|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Алгоритмы для больших объемов выборокПри обработке больших объемов данных приходится сталкиваться с двумя основными проблемами: 1) управление и обработка экспоненциально возрастающих объемов данных, которые часто поступают в реальном времени в виде потоков данных от массивов сенсоров или приборов, или генерируются в ходе имитационного моделирования; 2) существенное сокращение времени анализа данных, чтобы исследователи имели возможность своевременного принятия решений. Приложения, ориентированные исключительно на обработку больших объемов данных, имеют дело с наборами данных объемом от нескольких терабайт до петабайта. Как правило, эти данные поступают в нескольких разных форматах и часто распределены между несколькими местоположениями. Обработка подобных наборов данных обычно происходит в режиме многошагового аналитического конвейера, включающего стадии преобразования и интеграции данных. Требования к вычислениям обычно почти линейно возрастают при росте объема данных, и вычисления часто поддаются простому распараллеливанию. К основным исследовательским проблемам относятся управление данными, методы фильтрации и интеграции данных, эффективная поддержка запросов и распределенности данных.
Одним из направлений повышения эффективности обработки популярных предметных наборов является сокращение необходимого числа сканирований базы данных транзакций. Алгоритм Apriori сканирует базу данных несколько раз, в зависимости от числа элементов в предметных наборах. Существует ряд алгоритмов, позволяющих уменьшить необходимое число сканирований набора данных или количество популярных предметных наборов, генерируемые на каждом сканировании, либо оба этих показателя.  К усовершенствованным алгоритмам относятся: PARTITION, DIC, алгоритм случайной выборки. Алгоритм Partition Для уменьшения количества операций чтения данных в методе Partition было предложено разбивать исходную транзакционную базу данных D на части, помещающиеся в оперативной памяти ( Далее для всех наборов найденных для {r1, r2, ..., rv} за один проход по D производится проверка, является ли он часто встречающимся в D. Таким образом, количество проходов сокращается до двух.
|
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 430. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
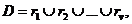 ). Затем для каждой части rj, таким же образом, как и в Apriori, выполняется поиск «локальных» часто встречающихся наборов. Если набор часто встречается в D, то он будет часто встречающимся хотя бы в одной из частей
). Затем для каждой части rj, таким же образом, как и в Apriori, выполняется поиск «локальных» часто встречающихся наборов. Если набор часто встречается в D, то он будет часто встречающимся хотя бы в одной из частей 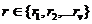 . Таким образом, на первом этапе определяется множество всех потенциально встречающихся наборов данных.
. Таким образом, на первом этапе определяется множество всех потенциально встречающихся наборов данных.