|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Алгоритм сжатия с использованием кодов Хаффмана ⇐ ПредыдущаяСтр 3 из 3
Данный алгоритм (далее для краткости - алгоритм Хаффмана) был разработан в 1952 году и относится к группе статистических методов сжатия. Статистические методы используют различные приёмы для того, чтобы наиболее часто встречающимся символам соответствовали более короткие коды. При этом каждый код однозначно соответствует конкретному символу. Например, в тексте на русском языке буква а встречается гораздо чаще, чем буква ы, поэтому имеет смысл присвоить букве а более короткий код. Соответственно выходной поток этих методов является бит-ориентированным, т.е. не форматированным по границам байтов. Статистические методы работают медленнее словарных, но достигают, как правило, более высокой степени сжатия. Они используют три основных модели для набора статистики (определения вероятностей символов): - неадаптивную; - полуадаптивную; - адаптивную.
В неадаптивных моделях вероятности всех символов алфавита определены заранее. Эта модель обычно применяется только при сжатии текстовых файлов. В полуадаптивных моделях входные данные обрабатываются за 2 прохода: 1-й – для подсчёта вероятностей, 2-й – собственно для сжатия. Эта модель может применяться для сжатия не очень больших изображений. Адаптивные модели вычисляют и корректируют вероятности символов в процессе сжатия, т.е. «на лету». Модели последнего типа сложнее предыдущих, зато являются более универсальными и часто дают наилучшее сжатие. Рассмотрим кодирование по Хаффману более подробно. Предположим, что вероятности (их заменят частоты) всех символов алфавита уже подсчитаны одним из вышеописанных способов. Тогда:  1. Выписываем в ряд все символы алфавита в порядке убывания вероятноcтей (частоты) их появления в потоке данных (для удобства построения дерева); 2. Объединяем два символа с наименьшими вероятностями в новый составной символ, вероятность которого определяется как сумма вероятностей составляющих его символов. Последовательно повторяем эту операцию до образования единственного составного символа (корня). В результате получается дерево символов, каждый узел которого имеет суммарную вероятность всех объединённых им узлов. 3. Прослеживаем путь от каждого листа дерева к корню, помечая направление движения к каждому узлу (например, вверх/направо –1, вниз/налево - 0). При этом не важен конкретный вид разметки «ветвей» дерева (т.е. помечать направление вверх/направо –1, вниз/налево – 0, или наоборот), но важно придерживаться выбранного способа разметки ко всем «ветвям» дерева. 4. Получившиеся двоичные комбинации, записанные от конца к началу и формируют коды Хаффмана.
Полученный коэффициент сжатия подсчитывается по следующей формуле
где n – количество бит, необходимое для кодирования символов алфавита фиксированным числом разрядов;
Коды Хаффмана никогда не увеличивают, а чаще всего наоборот, уменьшают среднюю длину кодовых слов для символов в цепочке данных. Поэтому сжатие с применением кодов Хаффмана, всегда имеет коэффициент ³ 1 , причём знак равенства получается только в том случае, когда вероятности всех символов во входном потоке одинаковы. Пример кодирования по Хаффману приведен на рис. 3.
Примечание: 1) для удобства расчётов при выполнении практической части, дробное значение частоты символа можно заменить целым числом появлений данного символа в цепочке, поэтому в корне дерева получится не 1 (сумма частот), а значение, равное длине цепочки. В этом случае коэффициент сжатия рассчитывается по формуле
где K – общее количество символов во входном потоке; 2) частоты появления символов в примере расположены не по убыванию исключительно ради наглядности внешнего вида «дерева», т.к. в противном случае ветви пересекались бы между собой. Несмотря на то, что коды Хаффмана в обоих случаях могут отличаться, это не имеет значения, поскольку сохранится свойство однозначности кодов Хаффмана, т.е. ни один из кодов не совпадет с начальными битами другого, более длинного кода.
Рис.3. Пример кодирования по Хаффману.
Если предположить, что входной поток символов был байт-ориентированным, то n=8. Тогда коэффициент сжатия
Если считать входной поток символов бит-ориентированным с равным количеством бит под каждый символ, то n=4 (т.к. для кодирования 10 различных символов a-j требуется
Кодирование по Хаффману может использоваться при сжатии изображений как самостоятельно, так и в составе других алгоритмов сжатия, например LZW и JPEG (это наиболее эффективное его применение).
Алгоритм сжатия JPEG Этот алгоритм появился в конце 1980-х гг. в результате долгих исследований группы специалистов, что и дало ему название JPEG – Joint Photographic Experts Group, т.е. объёдиненная группа экспертов по фотографии. Являясь алгоритмом сжатия с потерями, JPEG даёт очень высокий коэффициент сжатия. Для сложных изображений - до 10 (без заметного ухудшения качества) и более (с заметным ухудшением качества). Для сравнительно простых изображений, имеющих большие области одинакового цвета, коэффициент сжатия может достигать 20-25. Используя волновую природу света, JPEG представляет изображение как суперпозицию множества гармоник световых волн разных частот. При этом основную энергию несут низкочастотные гармоники, в то время как высокочастотные могут быть отброшены без заметного ухудшения качества изображения. При этом имеется возможность регулировать этот частотный порог, меняя тем самым степень сжатия. Алгоритм JPEG включает четыре основных этапа: 1) Предварительная подготовка изображения; 2) Дискретное косинусное преобразование; 3) Квантование; 4) Вторичное сжатие.
На 1-м этапе цветное RGB-изображение разделяется на три цветовых плоскости (красную, зеленую и синюю). Затем каждая плоскость разбивается на квадратные участки размером 8x8 пикселей и далее кодируется отдельно.
Примечание. Для достижения лучшего сжатия изображение может переводиться (хотя и не обязательно) в другую цветовую модель – YUV, где Y – яркость, U и V – цветоразностные компоненты: После этого матрицы, соответствующие плоскостям U и V подвергаются прореживанию (субдискретизации) путем выбрасывания каждой второй строки и столбца. Это и позволяет получить дополнительный эффект сжатия при использовании цветовой модели YUV.
Основным этапом работы алгоритма является дискретное косинусное преобразование (ДКП), представляющее собой разновидность преобразования Фурье. Оно позволяет переходить от пространственного представления изображения к его спектральному представлению и обратно. Другими словами, фрагмент изображения после ДКП представляет собой двумерный частотный спектр в вертикальном и горизонтальном направлениях. При этом в левом верхнем углу матрицы располагаются коэффициенты низкочастотных гармоник, величина которых обычно больше остальных. Пусть матрица блока изображения обозначается IMG =[8х8]. Проведём её нормализацию, вычитая из каждого её элемента 128. Дискретное косинусное преобразование осуществляется по формуле
где
N=8, i=0..7, j=0..7.
На этапе квантования сначала вычисляется матрица квантования по следующей формуле i,j =0..7 где q – коэффициент качества, регулирующий степень сжатия. Затем каждое число в матрице RES нужно разделить на соответствующий элемент в матрице Q. В результате получится некоторая матрица A, у всех элементов которой необходимо отбросить дробные части. В итоге матрица A будет содержать много нулевых элементов, преимущественно в правой нижней части.
На этапе вторичного сжатия элементы матрицы А пакуются максимально компактным образом. Для достижения максимального эффекта сжатия применяется предварительное Z-упорядочивание элементов матрицы A(8x8) в линейный вектор A(64x1), выполняемое по следующей схеме:
+----+----+----+----+----+----+----+----+ | 1 | 2 | 6 | 7 | 15 | 16 | 28 | 29 | +----+----+----+----+----+----+----+----+ | 3 | 5 | 8 | 14 | 17 | 27 | 30 | 43 | +----+----+----+----+----+----+----+----+ | 4 | 9 | 13 | 18 | 26 | 31 | 42 | 44 | +----+----+----+----+----+----+----+----+ | 10 | 12 | 19 | 25 | 32 | 41 | 45 | 54 | +----+----+----+----+----+----+----+----+ | 11 | 20 | 24 | 33 | 40 | 46 | 53 | 55 | +----+----+----+----+----+----+----+----+ | 21 | 23 | 34 | 39 | 47 | 52 | 56 | 61 | +----+----+----+----+----+----+----+----+ | 22 | 35 | 38 | 48 | 51 | 57 | 60 | 62 | +----+----+----+----+----+----+----+----+ | 36 | 37 | 49 | 50 | 58 | 59 | 63 | 64 | +----+----+----+----+----+----+----+----+
Самым распространенным методом вторичного сжатия является сжатие с применением кодов Хаффмана. В полученном векторе А первый элемент (с индексом 0) называется DC коэффициентом. Он пропорционален средней яркости блока и обычно намного больше других элементов вектора. Остальные 63 элемента вектора называются AC коэффициентами, они пропорциональны интенсивности цветовых переходов в блоке. DC и AC коэффициенты кодируются по-разному, но по схожим принципам. Код для DC коэффициента состоит из полей РАЗМЕР (число бит, необходимых для представления значения) и ЗНАЧЕНИЕ (биты самого значения). Код для AC коэффициента состоит из полей ПРОПУСК (количество предшествующих нулевых AC коэффициентов), РАЗМЕР (число бит, необходимых для представления значения) и ЗНАЧЕНИЕ (биты самого значения). Поле ЗНАЧЕНИЕ для обоих типов коэффициентов кодируется идентичным способом в соответствии с табл.1.
Для DC коэффициента поле РАЗМЕР кодируется в соответствии с табл. 2. Для АC коэффициента поля ПРОПУСК и РАЗМЕР рассматриваются как один составной символ вида (ПРОПУСК, РАЗМЕР), который кодируется в соответствии с табл. 3. Причем символ (0,0) называется признаком конца блока и означает, что с текущего места и до конца вектор содержит только нулевые AC коэффициенты.
Таблица 1. Кодирование поля ЗНАЧЕНИЕ в DC и AC коэффициентах
Таблица 2. Коды Хаффмана для поля РАЗМЕР в DC коэффициентах
Таблица 3. Коды Хаффмана для составного символа в AC коэффициентах
Полученные биты кодовых значений DC и AC коэффициентов записываются в выходной поток, и JPEG переходит к сжатию следующего блока данных, и т.д. Распаковка сжатых данных из полученного битового потока и восстановление изображения осуществляется в строго обратном порядке.
Пример
Блок 8x8 (фрагмент) исходного изображения (размер 64*8=512 бит)
Матрица DCT коэффициентов
Матрица квантованных DCT коэффициентов
Кодовая последовательность в десятичном виде
(2)(3) (1,2)(-2) (0,1)(-1) (0,1)(-1) (0,1)(-1) (2,1)(-1) (0,0)
Кодовая последовательность в двоичном виде с учетом кодов Хаффмана
(011)(11) (11011)(01) (00)(0) (00)(0) (00)(0) (11100)(0) (1010)
Результирующая битовая последовательность (31 бит)
0111111011010000000001110001010
Коэффициент сжатия
Контрольные вопросы
1. В чем отличие растровых и векторных форматов хранения данных ? 2. Что такое палитра и в каких случаях она применяется ? 3. Что такое информационная избыточность и каких видов она бывает ? 4. В каких случаях коэффициент сжатия оказывается меньше единицы? 5. Что необходимо для эффективного сжатия по алгоритму LZW ? 6. Может ли кодирование по Хаффману дать 7. Чем объясняется высокая степень сжатия, которую обеспечивает алгоритм JPEG?
Практическая часть
Варианты заданий приведены в Приложении 1. Пункты 6-9 задания являются факультативными. Порядок выполнения задания:
1) Провести «вручную» сжатие 2-х фрагментов данных методом группового кодирования. Сравнить полученные коэффициенты сжатия. 2) Провести «вручную» сжатие 2-х фрагментов данных методом LZW. Сравнить полученные коэффициенты сжатия. 3) Провести «вручную» сжатие 2-х фрагментов данных c применением кодов Хаффмана. Сравнить полученные коэффициенты сжатия. 4) Провести «вручную» сжатие фрагмента данных c применением алгоритмов RLE, LZW и кодов Хаффмана. Описать полученные результаты и сделать соответствующие выводы. 5) Реализовать алгоритм JPEG в среде Mathcad и применить его для сжатия двух фрагментов изображения согласно варианту задания при q=2 для 1-го фрагмента и при q=2 и 7 для 2-го фрагмента. Сравнить полученные коэффициенты сжатия и объяснить результаты. Сделать вывод о влиянии пиксельных значений исходных фрагментов изображения на эффективность сжатия.
Примечание: Импорт в Mathcad-документ полутоновой матрицы цветного изображения Image1.bmp на диске C: осуществляется командой M:=READBMP(“c:\Image1.bmp”). Для выделения рабочего блока из общей матрицы изображения используйте функцию IMG=submatrix(M,r1,r2,c1,c2), при этом перевод блока в цветовую плоскость YUV не требуется.
6) Создать динамическую библиотеку с процедурой CompressImage, реализующую алгоритм группового кодирования (RLE) согласно блок-схеме на рис. 2. Инструкции приведены в Приложении 2. 7) Запустить основную программу RLE.exe. Выполнить сжатие изображения Image1.bmp , выбрав пункт меню Файл/Сжать изображение. При успешном завершении процедуры на экране появляется диалоговое окно с указанием коэффициента сжатия и в основной директории создается соответствующий файл Image1.rle; 8) Визуально проверить качество сжатия, открыв изображение командой меню Файл/Открыть сжатое изображение: если процедура сжатия была реализована корректно, то в окне программы можно наблюдать осмысленное изображение. В противном случае необходимо корректировать процедуру; 9) Выполнить сжатие изображения Image2.bmpи Image3.bmp. Сравнить коэффициенты сжатия изображений Image1.bmp,Image2.bmp иImage3.bmp. Объяснить полученные результаты. 10) Оформить отчет о проделанной работе, содержащий подробное решение всех пунктов задания и листинги программ.
Приложение 1. Варианты заданий.
Числа в таблице соответствуют номерам цепочек данных. В пунктах 17-26 данных для кодирования числа обозначают индексы строк и столбцов для выделения рабочего блока из общей матрицы изображения.
Данные для кодирования: 1) bbbbbbbccccccbbcaaaaaaabbbccccaaaaaaabbbbbaaaaadddddddddaaaadd 2) cbcbbbbcdccddaddabbddccaaaccddddccbbbaaadddddbbbbcacccddaabb 3) aaaaaccccaaccccbbccccccccfffffffffffffssssssssaaaaaabbbbbcccbbbbbffbbbb 4) ccccccbbaaccaddcdacdbcadcdadaaaddacaccadaabbbacadcccadbcbbbcbcbd
5) baaccbccbcabaccabbaabaaabcc 6) babaabbaabbaaabbbaaaaa 7) abbabbabaabbabbbba 8) aaacbcbbbbcccbbbcacc
9) dcafbfbabggbceffgggfhhhgghhhefffsffaabbabchhabffccaf 10) faaadddddbbbccbaffbbbaabbabbbabbfcadcbfababadddab 11) gdadafghggfghababahbagggabcdcdcahhggaghhhgacagca 12) bbffdddedffdfdccdcadcddddacacacccaccaccadccfcc
13) abaacadbbaaaaadcda 14) aacaddddccdbbaaaaad 15) bbbacadbccadcbaaadcda 16) abaaabbccdabaacadb
17) 250-257, 200-207 18) 290-297, 170-177 19) 50-57, 60-67 20) 150-157, 141-148 21) 220-227, 300-307 22) 121-128, 145-152 23) 122-129, 146-153 24) 123-130, 147-154 25) 140-147, 170-177 26) 123-130, 296-303 Приложение 2. Инструкции по выполнению пп. 6-9 задания.
Программная реализация алгоритма сжатия RLE в виде процедуры (функции) может быть выполнена на любом доступном языке высокого уровня, таком как Pascal (в среде Delphi) или C++ (в средах Воrland Builder или Microsoft Visual), однако следует учитывать, что при вызове процедуры в основной программе используется т.н. «паскалевское»(__stdcall) соглашение о передаче параметров. Процедура входит в динамическую библиотеку (DLL), которая подключается к основной программе. Взаимодействие происходит по следующей схеме: 1) основная программа RLE.exe загружает исходный файл изображения и динамическую библиотеку в оперативную память; 2) из динамической библиотеки вызывается функция CompressImage c четырьмя параметрами: - pInBuf – массив исходных данных; - pOutBuf – массив сжатых данных; - nInSize – размер входных данных; - nOutSize – размер сжатых данных. Функция реализует алгоритм и формирует массив сжатых данных; 3) Основная программа компонует новый файл изображения и записывает его на “жесткий” диск.
Ниже приведён пример шаблона реализации в среде программирования Delphi:
- создать новый проект с именем “RLE” c помощью мастера создания динамической библиотеки выбрав пункт меню Project/Add New Project/DLL Wizard; - добавить в проект файл Module1.pas, выбрав команду Project/Add to Project(шаблоны файлов RLE.dpr и Module1.pasсм. ниже); - скомпилировать библиотеку RLE.dll и перенести её в каталог основной программы RLE.exe.
/////////////////////////////////////////////////////// Файл RLE.dpr ///////////////////////////////// library RLE;
Uses SysUtils, Classes, Module1 in 'Module1.pas'; {подключаем модуль файла Module1.pas} Exports CompressImage name 'CompressImage '; {делаем функцию CompressImage экспортируемой }
Begin End.
/////////////////////////////////////////////////////// Файл Module1.pas ///////////////////////////////// unit Module1;
Interface type TArray = array [0..9] of byte; pArray = ^TArray; { объявляется тип указателя на массив элементов типа byte } { объявление процедуры CompressImage} procedure CompressImage(pInBuf:pArray; pOutBuf:pArray; nInSize:longword; nOutSize:longword);
Implementation
Uses Dialogs, SysUtils;
{ определение процедуры CompressImage} procedure CompressImage(pInBuf:pArray; pOutBuf:pArray; nInSize:longword; nOutSize:longword); Var { Здесь объявляются локальные переменные, например i: integer; Res: byte} Begin { Здесь размещается код алгоритма. pInBuf – указатель на массив входных данных типа byte; pOutBuf – указатель на массив выходных(сжатых) данных типа byte; nInSize – размер входных данных, передаваемый процедуре ; nOutSize – размер выходных данных, вычисляемый процедурой; Индексация массивов начинается с нуля. Обращение к i-элементу массива по указателю выполняется в виде pInBuf^[i]. Пример: for i:=0 to (n-1) do begin pOutBuf ^[i+1] := pInBuf^[i]; end; } end;
end.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 502. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 , (2)
, (2) - вероятность (частота) повторения символа
- вероятность (частота) повторения символа 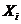 во входном потоке;
во входном потоке; - количество бит в коде Хаффмана для символа
- количество бит в коде Хаффмана для символа  , (3)
, (3) – количество символов
– количество символов 

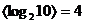 разряда). В этом случае
разряда). В этом случае  будет означать выигрыш, полученный от применения кодов Хаффмана по сравнению с кодами фиксированной, минимально необходимой битовой размерности. В этом случае
будет означать выигрыш, полученный от применения кодов Хаффмана по сравнению с кодами фиксированной, минимально необходимой битовой размерности. В этом случае
 (4)
(4) (5)
(5)
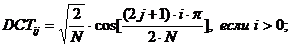 (6)
(6) , (7)
, (7)
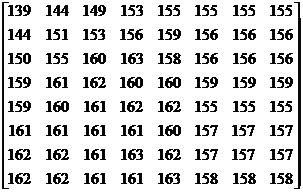



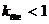 ? Почему ?
? Почему ?