4 (А4 = А1 или А2 или А3). Задание 2. Даны x1, …, x5; y1, …, y5; z1, …, z5.Определить:
14. Задание 1. Дано слово длиной в 4 символа. Определить, является ли первый или последний символ слова буквой "А". Напечатать соответствующие сообщения. Задание 2. Даны x1, …, x10; α1, …, α10; a, b.Определить:
15. Задание 1. Даны три одинаковых слова, но в одном из них может быть допущена ошибка. Вывести соответствующее сообщение и слово с ошибкой. Задание 2. Даны x1, …, x7; l1, …, l5; a, b.Определить:
16. Задание 1.Даны три фамилии. Определить, есть ли среди них фамилии, начинающиеся на букву 'М’. Вывести найденные фамилии. Если таковых нет, вывести соответствующее сообщение, Задание 2.Даны С1, … , С9 ; d1, … , d9 ; f. Определить:
.
17. Задание 1.Даны три слова одинаковой длины, начинающиеся на буквы 'А', 'B', 'K' в любом порядке следования. Вывести их в алфавитном порядке. Задание 2. Даны b1, ... , b10; d1, ... , d7; A. Определить:
18. Задание 1.Даны четыре слова. Напечатать слово, имеющее максимальную длину. Задание 2.Даны массивы α1, … , α8 ; β1 , … , β8. Определить:
;
19. Задание 1. Дано слово длиной 8 символов. Определить, содержит ли оно слог "кн". Вывести это слово или сообщение. Задание 2.Даны α1, ... , α10 ; b. Определить: S = 20. Задание 1. Дано слово длиной пять символов. Определить, есть ли в нём буква 'М’ или буква ‘Н’. Вывести соответствующее сообщение. Задание 2. Даны a1, ... , a12 ; b1, ... , b10. Определить:
21. Задание 1. Задана запись одного оператора. Проверить наличие символа точка с запятой. Вывести соответствующие сообщения. Задание 2. Даны массивы R1, ... , R9 ; f1, ... , f9 ; d1, ... , d7.Определить :
22. Задание 1. Дано слово из четырех символов. Сколько раз встречается в нем заданный символ? Вывести соответствующее сообщение. Задание 2. Даны массивы d1, ... , d12 ; f1, ... , f8 и переменная Т.Определить:

23. Задание 1. Предложение описано символьной переменной заданной длиной. Определить, встречается ли запятая? Задание 2.Даны массивы P1, ... , P12 ; q1, ... , q12.Определить:
24. Задание 1. Даны два слова, одинаковых по значению, в одном из них сделана ошибка. Определить, в какой позиции ошибочный символ. Задание 2. Даны массивы f1, … , f14 ; l1, … , l7.
25. Задание 1. В строке символов определить наличие гласных букв. Задание 2. Даны массивы t1, … , t20; V1, ... , V20. Определить: 26. Задание 1. Дан номерной знак автомобиля в виде строки символов. Определить, имеется ли в нём сочетание цифр 92. Выдать соответствующее сообщение. Задание 2. Даны массивы α1, ... , α15 ; γ1, ... ,γ7. Определить
27. Задание 1. Даны три фамилии. Определить фамилии, начинающиеся с гласной буквы. Сделать соответствующее сообщение. Задание 2. Дан массив K1, ... , K10.Определить:
28. Задание 1. В слове из четырех букв определить номер позиции, в которой находится буква «а» (два способа!). Задание 2. Дан массив M1, ... , M20.Определить:
лАБОРАТОРНАЯ РАБОТА №5 сервер сценариев WindowsScriptingHost. методы объектов wscriptshell и wshnetwork Цель работы
Овладеть навыками работы сервером сценариев Windows, изучить возможности сервера сценариев, режимы выполнения сценариев и методы объекта WscriptShell иWshNetwork. Общие сведения Основные положения
Долгое время для выполнения однотипных задач в среде Windows и DOS служили командные (пакетные) BAT-файлы. Основным их недостатком были примитивный DOS-интерфейс – отсутствие интерактивности, и довольно ограниченные возможности по работе с WINDOWS (трудность работы в сети, с ярлыками, с реестром и т.д.). Ситуация изменилась, когда Microsoft разработала Сервер Сценариев (Windows Scripting Host), который должен служить для автоматизации работы с повторяющимися процессами. Сам Windows Scripting Host не является языком как таковым, он только представляет свойства и методы для работы в Windows, которые могут использоваться другими языками сценариев. Наиболее удобными и предназначенными для этого явились ранее разработанные самой Microsoft языки сценариев Visual Basic Scripting Edition (VBScript) и JScript. Раньше языки VBScript и JScript по своим возможностям были очень близки к Visual Basic for Applications - они также могли быть вызваны только из MS Internet Explorer и нескольких других программ Microsoft, которые их поддерживали. С появлением Windows Scripting Host появилась возможность создавать для них отдельные сценарии, которые можно запускать и без Internet Explorer. Также преимуществом Windows Scripting Host является то, что для запуска сценариев требуется мало памяти и то, что файлы сценариев могут быть практически любого размера (содержать десятки тысяч строк). Еще одним преимуществом Windows Scripting Host является отсутствие среды разработки - не нужны компиляторы, редактирование сценариев может производиться в любом текстовом редакторе, способном работать с текстовыми файлами. Сервер сценариев предназначен для автоматизации повторяющихся задач и во многом, по сравнению с обычными языками программирования, обладает достаточно скромными возможностями. Но по сравнению с пакетными файлами DOS он обладает более широкими возможностями. Такими как: - вывод сообщений на экран; - запуск других программ; - работать с сетевыми дисками; - устанавливать принтеры; - работать с переменными окружения; - работать с реестром. В Windows 2000 и последующих версиях Windows Scripting Host установлен по умолчанию. Отключить его использование можно только удалением ассоциаций с его файлами. Установленный WindowsScriptHost поддерживает несколько видов файлов: vbs, vbe, js, jse, wsf, wsc и wsh. Все они (кроме vbe и jse) являются простыми текстовыми файлами и могут редактироваться в любом текстовом редакторе. Файлы .vbs и .js являются файлами, написанными на языке сценариев MS Visual Basic Script и MS JScript соответственно. Файлы vbe и jse– это vbs и js-файлы зашифрованные с помощью программы MS Script Encoder. Файлы с расширением .wsf – это файлы, содержащие XML-разметку для работы с WSH. Файлы wsc - Windows Script Components (WSC) позволяют упаковывать сценарии для использования их в качестве СОМ-компонентов. По сути, это те же wsf-файлы, еще и содержащие COM-компоненты. Файлы wsh являются файлами настроек Сервера Сценариев.
|
||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 761. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |







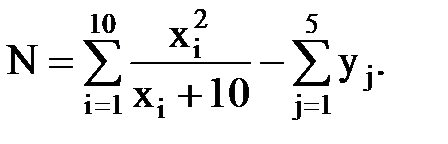

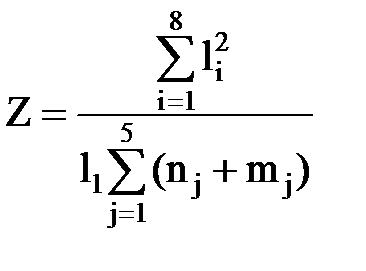






 .
. 
 .
.  ; di = S – (αi - b).
; di = S – (αi - b).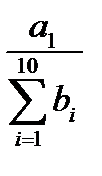
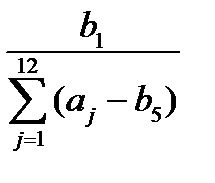





 ;
;  ;
;  .
.
 .
.