|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Учет при помощи организации битового вектораЧасто список свободных блоков диска реализован в виде битового вектора (bit map или bit vector). Каждый блок представлен одним битом, принимающим значение 0 или 1, в зависимости от того, занят он или свободен. Hапример, 00111100111100011000001 ... . Главное преимущество этого подхода состоит в том, что он относительно прост и эффективен при нахождении первого свободного блока или n последовательных блоков на диске. Многие компьютеры имеют инструкции манипулирования битами, которые могут использоваться для этой цели. Hапример, компьютеры семейств Intel и Motorola имеют инструкции, при помощи которых можно легко локализовать первый единичный бит в слове. Описываемый метод учета свободных блоков используется в Apple Macintosh. Несмотря на то что размер описанного битового вектора наименьший из всех возможных структур, даже такой вектор может оказаться большого размера. Поэтому данный метод эффективен, только если битовый вектор помещается в памяти целиком, что возможно лишь для относительно небольших дисков. Например, диск размером 4 Гбайт с блоками по 4 Кбайт нуждается в таблице размером 128 Кбайт для управления свободными блоками. Иногда, если битовый вектор становится слишком большим, для ускорения поиска в нем его разбивают на регионы и организуют резюмирующие структуры данных, содержащие сведения о количестве свободных блоков для каждого региона. Учет при помощи организации связного списка Другой подход - связать в список все свободные блоки, размещая указатель на первый свободный блок в специально отведенном месте диска, попутно кэшируя в памяти эту информацию. Подобная схема не всегда эффективна. Для трассирования списка нужно выполнить много обращений к диску. Однако, к счастью, нам необходим, как правило, только первый свободный блок.  Иногда прибегают к модификации подхода связного списка, организуя хранение адресов n свободных блоков в первом свободном блоке. Первые n-1 этих блоков действительно используются. Последний блок содержит адреса других n блоков и т. д. Существуют и другие методы, например, свободное пространство можно рассматривать как файл и вести для него соответствующий индексный узел. Размер блока Размер логического блока играет важную роль. В некоторых системах (Unix) он может быть задан при форматировании диска. Небольшой размер блока будет приводить к тому, что каждый файл будет содержать много блоков. Чтение блока осуществляется с задержками на поиск и вращение, таким образом, файл из многих блоков будет читаться медленно. Большие блоки обеспечивают более высокую скорость обмена с диском, но из-за внутренней фрагментации (каждый файл занимает целое число блоков, и в среднем половина последнего блока пропадает) снижается процент полезного дискового пространства. Для систем со страничной организацией памяти характерна сходная проблема с размером страницы. Проведенные исследования показали, что большинство файлов имеют небольшой размер. Например, в Unix приблизительно 85% файлов имеют размер менее 8 Кбайт и 48% - менее 1 Кбайта. Можно также учесть, что в системах с виртуальной памятью желательно, чтобы единицей пересылки диск-память была страница (наиболее распространенный размер страниц памяти - 4 Кбайта). Отсюда обычный компромиссный выбор блока размером 512 байт, 1 Кбайт, 2 Кбайт, 4 Кбайт. Структура файловой системы на диске Рассмотрение методов работы с дисковым пространством дает общее представление о совокупности служебных данных, необходимых для описания файловой системы. Структура служебных данных типовой файловой системы, например Unix, на одном из разделов диска, таким образом, может состоять из четырех основных частей (см. рис. 12.5).
В начале раздела находится суперблок, содержащий общее описание файловой системы, например: · тип файловой системы; · размер файловой системы в блоках; · размер массива индексных узлов; · размер логического блока. Описанные структуры данных создаются на диске в результате его форматирования (например, утилитами format, makefs и др.). Их наличие позволяет обращаться к данным на диске как к файловой системе, а не как к обычной последовательности блоков. В файловых системах современных ОС для повышения устойчивости поддерживается несколько копий суперблока. В некоторых версиях Unix суперблок включал также и структуры данных, управляющие распределением дискового пространства, в результате чего суперблок непрерывно подвергался модификации, что снижало надежность файловой системы в целом. Выделение структур данных, описывающих дисковое пространство, в отдельную часть является более правильным решением. Массив индексных узлов (ilist) содержит список индексов, соответствующих файлам данной файловой системы. Размер массива индексных узлов определяется администратором при установке системы. Максимальное число файлов, которые могут быть созданы в файловой системе, определяется числом доступных индексных узлов. В блоках данных хранятся реальные данные файлов. Размер логического блока данных может задаваться при форматировании файловой системы. Заполнение диска содержательной информацией предполагает использование блоков хранения данных для файлов директорий и обычных файлов и имеет следствием модификацию массива индексных узлов и данных, описывающих пространство диска. Отдельно взятый блок данных может принадлежать одному и только одному файлу в файловой системе. Реализация директорий. Как уже говорилось, директория или каталог это файл, имеющий определенный тип и хранящий список входящих в него файлов или каталогов. Основная задача файлов-директорий поддержка иерархической древовидной структуры файловой системы. Запись в директории имеет определенный для данной ОС формат, зачастую неизвестный пользователю, поэтому блоки данных файла-директории заполняются не через операции записи, а при помощи специальных системных вызовов (например, создание файла). Для доступа к файлу ОС использует путь (pathname), сообщенный пользователем. Запись в директории связывает имя файла или имя поддиректории с блоками данных на диске. В зависимости от системы эта ссылка может быть дисковым адресом целого файла (непрерывное расположение), номером первого блока (связанный список), или номером индексного узла. Во всех случаях главная функция системы директорий - трансформировать символьное имя файла в информацию, необходимую, чтобы найти данные. Отдельная проблема способ хранения атрибутов файла. Иногда их хранят непосредственно в записи в директории. Для системы с индексными узлами можно хранить атрибуты в индексном узле, а не в записи в директории. Как мы увидим позже, этот метод имеет ряд преимуществ при организации совместного доступа к файлам. Рассмотрим несколько конкретных примеров. 12.4.1 Примеры реализация директорий в некоторых ОС Директории в ОС CP/M В ОС CP/M только одна директория. Каждая запись - строка содержит следующие поля: идентификатор собственника, имя файла, тип файла, поле extent, которое показывает, хватит ли для идентификации файла одной строки или нужны еще, число блоков, номера блоков. То есть адреса всех блоков файла перечислены в записи в директории! Директории в ОС MS-DOS В ОС MS-DOS типовая запись в директории имеет вид:
Рис. 12.7 Вариант записи в директории MS-DOS В ОС MS-DOS, как и в большинстве современных ОС, директории могут содержать поддиректории (специфицируемые битом атрибута), что позволяет конструировать произвольное дерево директорий файловой системы. Номер первого блока используется в качестве индекса в таблице FAT . Далее по цепочке могут быть найдены остальные блоки. Директории в ОС Unix Структура директории проста. Каждая запись содержит имя файла и номер его индексного узла. Вся остальная информация о файле (тип, размер, времен модификации, владелец и т. д. и номера дисковых блоков) находится в индексном узле.
Рис. 12.8 Вариант записи в директории Unix 12.4.2 Поиск в директории Итак, директория - есть файл, имеющий специальный формат, состоящий из записей фиксированной длины, где каждая запись соответствует одному из обычных файлов или директорий, входящих в состав данной директории. Как правило, список файлов в директории оказывается не упорядоченным по именам файлов. Поэтому правильный выбор алгоритма поиска имени файла в директории имеет большое влияние на эффективность и надежность файловых систем. Линейный поиск Совокупность записей о файлах в директории является линейным списком символьных имен файлов. Существует несколько стратегий просмотра такого списка. Простейшей из них является линейный поиск. Директория просматривается с самого начала, пока не встретится нужное имя файла. Хотя это наименее эффективный способ поиска, оказывается, что в большинстве случаев он работает с приемлемой производительностью. Например, авторы Unix утверждали, что вполне достаточно линейного поиска. По-видимому, это связано с тем, что на фоне относительно медленного доступа к диску, некоторые задержки, возникающие в процессе сканирования списка несущественны. Метод прост, но требует временных затрат. Для создания нового файла вначале нужно просканировать директорию на наличие такого же имени. Затем, имя нового файла вставляется в конец директории (если, разумеется, файл с таким же именем в директории не существует, в противном случае нужно информировать пользователя). Для удаления файла нужно также выполнить поиск его имени в списке и пометить запись как неиспользуемую. Реальный недостаток данного метода - линейный поиск файла. Информация о структуре директории используется часто, и плохая реализация будет замечена пользователями. Можно свести поиск к бинарному, если отсортировать список файлов. Однако это усложнит создание и удаление файлов, так как требуется перемещения большого объема информации. Хеш таблица Хеширование (см. например, [13]) - другой способ, который может быть использован для размещения и последующего поиска имени файла в директории. В данном методе имена файлов также хранятся в каталоге в виде линейного списка, но дополнительно используются хеш таблица. Хеш таблица, точнее построенная на ее основе хеш-функция позволяет по имени файла получить указатель на имя файла в списке. Таким образом, можно существенно уменьшить время поиска. В результате хеширования могут возникать коллизии, то есть ситуации, когда функция хеширования, примененная к разным именам файлов, дает один и тот же результат. Обычно имена таких файлов объединяют в связные списки, предполагая в дальнейшем осуществление в них последовательного поиска нужного имени файла. Выбор хорошего алгоритма хеширования позволяет свести к минимуму число коллизий. Однако всегда есть вероятность неблагоприятного исхода, когда непропорционально большому числу имен файлов функция хеширования ставит в соответствие один и тот же результат. В этом случае преимущество использования этой схемы по сравнению с последовательным поиском практически утрачиваются. Другие методы поиска Помимо описанных методов поиска имени файла в директории существуют и другие. В качестве примера можно привести организацию поиска в каталогах файловой системы NTFS при помощи, так называемого B-дерева, которое стало стандартным способом организации индексов в системах баз данных (см., например, [13]).
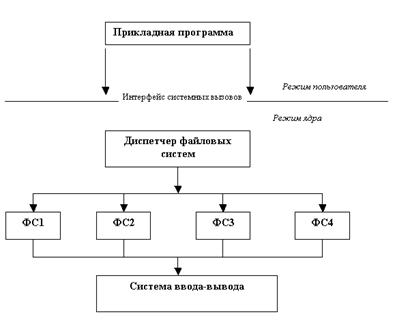
37. Современные архитектуры файловых систем. Современные ОС предоставляют пользователю возможность работать сразу с несколькими файловыми системами (Linux работает с Ext2fs, FAT и др.). Файловая система в традиционном понимании становится частью более общей многоуровневой структуры (см. рис. 12.12). На верхнем уровне, на котором располагается так называемый диспетчер файловых систем (например, в Windows 95 этот компонент называется installable filesystem manager). Он связывает запросы прикладной программы с конкретной файловой системой.
Рис. 12.13 Архитектура современной файловой системы Каждая файловая система (иногда говорят драйвер файловой системы) на этапе инициализации регистрируется у диспетчера, сообщая ему точки входа, для последующих обращений к данной файловой системе. Та же идея поддержки нескольких файловых систем в рамках одной ОС может быть реализована по-другому, например, исходя из концепции виртуальной файловой системы. Виртуальная файловая система (vfs) представляет собой независимый от реализации уровень и опирается на реальные файловые системы (s5fs, ufs, FAT, NFS, FFS, Ext2fs). При этом возникают структуры данных виртуальной файловой системы, типа виртуальных индексных узлов vnode, которые обобщают индексные узлы конкретных систем .
|
||
|
|
Последнее изменение этой страницы: 2018-05-30; просмотров: 461. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |