|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Прямой метод доступа (на примере хеширования)⇐ ПредыдущаяСтр 18 из 18
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского "to hash" - резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи организуются в виде таблицы, называемой хеш-таблицей. Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов. A. Требования Функцией хэширования (в широком смысле) называется функция 1. Сжатие – функция 2. Простота вычисления – для заданной функции Рассмотрим процедуру удаления записи из таблицы. A. Вставка, удаление и изменение данных
Элементы таблицы находятся в двух состояниях: свободно и занято. Если удалить элемент, переведя его в состояние свободно, то после такого удаления алгоритм поиска будет работать некорректно. Предположим, что ключ удаляемого элемента имеет в таблице ключи синонимы. В том случае, если за удаляемым элементом в результате  разрешения коллизий были размещены элементы с другими ключами и тем же самым адресом, то поиск этих элементов после удаления всегда будет давать отрицательный результат, так как алгоритм поиска останавливается на первом элементе, находящемся в состоянии свободно. Скорректировать эту ситуацию можно различными способами. Самый простой из них заключается в том, чтобы производить поиск элемента не до первого свободного места, а до конца таблицы. Однако такая модификация алгоритма сведет на нет весь выигрыш в ускорении доступа к данным, который достигается в результате хеширования. Другой способ сводится к тому, чтобы проследить адреса всех ключей-синонимов для ключа удаляемого элемента и при необходимости переместить соответствующие записи в таблице. Скорость поиска после такой операции не уменьшится, но затраты времени на само перемещение элементов могут оказаться очень значительными. Существует подход, который свободен от перечисленных недостатков. Его суть состоит в том, что для элементов хеш-таблицы добавляется состояние «удалено». Данное состояние в процессе поиска интерпретируется, как занято, а в процессе записи как свободно.
A. Разрешение коллизий Для разрешения коллизий используются различные методы, которые в основном сводятся к методам цепочек и открытой адресации. С хешированием мы сталкиваемся едва ли не на каждом шагу: при работе с браузером (список Web- ссылок), текстовым редактором и переводчиком (словарь), языками скриптов (Perl, Python, PHP и др.), компилятором (таблица символов). Метод цепочек Методом цепочек называется метод, в котором для разрешения коллизий во все записи вводятся указатели, используемые для организации списков цепочек переполнения. В случае возникновения коллизии при заполнении таблицы в список для требуемого адреса хеш-таблицы добавляется еще один элемент. Поиск в хеш-таблице с цепочками переполнения осуществляется следующим образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется последовательный поиск в списке, который связан с вычисленным адресом. Процедура удаления из таблицы сводится к поиску элемента и его удалению из цепочки переполнения. Пример. Даны следующие ключи 0596397 , 4957397, 3475397,… Используется метод цепочек. Метод открытой адресации Метод открытой адресации состоит в том, чтобы, пользуясь каким-либо алгоритмом, обеспечивающим перебор элементов таблицы, просматривать их в поисках свободного места для новой записи. а) Линейное рехеширование сводится к последовательному перебору элементов таблицы с некоторым фиксированным шагом c. a=(h(key) + c*i) mod N ,где i номер попытки разрешить коллизию. При c=1 происходит последовательный перебор всех элементов после текущего. Пример. Посмотрим, что произойдет, если мы захотим ввести в таблицу некоторый новый номер изделия 0596397. Используя хеш-функцию h(key):=key mod 1000, мы найдем, что h(0596397)=397 и что запись для этого изделия должна находиться в позиции 397 в массиве. Однако позиция 397 уже занята, поскольку там находится запись с ключом 4957397. Следовательно, запись с ключом 0596397 должна быть вставлена в таблицу в другом месте. Самым простым методом разрешения коллизий при хешировании является помещение данной записи в следующую свободную позицию в массиве. Например, запись с ключом 0596397 помещается в ячейку 398, которая пока свободна, поскольку 397 уже занята. Когда эта запись будет вставлена, другая запись, которая хешируется в позицию 397 (с таким ключом, как) или в позицию 398 (с таким ключом, как), вставляется в следующую свободную позицию, которая в данном случае равна 400. 397 4957397 398 0596397 399 8764397 400 2194398 При достижении последнего индекса таблицы, мы перескакиваем в начало, рассматривая её как «цикличный» массив. При большом количестве элементов с одинаковым значением адреса будет получены кластеры (блоки) - последовательности подряд идущих записей, соответствующих одному и тому же адресу. Вместо равномерного распределения записей по таблице будет получено распределение, кластеризованное в окрестностях некоторых точек, что снизит скорость поиска. Состояние таблицы при линейном рехешировании: Случайное рехеширование (частный случай) определяется формулой: а=(h(key)+r) mod N, где r – случайное число из некоторого фиксированного набора. Этот подход не способствует образованию больших блоков, скорее, объекты равномерно рассеиваются по таблице: Пример. Имеется следующая последовательность ключей: 18 177 38 56 23 27 8 48 Размер хеш-таблицы – 10 строк. Строки нумеруются с 0. Нарисовать состояние хэш- таблицы при использовании случайного рехеширование с числами r=4, 7, 1. Хеш-функция: h(ai)=ai mod N Формула для рехеширования: (h(ai)+r) mod N 0 27 (27+4=31) 1 2 38 (38+4=42) 3 23 4 5 8 (8+7=15) 6 56 7 177 8 18 9 48 (48+1=49)Для каждого нового ключа используется случайное число, стоящее в списке первым. Попробуем выполнить поиск числа 8. h(a)=8 mod 10=8 – неудачно h(a)=(8+4) mod 10=2 - неудачно h(a)=(8+7) mod 10=5 – удачно При использовании метода открытой адресации может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, так что будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой. б)Квадратичное рехеширование отличается от линейного тем, что шаг перебора элементов не линейно зависит от номера попытки найти свободный элемент a = (h(key) + c*i2) mod N Благодаря нелинейности такой адресации количество кластеров уменьшается. Однако даже относительно небольшое число проб может быстро привести к выходу за адресное пространство небольшой таблицы вследствие квадратичной зависимости адреса от номера попытки. в) Еще одна разновидность метода открытой адресации, которая называется двойным хешированием, основана на нелинейной адресации, достигаемой за счет суммирования значений основной и дополнительной хеш-функций a=h1(key) + i*h2(key) mod N
|
||
|
|
Последнее изменение этой страницы: 2018-05-29; просмотров: 364. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
 , удовлетворяющая минимум двум требованиям [1]:
, удовлетворяющая минимум двум требованиям [1]: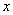 произвольной конечной длины в хэш-значение
произвольной конечной длины в хэш-значение  небольшой фиксированной длины, при этом входное сообщение будем называть прообразом.
небольшой фиксированной длины, при этом входное сообщение будем называть прообразом. вычисляется не выше чем с полиномиальной сложностью.
вычисляется не выше чем с полиномиальной сложностью.