|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Теорема сложения вероятностей совместных событий.Статистическое определение вероятности Пусть проводится серия опытов (n раз), в результате которой наступает или не наступает некоторое событие А (m раз), тогда отношение m/n, при n → называется статистической вероятностью события А. Вероятностью события называется число, около которого группируются значения частоты данного события в различных сериях большого числа испытаний. В случае статистического опред вероятность облад след св-ми: 1) вероятность достоверного события = 1, 2) вероятно невозможного соб = 0 3) вероятнслучсобзаключ между 0 и1. 4) вероятн суммы двух несовместных соб = сумме вероятностей этих соб.
4. Теорема сложения вероятностей.
Теорема сложения вероятностей несовместных событий. «Вероятность суммы несовместных событий равна сумме вероятностей этих событий» Р(А + В + …k) = Р(А) + Р(В) + …+ P(k), где А, В, …, k – несовместные. Доказательство.(сумма двух событий) Пусть в результате испытаний из общего числа n равновозможных и несовместных исходов испытаний А благоприятствует m1 случаев, а В – m2 случаев. Тогда вероятность события А (по классич. опр.) равна m1/n, а Р(В) = m2/n , т.к. события А и В несовместные, то ни один из случаев благоприятствующий событию А, не благоприятствует событию В, след. (А+В) благоприятствует (m1+m2) случая, след. Р(А+В) = (m1+m2)/n = m1/n + m2/n = P(A)+P(B) Следствие 1: Сумма вероятностей событий, образующих полную группу равна 1. Следствие 2: Сумма вероятностей противоположных событий так же равна 1. !!!Замечание: Рассмотренная теорема применима только для несовместных событий. Теорема сложения вероятностей совместных событий.  «Вероятность суммы двух совместных событий равна сумме вероятностей этих событий без вероятности их произведения» Р(А+В) = Р(А)+Р(В)-Р(АВ) А и В – совместные события Доказательство: Пусть n-число возможных исходов опыта; mА-число исходов благоприятствующих соб.А; mB-//-соб.В; mАВ – число исходов опыта, при котором происходят оба события, т.е. исходов благоприятных А*В, тогда число исходов, при котором имеет место событие А+В=mA+ mB- mAB (т.к. в сумме mA+mB, mAB учтено дважды: как исходы благоприятные А, и исходы благоприятные В
5. Сумма и произведение совместных событий и их геометрическая интерпретация.
6. Зависимые и независимые события. Теорема умножения вероятностей.
Опр.: условной вероятностью Теорема (умножения зависимых событий): вероятность произведения двух событий равна произведению вероятности одного события на условную вероятность другого, при условии, что 1-ое событие произошло: Доказательство: Пусть n-число возможных исходов опыта; mА-число исходов благоприятствующих соб.А; mB-//-соб.В, mАВ – число исходов опыта, при котором происходят оба события,. для вычисления условной вероятности
=> Пример: для поражения цели необходимо попасть в неё дважды. Вероятность 1-го попадания 0,2, затем она не меняется при промахах, но после 1-го попадания увеличивается в 2 раза. Найти вероятность того что цель будет поражена первыми двумя выстрелами. Решение: соб.А – попадания при первом выстреле Соб.В - //- при 2-ом выстреле
А и В совместные события
Пусть вероятность соб.В не зависит от появления соб.А Событие В называют независимым от события А, если появление соб.А не изменяет вероятности события В, т.е. если условная вероятность соб.В равна его безусловной вероятности:
т.е.условная вероятность соб.А в предположении, что наступило соб.В, равна его безусловной вероятности. Другими словами, соб.А не зависит от соб.В Итак, если соб.В не зависит от соб.А, то и соб.А не зависит от соб.В; это значит, что свойство независимости событий взаимно. Для независимых событий теорема умножения
Т.е. вероятность совместного появления двух независимых событий равна произведению вероятностей этих событий. Два события называют независимыми, если вероятность их совмещения равна произведению вероятностей этих событий; в противном случае события называют зависимыми. На практике о независимости событий заключают по смыслу задачи. Например, вероятности поражения цели каждым из двух орудий, поэтому событие «первое орудие поразило цель» и «второе орудие поразило цель» независимы.
7.Формула полной вероятности. Опр.: пусть событие А может произойти только совместно с одним из событий Н1, Н2,…,Нnобразующих полную группу несовместных событий, тогда соб. Н1, Н2,…,Нnназываются гипотезами. Теорема: вероятность соб.А наступающего совместно с гипотезами Н1, Н2,…,Нnравна:
где, Р(Нi) – вероятность i-той гипотезы РНi(А) – вероятность соб.А при условии реализации гипотезы Нi Доказательство: соб.А можно считать суммой попарно несовместных событий АН1, АН2, …АНn несовместные события, тогда из теорем сложения вероятностей: Р(А)+Р(АН1+…+ АНn)=Р(АН1)+…+Р(АНn)= =РНi(А)* Р(Н1)+…+ РНn(А)* Р(Нn)=
8. Формула Бейеса.
Теорема гипотез (формула Байеса)– следствие теоремы умножения и ф-лы полной вероятности. Имеется группа несовместных гипотез H1,H2...Hn, чьи вероятности равны соответственно P(H1),P(H2)...P(Hn). В рез. Σ происходит событие А. Как следует изменить вероятности гипотез в связи с появлением А (найти условную вероятность P(Hi|A))? Выражая P(A) из ф-лы полной вероятности, имеем соотношение Байеса:
9. Формула Бернулли. Пусть производится серия из n независимых испытаний и в каждом испытании событие А наступает с одной и той же вероятностью P(A)=p и не наступает с вероятностью Доказательство: Рассмотрим серию из n испытаний, в которых событие А произошло m раз:
10. Формула Пуассона и условия ее применимости.
Использование формулы Бернулли при больших n и m вызывает трудности из-за громоздких вычислений => возникает необходимость в отыскании вероятности
Доказательство: λ=np =>p=λ/n подставляем это равенство в формулу:
Перейдем к пределу в обеих частях неравенства при n
Формулу Пуассона применяют обычно когда n≥50, np≤10
11. Дискретные случайные события и возможности их описания.
Опр.: СВ- это переменная, которая в результате испытания в зависимости от случая принимает одно из возможного множества своих значений. (Примеры: число бракованных изделий в данной партии, расход электроэнергии предприятия) Опр.: ДСВ – это СВ с конечным или бесконечным, но счетным множеством её значений (см.выше 1-ый пример) Для случайных величин (далее - СВ) приходится использовать особые, статистические методы их описания. Дискретное описание заключается в том, что указываются все возможные значения данной величины (например - 7 цветов обычного спектра) и для каждой из них указывается вероятность или частота наблюдений именного этого значения при бесконечно большом числе всех наблюдений. Доказанно, что при увеличении числа наблюдений в определенных условиях за значениями некоторой дискретной величины частота повторений данного значения будет все больше приближаться к некоторому фиксированному значению - которое и есть вероятность этого значения.
12. Закон распределения дискретной случайной величины. Многоугольник распределения.
Опр.: Закон распределения СВ – это всякое соотношение устанавливающее связь между возможными значениями СВ и соответствующими ими вероятностями. Говорят, что СВ распределена по данному закону или подчинена этому закону распределения. ЗАКОН распределения ДСВ может быть задан в виде таблицы:
Х: - ряд распределения ДСВ где, х1, х2,…, хn– возможные значения СВ, в порядке возрастания p1, p2,..., pn– соответствующие им вероятности. Очевидно, что суммы вероятностей pi=1
Т.к.события Х=х, х=1,…,х= хn образуют полную группу событий. Закон распределения дискретной случайной величины может быть представлен в виде многоугольника распределения – фигуры, состоящей из точек, соединенных отрезками
Многоугольники унимодального (а), полимодального (б) и антимодального (в) распределений.
13. Функция распределения и ее свойства. Вероятность попадания случайной величины на заданный интервал.
Опр.: ф-я распределения С.В.Х. называется ф-я F(x)выражающая для каждого Х вероятность того,что примет значение:F(x)=P(x<x) Ф-я F(x) называется интегральная ф-я распределения. Св-ва ф-ииF(x): 1)0<=F(x)<=1;2)F(x)-неубыв.ф-я на всей числовой оси.; 3) График:составим ф-ю распределения F(z)=? 1)z<=-1следовательно F(z)=P(z<z)=0 2)-1<z<=0след-ноF(z)=P(z<z)=P(z=-1)=0,08; 3)0<z<=1cлед.F(z)=P(z<z)=P(z=-1)+P(z=0)=0,34 4)1<z<=2 F(z)=p(Z<z)=P(Z=-1)+P(Z=0)+ P(Z=1)=0,08+0,26+0,22=0,56
0,08;-1<z<=0 F(X)= 0,34;0<z<1 0,56;1<z<=2 0,76;2<z<=3 0,96;3<z<=4 1;z>4
Вероятность того, что значение дискретной случайной величины Fx (x) попадает в интервал (a, b), равнаяP(a < x < b) = Fx (b) -Fx (a), вычисляется по формулам: Если a= - если b= , то .
14. Плотность распределения и ее свойства. Вероятностный и геометрический смысл плотности распределения.
Плотностью распределения вероятностей непрерывной С.В. называют первую производную от ф-ии распределения:f(x)=F(x) Св-ва:1)плотность распределения неотриц.,т.е.f(x)>=0 2)вер-ть попадания непрерывнрой С.В. в интервал(а,в)равна интервалу от ее плотности вероятности в пределах от а до в P(a<x<b)= Геометрически,полученная вероятность равна S фигуры ограниченной сверху кривой распределения и опирается на отрезок ав
15. Математическое ожидание случайной величины и его свойства.
Математическим ожиданием(средним значением)называют сумму следущегоряда,если он сходится М(х)= Св-ва М(х):1)М(с)=с:2)М(к*х)=к*М(х),к-постоянная величина,К=const Док-во:М(К*Х)= 3)Математическое ожидание M(x+-y)=M(x)+-M(y) M(x*y)=M(x)*M(y) M[x-M(x)]=0
16. Дисперсия и среднее квадратичное отклонение случайной величины и ее свойства.
Опр:дисперсиейD(x) С.В.Х. называется математическое ожидание квадрата ее отклонение от математического ожидания D(x)=M[(x- Если С.В. дискретная с конечным числом значений,то D(x)= Если С.В.Х дискретная с бесконечно счетным,множествомзначений,тогда дисперсия D(x)= Опр:Среднимквадратическим отклонением Замечание:матем.ожидание М(х) характеризует среднее значение С.В. Дисперсия D(x)характеризует квадратичное отклонение С.В. от среднего значения: Св-ваD(x): 1)D(c)=0: 2)D(k*x)= Док-во:D(k*x)=M M 3)дисперсия D(x+-y)=D(x)+D(Y) 4)D(x)=M(x2)-(M(x))2 Док-во:D(x)=M(x-M(x))2)=M(x2-2x*M(x)+M2(x))=M(x2)-2M(x)*M(M(x))+M(M2(x))=M(x2)-2M(x)*M(x)+M2(x)=M(x2)-M2(x) M(x) M2(X)-постоянные величины
17. Математическое ожидание и дисперсия числа появления события в независимых опытах.
Пусть производится n независимых опытов, вероятность появления события в каждом из которых равна Р. Число появлений события в этих n опытах является случайной величиною Х распределённой по биномиальному закону. Однако, непосредственное вычисление её среднего значения громоздко. Для упрощения воспользуемся разложением, которым будем пользоваться в дальнейшем неоднократно: Число появления события в n опытах состоит изчисла появлений события в отдельных опытах, т.е. где
Поэтому
или т.е. среднее число появлений события в n независимых опытах равно произведению числа опытов на вероятность появления события в одном опыте. Например, если вероятность попадания в цель при одном выстреле равна 0,1, то среднее число попадания в 20 выстрелах равно 20×0,1=2.
Производится n независимых испытаний и вероятность появления события в каждом испытании равна р. Выразим, как и прежде, число появления события Х через число появления события в отдельных опытах
Так как опыты независимы, то и связанные
Но каждая из случайных величин имеет закон распределения и где q=1-p В итоге имеем Среднее квадратическое отклонение числа появления событий в n независимых опытах равно
18.Непрерывная случайная величина. Числовые характеристики непрерывных случайных величин.
Опр.: непрерывная СВ – это СВ имеющая бесконечное несчетное множество значений, покрывающая некоторый отрезок числовой оси. Опр.: Закон распределения СВ – это всякое соотношение устанавливающее связь между возможными значениями СВ и соответствующими ими вероятностями. Говорят, что СВ распределена по данному закону или подчинена этому закону распределения. Математическим ожиданием непрерывной случайной величины Х, возможные значения которой принадлежат отрезку [a,b], называется определенный интеграл
Дисперсией непрерывной случайной величины называется математическое ожидание квадрата ее отклонения.
Средним квадратичным отклонениемназывается квадратный корень из дисперсии.
19. Закон равномерного распределения.
Непрерывная случайная величина имеет равномерноераспределение на отрезке [a,b], если на этом отрезке плотность распределения случайной величины постоянна, а вне его равна нулю. Для того, чтобы случайная величина подчинялась закону равномерного распределения необходимо, чтобы ее значения лежали внутри некоторого определенного интервала, и внутри этого интервала значения этой случайной величины были бы равновероятны.
20. Экспоненциальный закон распределения.
21. Нормальное распределение. Функция Лапласа.
Нормальное распределение. Опред:Случ вел-на ξ имеет нормальное (Гауссовское) распр-е с параметрами a и σ (σ >0), если имеет место след плотность распр-ия:
Свойства: 1. Fa,σ 2(x)=F0,1((x-a)/σ) xÎR 2. ξ (x1, x2) P(x1≤ξ≤ x2)=Ф((x2-a)/σ) – Ф((x1-a)/σ) 3. Ф-цияраспрсл вел-ны ξ, распред-ой по норм закону, выражается через ф-цию Лапласа по формуле: Fξ(x)=½+Ф((x-a)/σ)
22. Нормальное распределение. Вероятность попадания в заданный интервал.
вероятность попадания нормально распределенной случайной величины на заданный интервал:
23. Математическая статистика. Основные понятия.
Матем статистика- раздел математики, изучающий математические методы сбора, систематизации, обработки и интерпретации результатов наблюдений с целью выявления статистических закономерностей. Матеем статистика опирается на теорию вероятностей. Если теория вероятностей изучает закономерности случайных явлений на основе абстрактного описания действительности (теоретической вероятностной модели), то матем статистика оперирует непосредственно результатами наблюдений над случайным явлением, представляющими выборку из некоторой конечной или гипотетической бесконечной генеральной совокупности. Используя результаты, полученные теорией вероятностей, матем статистика позволяет не только оценить значения искомых характеристик, но и выявить степень точности получаемых при обработке данных выводов. Математическая статистика по наблюденным значениям оценивает вероятности этих событий либо осуществляет проверку предположений относительно этих вероятностей. В матем статистике, наоборот, исследование связано с конкретными данными и идет от практики к гипотезе и ее проверке.
Определим основные понятия математической статистики. Генеральная совокупность– все множество имеющихся объектов. Выборка – набор объектов, случайно отобранных из генеральной совокупности. Объем генеральной совокупности N и объем выборки n – число объектов в рассматривае-мой совокупности. Виды выборки: Повторная – каждый отобранный объект перед выбором следующего возвращается в генеральную совокупность; Бесповторная – отобранный объект в генеральную совокупность не возвращается.
24. Генеральная совокупность и выборка. Характеристики выборки.
В матем статистике понятие генеральной совокупности трактуется как совокупность всех мыслимых наблюдений, которые могли бы быть произведены при данном реальном комплексе условий. Иначе, совокупность объектов, из которых произведена выборка.ё ё Выборочная совокупность-совокупность случайно отобранных объектов. Выборочный метод обследования, или как его часто называют, выборка, применяется, прежде всего, в тех случаях, когда сплошное наблюдение вообще невозможно. Виды выборки: вероятностные и невероятностные. Вероятностная выборка: 1. Простая вероятностная выборка: - простая повторная выборка. Использование такой выборки основывается на предположении, что каждый респондент с равной долей вероятности может попасть в выборку. - простая бесповторная выборка. 2. Систематическая вероятностная выборка. Является упрощенным вариантом простой вероятностной выборки. 3. Серийная вероятностная выборка. 4. Районированные выборки 5. «Удобная» выборка Процедура «удобной» выборки состоит в установлении контактов с «удобными» единицами выборки. Невероятностные выборка (отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям- доступности, типичности, равного представительства и т.д.: 1.Квотная выборка- выборка строится как модель , которая воспроизводит структуру генеральной совокупности в виде квот изучаемых признаков. 2. Метод снежного кома. 3. Стихийная выборка. Способы отбора: 1.Рандомизация или случайный отбор, используется для создания случайных выборок. 2.Попарный отбор- стратегия построения групп выборки, при котором составляются из субъектов, эквивалентных по значимым для эксперимента побочным параметрам. 3.Многоступенчатый способ построения выборки. При многоступенчатом отборе выборка строится в несколько этапов, причём на каждой стадии меняется единица отбора. 4..Многосфазный способ построения выборки.- является разновидностью многоступенчатого способа, заключается в том, что из сформированной выборки большего объёма производится новая выборка меньшего объёма, при этом, единица отбора остаётся одной и той же. 5.Комбинированный способ построения выборки- соединение в многоступенчатой выборке различных приёмов отбора.
25. Закон больших чисел и его следствие.
Закон больших чиселв теории вероятностей утверждает, что эмпирическое среднее (среднее арифметическое) достаточно большой конечной выборки из фиксированного распределения близко к теоретическому среднему (математическому ожиданию) этого распределения. В зависимости от вида сходимости различают слабый закон больших чисел, когда имеет место сходимость по вероятности, и усиленный закон больших чисел, когда имеет место сходимость почти всюду. Всегда найдётся такое количество испытаний, при котором с любой заданной наперёд вероятностью частота появления некоторого события будет сколь угодно мало отличаться от его вероятности. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая. На этом свойстве основаны методы оценки вероятности на основе анализа конечной выборки. Наглядным примером является прогноз результатов выборов на основе опроса выборки избирателей.
Закон больших чисел – это несколько теорем, определяющих общие условия, при которых среднее значение случайных величин стремится к некоторой const при проведении большого числа опытов (теоремы Чебышева и Бернулли).
Если существует последовательность таких, что для любых ε>0, выполняется условие:
Последовательность
Если в выражении (*) В данных терминах Неравенство Чебышева Для любой случайной величины ξ(кси), имеющей M[ξ] и D[ξ] при каждом ε>0 имеет место неравенство(неравенство Чебышева):
Док-во: ξ£η, M[ξ]£M[η] Рассмотр. некотор.сл.вел-ну η
26. Статистическое распределение выборки.
Выборка- множество случаев (испытуемых, объектов, событий, образцов), с помощью определённой процедуры выбранных из генеральной совокупности для участия в исследовании. Cтатистическим (эмпирическим) законом распределения выборки, или просто статистическим распределением выборки называют последовательность вариант хi и соответствующих им частот ni или относительных частот wi. Статистическое распределение выборки удобно представлять в форме таблицы распределения частот, называемой статистическим дискретным рядом распределения.
27. Эмпирическая функция распределения
Эмпирической функцией распределения называют функцию F*(x), определяющую для каждого значения x относительную частоту события X<x. По определению:
Где Свойства эмпирической функции распределения: 1) Значение эмпирической функции принадлежат отрезку [0;1] 2) F*(x)- неубывающая функция 3) если
28. Полигон и гистограмма.
Основные графики вариационного ряда: полигон и гистограмма. Полигономчастот называют ломаную, отрезки которой соединяют точки Для построения полигона частот на оси абсцисс откладывают варианты х2, а на оси ординат – соответствующие им частоты ni. Точки (хi,ni) соединяют отрезками и получают полигон частот. Гистограммойчастот называют ступенчатую фигуру, состоящую из прямоугольников, одна из сторон которых - частичные интервалы с длиною h, другая- отношение (плотность частоты). Для построения гистограммы частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии ni/h. Площадь i-го частичного прямоугольника равна h•ni/h=ni - сумме частот вариант i-го интервала; следовательно, площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.
29. Статистические оценки параметров распределения.
Статистической оценкой неизвестного параметра теоретического распределения называют функцию от наблюдаемых случайных величин. Несмещённой называют статистическую оценку Ө*, математическое ожидание которой равно оцениваемому параметру Ө при любом объёме выборки, т.е. M(Ө*)= Ө Смещённой называют оценку, математическое ожидание которой не равно оцениваемому параметру. Эффективной называют статистическую оценку, которая (при заданном объёме выборки n) имеет наименьшую возможную дисперсию. При рассмотрении выборок большого объёма (n велико!) к статистическим оценкам предъявляется требование состоятельности. Состоятельной называют статистическую оценку, которая при n →∞ стремится по вероятности к оцениваемому параметру. Например, если дисперсия несмещённой оценки при n→∞ стремится к нулю, то такая оценка оказывается и состоятельной.
30. Выборочная средняя и выборочная дисперсия.
Выборочная дисперсия Для того чтобы охарактизировать рассеяние наблюдаемых значений количественного признака выборки вокруг своего среднего значения Выборочной средней 1) х1,х2,…,хn -все различны n-объём выборки
2) х1,х2,…,хk -появляются с опред.частотой. x1–появляется n1 раз x2 – n2 xk–nk
31. Точечная и интервальная оценки. Доверительный интервал.
Точечные оценки Точечной нзв оценку, к-рая опред-ся одним числом, например: генеральная средняя, выборочная средняя, групповая и общая средние, генеральная дисперсия, выборочная дисперсия и др.
xi – значения выборки При выборке малого объема точечная оценка может знач.отличаться от оцениваемого параметра, т.е. приводить к грубым ошибкам. По этой причине при небольшом объеме выборки следует пользоваться интервальными оценками. Оценка неизвестного параметра называется интервальной, если она определяется 2 числами, концами интервала. Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал (Ө1*;Ө 2*), относительно которого с заранее выбранной вероятностью γ можно утверждать, что внутри этого интервала находятся точные значения оцениваемого параметра. Интервал (Ө1*;Ө 2*), накрывающий с вероятностью γ истинное значение параметра Ө наз-ся доверительным интервалом. А вероятность γ наз-ся надежностью оценки или доверит. вероятностью. Часто дов. интервал выбирается симметрично относительно несмещенной точечной оценки Ө*, т.е. выбирается интервал вида (Ө*-ε; Ө*+ε) такой, что Р(|Ө-Ө*|<ε)=γ. Число ε>0 наз-ся точность оценки.
32. Проверка статистических гипотез.
Одна из часто встречающихся на практике задач состоит в том, должно ли на основании данной выборки быть принято или опровергнуто некоторое предположение (гипотеза) относительно генеральной совокупности (случайной величины). Под статистической гипотезой понимается всякое предположение о генеральной совокупности. Стат гипотезы делятся на:1)гип-зы о параметрах распределения известного вида, 2) гип-ps о виде неизвестного распр-я. Обычно выдвигают нулевую гип-зу Но (основную) и альтернативную ей Н1 (конкурирующую). Простая гип-за - гип-за, однозначно фиксирующая распределение наблюдений. В ней идет речь об одном значении параметра, иначе- сложная гип-за. Этапы проверки статистических гипотез 1. Формулировка основной гипотезы H0 и конкурирующей гипотезы H1. Гипотезы должны быть чётко формализованы в математических терминах. 2. Задание вероятности α, называемой уровнем значимости и отвечающей ошибкам первого рода, на котором в дальнейшем и будет сделан вывод о правдивости гипотезы. 3. Расчёт статистики φ критерия такой, что: её величина зависит от исходной выборки § по её значению можно делать выводы об истинности гипотезы H0; § сама статистика φ должна подчиняться какому-то известному закону распределения, т.к. сама φ является случайной в силу случайности 4. Построение критической области. Из области значений φ выделяется подмножество 5. Вывод об истинности гипотезы. Наблюдаемые значения выборки подставляются в статистику φ и по попаданию (или непопаданию) в критическую область
|
|||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-05-27; просмотров: 279. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |

 соб.А называется вероятность соб.В при условии, что событие А произошло (пример: пусть соб.А - это извлечение из колоды в 32 карты туза; соб.В – вторая вынутая карта из колоды оказалось тузом. Если после 1-го раза карта возвращается в колоду, то вероятность вынуть туз не меняется и равна 4/32, если же 1-я карта в колоду не возвращается, то осуществление соб.А прибудет к тому, что в колоде остается 31 карта из которой 3 туза
соб.А называется вероятность соб.В при условии, что событие А произошло (пример: пусть соб.А - это извлечение из колоды в 32 карты туза; соб.В – вторая вынутая карта из колоды оказалось тузом. Если после 1-го раза карта возвращается в колоду, то вероятность вынуть туз не меняется и равна 4/32, если же 1-я карта в колоду не возвращается, то осуществление соб.А прибудет к тому, что в колоде остается 31 карта из которой 3 туза  – условная вероятность
– условная вероятность

 ,
, 

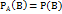 подставив данное равенство в
подставив данное равенство в получим
получим , отсюда
, отсюда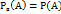 ,
,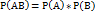 ,
,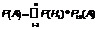 - формула полной вероятности
- формула полной вероятности
 .Док-во: вероятность появления А опред. по ф-ле полной вероятности:
.Док-во: вероятность появления А опред. по ф-ле полной вероятности:  . Поищем условные вероятности
. Поищем условные вероятности 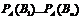 при условии, что произошло событие А. По теореме умножения имеем
при условии, что произошло событие А. По теореме умножения имеем  . Подставим P(A), получим
. Подставим P(A), получим 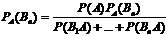 . чтд. Ф-лы Байеса позволяют переоценить вероятности после того, как становится известным результат испытания, в итоге которого появилось событие А.
. чтд. Ф-лы Байеса позволяют переоценить вероятности после того, как становится известным результат испытания, в итоге которого появилось событие А. . Условно появление события А называется «успехом», а не появление - «неудачей». Испытания называются независимыми, если исход каждого последующего не зависит от исходов предыдущих испытаний. Последовательность независимых испытаний такого рода называется схемой Бернулли. Вероятность того, что в n независимых испытаниях событие А произойдет ровно m раз – Pn(m). Тогда имеет место формула Бернулли: Pn (m)=
. Условно появление события А называется «успехом», а не появление - «неудачей». Испытания называются независимыми, если исход каждого последующего не зависит от исходов предыдущих испытаний. Последовательность независимых испытаний такого рода называется схемой Бернулли. Вероятность того, что в n независимых испытаниях событие А произойдет ровно m раз – Pn(m). Тогда имеет место формула Бернулли: Pn (m)=  .
. .Вычислим вероятность этого произведения: P (
.Вычислим вероятность этого произведения: P ( 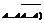 =
=  =pmqn – m. Pn (m)=
=pmqn – m. Pn (m)=  обеспечивающих необходимую точность.
обеспечивающих необходимую точность.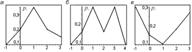 Теорема: если число испытаний неограниченно увеличивается n
Теорема: если число испытаний неограниченно увеличивается n 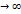 и вероятность р наступления соб.А в каждом испытании уменьшается р
и вероятность р наступления соб.А в каждом испытании уменьшается р  , но так что их произведение n*p остается величиной постоянной (λ=np=const), то вероятность
, но так что их произведение n*p остается величиной постоянной (λ=np=const), то вероятность 


 =
=  =
=  =
= 

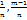 ,
, 

 =>
=> 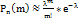

 4)P(x1<=x<=x2)=F(x2)-F(x1)
4)P(x1<=x<=x2)=F(x2)-F(x1)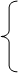

 , то
, то  ,
,
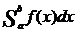




 ,где а= М(х)
,где а= М(х) ,a=M(x),если ряд в правой части сходится
,a=M(x),если ряд в правой части сходится (х) С.В.Х. называется число
(х) С.В.Х. называется число 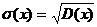
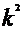 *D(x)
*D(x) =
= =
= 


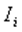 имеет закон распределения (принимает значение 1, если событие в данном опыте произошло, и значение 0, если событие в данном опыте не появилось).
имеет закон распределения (принимает значение 1, если событие в данном опыте произошло, и значение 0, если событие в данном опыте не появилось).

 с опытами случайные величины
с опытами случайные величины 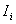 независимы. А в силу независимости
независимы. А в силу независимости  имеем
имеем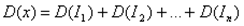

 , поэтому по определению дисперсии
, поэтому по определению дисперсии ,
, ,
, 
 .
.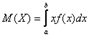
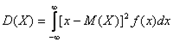



 Случ вел-на ξ имеет экспоненц-ое (показательное) распр с параметром α>0, если имеет место след посл-ть распределения:
Случ вел-на ξ имеет экспоненц-ое (показательное) распр с параметром α>0, если имеет место след посл-ть распределения: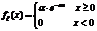


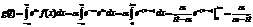

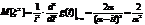










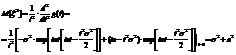
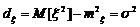
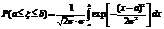
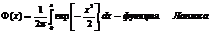



 (*)
(*) 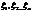 подчиняется закону больших чисел с заданными функциями
подчиняется закону больших чисел с заданными функциями  :
: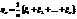
 , то говорят, что случайная величина
, то говорят, что случайная величина 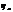 сходится по вероятности к а.
сходится по вероятности к а. означает, что вел-на ηn-an сходится по вероятности к нулю.
означает, что вел-на ηn-an сходится по вероятности к нулю.
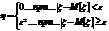



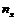 - число вариант, меньших x; x- объём выборки.
- число вариант, меньших x; x- объём выборки. - наименьшая варианта, то F*(x)=0 при x≤
- наименьшая варианта, то F*(x)=0 при x≤  - наибольшая варианта, то F*(x)=1 при x>
- наибольшая варианта, то F*(x)=1 при x>  .
. вводят сводную характеристику –выборочную дисперсию. Выборочной дисперсией
вводят сводную характеристику –выборочную дисперсию. Выборочной дисперсией  называют среднее арифметическое квадратов отклонения наблюдаемых значений признака от их среднего значения
называют среднее арифметическое квадратов отклонения наблюдаемых значений признака от их среднего значения  если все значения
если все значения 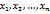 признака выборки объема nразличны, то
признака выборки объема nразличны, то  если же значения признака
если же значения признака  имеет соответственно частоты
имеет соответственно частоты  причем
причем  т.е. выборочная дисперсия есть средняя взвешаная квадратов отклонения с весами , равными соответствующим частотам. Кроме дисперсии для характеристики рассеяния значений признака выборочной совокупности вокруг своего среднего значения пользуются сводной характеристикой – средним квадратическим отклонением. Выборочным средним квадратическим отклонением (стандартом) называют квадратный корень из выборочной дисперсии:
т.е. выборочная дисперсия есть средняя взвешаная квадратов отклонения с весами , равными соответствующим частотам. Кроме дисперсии для характеристики рассеяния значений признака выборочной совокупности вокруг своего среднего значения пользуются сводной характеристикой – средним квадратическим отклонением. Выборочным средним квадратическим отклонением (стандартом) называют квадратный корень из выборочной дисперсии: 
 наз.среднее арифметическое значений признака выборочной совокупности.
наз.среднее арифметическое значений признака выборочной совокупности.

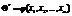
 ;
; .
.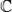 таких значений, по которым можно судить о существенных расхождениях с предположением. Его размер выбирается таким образом, чтобы выполнялось равенство
таких значений, по которым можно судить о существенных расхождениях с предположением. Его размер выбирается таким образом, чтобы выполнялось равенство  . Это множество
. Это множество  и называется критической областью.
и называется критической областью. выносится решение об отвержении (или принятии) выдвинутой гипотезы H0.
выносится решение об отвержении (или принятии) выдвинутой гипотезы H0.