|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
МЕТОДЫ ВЫЯВЛЕНИЯ ГРУБЫХ ОШИБОКОбработку засорений производят по следующему плану: 1) Распознавание ошибок и данных; 2) Выбор метода и проведение робастного оценивания данных; 3) Критериальная и логическая проверка и интерпретация результатов устойчивого оценивания.
Простым способом для обнаружения грубых ошибок является Т – Критерия Граббса:
s – Выборочное среднеквадратическое отклонение случайной величины.
Полученные значения По сравнению с оценками Граббса оценками грубых ошибок признаются L- и E- критерии, предложенные американскими статистиками Г. Тритьеном. И Г.Муром. 1. L-Критерий. Применяется для вычисления грубых ошибок в верхней части ранжированного ряда данных:
где n – Объем выборки; k – Число наблюдений с резко отклоняющимися значениями признака;
2. 
где
3. E-критерий используется, когда в выборке имеются предположительно грубые ошибки с наибольшими и наименьшими значениями, т.е. расположенные в верхней и в нижней части ранжированного ряда данных:
где
Все три критерия
Пример. Имеются данные о количестве русских автомобилей на 2000 автомобилей в 20-ти городах.
Таблица 2 – Исходные данные.
На основе этих данных найдем обычные оценки средней и дисперсии и устойчивые оценки, учитывающие наличие в данных грубых ошибок. Решение: На первом этапе необходимо ранжировать ряд.
Таблица 3 – Ранжированный ряд данных.
В исходных данных вызывают сомнения данные 44,89; 55,26; 1606,41; 1788,56. Они отмечены жирным шрифтом в таблице 2. Можно предположить, что эти данные записаны неверно, взяты из другой графы отчетности или, наконец, представляют города резко отличающимися от основной совокупности своими экологическими характеристиками. Проверим эти данные на «засорение», применив критерий Граббса:
Сравним полученные значения с табличным (при
Т3(1606.41) и Т4(1788.56) больше табличных следовательно значения 1606,41 и 1788,56 аномальные. Проведем более тщательную проверку этих значений при помощи критерия Титьена и Мура: Мы применяем Е – критерий так как имеем предположение, что имеются грубые ошибки как с наибольшим, так и с наименьшим засорением то есть в нашем случае это 4 ошибки. Проводятся расчеты по усеченным данным то есть данным в которых отсутствуют предполагаемые ошибки.
Сравним полученные результаты с табличными данными (см. приложение В.) Таблица Критические значения Са-оценки для Число наблюдений необходимо взять равное 20-ти и кол-во ошибок равное 4-ем 0,026 < 0,221 следовательно все значения (44,89; 55,26; 1606,41; 1788,56.) являются засорением. (Табличные данные берем при а=0,05) ВАРИАНТЫ ЗАДАНИЙ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Имеются следующие данные:
Используя приемы Граббса, Титьена и Мура, определите наличие грубых ошибок в совокупности данных.
4 МЕТОДЫ ИСЧИСЛЕНИЯ УСТОЙЧИВЫХ СТАТИСТИЧЕСКИХ ОЦЕНОК: ПУАНКАРЕ, ВИНЗОРА, ХУБЕРА После обнаружения выбросов в данных необходимо оценить параметры выборочной совокупности. При этом используется два метода: 1. Ошибки отбрасываются. Они исключаются из общей совокупности и расчеты проводятся по оставшимся данным. 2. Ошибки модифицируются, то есть ошибки заменяются на значения близкие к ним.
Пуанкаре предложил для расчета средней по усеченной совокупности (урезанной средней) формулу:
где
По Винзору средняя определяется также с заранее известным
Помимо средних величин по винзорированным данным могут быть найдены и другие показатели.
Помимо рассмотренных методов оценки широкое применение имеет классический подход Хубера. При это используется некоторая величина К, определяемая с учетом степени засорения статистической совокупности Оценка средней величины по Хуберу:
где
При расчетах по приведенной выше формуле в качестве начальной оценки Оценка Пример. Итак, рассчитаем устойчивые оценки. Для этого построим следующую таблицу:
Таблица 4 – Данные об количестве автомобилей отечественного производства.
Найдем значение параметра Найдем Теперь разобьем совокупность данных на 3 группы: 1. Не значительно отличающиеся от 2. Существенно меньше величины 3. Существенно превышающие Затем соответствующим образом модифицируем
Таблица 5 – Данные разбиты на совокупности.
Рассчитаем оценку
Возобновим итерацию по данным, модифицированным на предыдущем шаге:
Для второй итерации оценка
Чтобы удостовериться, что многомерное значение является действительно выбросом, обычно используют расстояние Махаланобиса:
где Х- Вектор признаковых значений, подозреваемых на выброс.
Критерий F для для проверки гипотезы о существенности отклонения случайного вектора Х строиться следующим образом:
Для F- критерия существуют числа а) Одно из наблюдений, которое предположительно является «засорением», подвергается проверке. Если предположение оправдывается, «выброс» устраняется из выборки; б) по усеченной совокупности многомерных объектов определяется новый вектор средних значений; в) проверке подвергается следующий объект, повторяются шаги а и б, и т.д. К выявленным грубым ошибкам в многомерной совокупности можно применять уже известные для одномерного случая приемы обработки данных: их устранение, или винзорирование. Итак, наиболее простые методы поиска ошибок Граббса, Титьена и Мура. Если в статистической совокупности действительно выявлены грубые ошибки, то применяем методы Пуанкаре, Хубера и Винзора.
ВАРИАНТЫ ЗАДАНИЙ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ Имеются сведения о размере прибыли, млн руб. (X1) и объёме основных производственных фондов (X2) по 20 производственным предприятиям:
Рассчитать обычную и устойчивую средние, используя методы Пуанкаре и Винзора, сравните полученные результаты.
РЕКОМЕНДУЕМАЯ ЛИТЕРАТУРА 1. Дубров А.М. Компонентный анализ и эффективность в экономике: Учебное пособие. – М.: Финансы и статистика. 2002. – 352 с. 2. Многомерный статистический анализ. А.М.Дубров, В.С.Мхитарян, Л.И. Трошин. – М.: «Финансы и статистика», 2000. – 352 с. 3. Многомерный статистический анализ в экономике. Л.А.Сошникова, В.Н.Тамашевич, Г.Уебе, М. Шеффер. – М.: «ЮНИТИ-ДАНА», 1999. – 598 с. 4. Прикладная статистика и основы эконометрики. С.А.Айвазян, В.С.Мхитарян. – М.: «ЮНИТИ», 1998. – 1022 с. 5. Решение математических задач средствами Excel: Практикум / В.Я. Гельман.— СПб.: Питер, 2003.-240 с. 6. http://www.exponenta.ru ПРИЛОЖЕНИЕ А
|
||
|
|
Последнее изменение этой страницы: 2018-05-10; просмотров: 1181. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
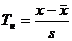
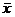 - среднее значение. Оценка выборочной средней находится по истинным данным либо
- среднее значение. Оценка выборочной средней находится по истинным данным либо 
 сравнивают с табличными значениями процентных точек критерия Смирнова Граббса (см. приложение А). Если
сравнивают с табличными значениями процентных точек критерия Смирнова Граббса (см. приложение А). Если  , то проверяемое значение является грубой ошибкой и относится к классу выбросов. Критерий Граббса имеет некоторые недостатки. Он не точен, и не чувствителен к засорениям когда ошибки группируются на расстоянии от общей совокупности.
, то проверяемое значение является грубой ошибкой и относится к классу выбросов. Критерий Граббса имеет некоторые недостатки. Он не точен, и не чувствителен к засорениям когда ошибки группируются на расстоянии от общей совокупности. ,
, - выборка наблюдений по какому-либо одному, j-му признаку;
- выборка наблюдений по какому-либо одному, j-му признаку; - средняя, которую рассчитывают по n – k наблюдениям, остающимися после отбрасывания k грубых ошибок «сверху» ранжированного ряда данных:
- средняя, которую рассчитывают по n – k наблюдениям, остающимися после отбрасывания k грубых ошибок «сверху» ранжированного ряда данных:
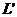 - критерий применяется для грубых ошибок в данных, расположенных в нижней части ранжированного ряда данных:
- критерий применяется для грубых ошибок в данных, расположенных в нижней части ранжированного ряда данных: ,
,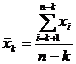 .
. ,
, - средняя, рассчитанная по «истинным» данным после отбрасывания из выборки наименьших (к) и наибольших
- средняя, рассчитанная по «истинным» данным после отбрасывания из выборки наименьших (к) и наибольших  - значений засоряющих совокупность данных:
- значений засоряющих совокупность данных: .
. имеют табулированное табличные критические значения для заданного уровня значимости α при известном объеме выборки n и предполагаемом числе ошибок К. Если наблюденные значения критериев оказываются меньше пороговых Са,к, то ошибки в данных, признаются грубыми. Иначе данные типичны для данной совокупности.
имеют табулированное табличные критические значения для заданного уровня значимости α при известном объеме выборки n и предполагаемом числе ошибок К. Если наблюденные значения критериев оказываются меньше пороговых Са,к, то ошибки в данных, признаются грубыми. Иначе данные типичны для данной совокупности.









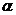 =0,10) при числе наблюдений равном 20 Ткр=2,447 (см. приложение Б).
=0,10) при числе наблюдений равном 20 Ткр=2,447 (см. приложение Б). 1,390729634 <
1,390729634 <  2.447
2.447 1,364776432 <
1,364776432 <  2,518736004 >
2,518736004 >  2,974754931 >
2,974754931 > 

 критерия Титьена и Мура (
критерия Титьена и Мура ( 
 ,
,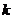 - число грубых ошибок.
- число грубых ошибок. - целая часть от произведения
- целая часть от произведения  .
. - объем выборочной совокупности за исключением ошибочных данных.
- объем выборочной совокупности за исключением ошибочных данных. - некоторая функция засорения выборки
- некоторая функция засорения выборки  (значения
(значения  ,
,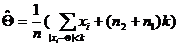 ,
, - Устойчивая оценка, определяется при помощи итеративных процедур;
- Устойчивая оценка, определяется при помощи итеративных процедур; -Численность группы наблюдений из совокупности, отличающихся наименьшими значениями:
-Численность группы наблюдений из совокупности, отличающихся наименьшими значениями:  , или значения в интервале (
, или значения в интервале (  );
); - Численность группы наблюдений из совокупности, отличающихся наибольшими значениями:
- Численность группы наблюдений из совокупности, отличающихся наибольшими значениями:  , или значения в интервале (
, или значения в интервале ( 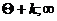 );
); может применяться обычная средняя арифметическая или медиана, оцененная по выборке. Затем на каждой итерации производится разделение выборочной совокупности на три части. В одну часть попадают «истинные» признаковые значения, которые остаются без изменения (
может применяться обычная средняя арифметическая или медиана, оцененная по выборке. Затем на каждой итерации производится разделение выборочной совокупности на три части. В одну часть попадают «истинные» признаковые значения, которые остаются без изменения (  ). В две другие части совокупности (для
). В две другие части совокупности (для  и
и  и
и  . По «истинным» и модифицированным данным каждый раз определяется новая оценка средней
. По «истинным» и модифицированным данным каждый раз определяется новая оценка средней 
 (для этого разделим кол-во ошибок (4) на количество данных всей совокупности (20) и посмотрим значение по специальной таблице (см. приложение Д). при значении
(для этого разделим кол-во ошибок (4) на количество данных всей совокупности (20) и посмотрим значение по специальной таблице (см. приложение Д). при значении 
 :
:

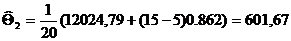
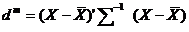
 - вектор средних значений для многомерной совокупности данных;
- вектор средних значений для многомерной совокупности данных; - Матрица ковариаций.
- Матрица ковариаций. .
. степеней свободы. При заданном уровне значимости
степеней свободы. При заданном уровне значимости  , проверяемое наблюдение действительно признается аномальным. В противном случае отклонение случайного от вектора средних значений считается приемлемым, а гипотеза о «засорении» совокупности отбрасывается.
, проверяемое наблюдение действительно признается аномальным. В противном случае отклонение случайного от вектора средних значений считается приемлемым, а гипотеза о «засорении» совокупности отбрасывается.

