|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Оценка вероятности ошибочной классификации случайного лесаСтр 1 из 2Следующая ⇒ Ансамбли алгоритмов классификации и метод случайного леса
В последние несколько лет значительно возрос интерес к вопросу увеличения точностей моделей Data Mining, основанных на машинных методах обучения, за счет объединения усилий нескольких методов и создание ансамблей моделей, что позволяет повысить качество решения аналитических задач. Под обучением ансамбля алгоритмов понимается процедура обучения конечного набора базовых классификаторов, результаты прогнозирования которых, затем объединяются и формируют прогноз агрегированного классификатора. Целью создания ансамбля моделей является повышение точности прогноза агрегированного классификатора по сравнению с точностью прогнозирования каждого индивидуального базового классификатора. Можно выделить три причины, по которым объединение классификаторов может быть успешным: Статистическая причина. В условиях большого количества моделей, обученных примерно на одном и том же множестве наблюдений происходит поиск лучшей гипотезы о следующем состоянии системы или о ее структуре (свойствах). Этот процесс включает выдвижение и оценку гипотез. Выдвижение и оценка гипотез часто зависит от случайных факторов: разброс значений в наборе данных, выбор первой гипотезы, выбор последовательности примеров для классификации и т.д. Отдельно взятый алгоритм часто находит и "доказывает" на обучающем множестве гипотезу, которая затем не показывает точности на примерах, не вошедших в выборку. Однако, если использовать достаточно большое количество моделей обученных примерно на одном и том же множестве примеров мы можем уменьшить случайность полученного результата путем комбинирования результатов (например, путем их усреднения, голосования и т.д.). В этом случае случайные факторы и нестабильность алгоритмов начинает играть на повышение точности получаемых результатов. Модели уравновешивают случайность результатов друг друга, находя на основе баланса наиболее правдоподобное выходное значение. Это способствует нахождению наилучшего результата и минимизации ошибки. Теоретически можно показать, что усреднение по множеству моделей, построенных на основе независимых обучающих множеств, всегда уменьшает ожидаемое значение среднеквадратической ошибки.  Вычислительная причина. В основе всех инструментов вычисления оптимального решения лежит идея поиска экстремума некой регрессионной функции (линейной, нелинейной, сложной, неявной, др.) В большинстве случаев существует несколько экстремумов выбранной функции на предложенных для модели данных. Нужно учитывать сильную "чувствительность" к наборам данных таких алгоритмов как деревья решений или нейросети, что является обратной медалью их способности находить точные решения. Это ведет к нахождению алгоритмом обучения локального экстремума. Теоретически нет всеобъемлющего решения остановки поиска решения на локальном экстремуме. Таким образом, можно ожидать, что часть моделей вместо нахождения глобального экстремума предоставит в распоряжение исследователя локально правильное решения для части примеров. В то время как для других это решение будет далеко от оптимального. При возникновении проблемы в рассматриваемой плоскости также основополагающую роль играют случайные факторы. В решении данного вопроса также помогает использование нескольких (множества). В то время как мы может ожидать от отдельной модели остановку на локальном экстремуме, создание композиции из таких моделей подводит исследователя ближе к определению глобального экстремума и статистически "поддерживает" полученное решение. При использовании множества моделей поиск оптимума происходит из разных точек, используются разнообразные пути поиска верной гипотезы. В случае если мы случайно комбинирует примеры и их последовательность для обучения, используем максимальное количество случайных величин для настройки моделей настройках, используем разнообразные модели, полученные результаты приближаются к нормальному распределению Репрезентативная причина. Комбинированная гипотеза может не находиться в множестве возможных гипотез для базовых классификаторов, т.е. строя комбинированную гипотезу, мы расширяем множество возможных гипотез.
При формировании ансамбля моделей необходимо решить три задачи: - выбрать базовую модель; - определить подход к использованию обучающего множества; - выбрать метод комбинирования результатов. Так как ансамбль - это составная модель, состоящая из отдельных базовых моделей, то при его формировании возможны два случая: ансамбль состоит из базовых моделей одного типа, например, только из деревьев решений т. д.; ансамбль состоит из моделей различного типа - деревьев решений, регрессионных моделей и т. д. При построении ансамбля используется обучающее множество, для использования которого существуют два подхода: перевыборка, т. е. из исходного обучающего множества извлекается несколько подвыборок, каждая из которых используется для обучения одной из моделей ансамбля; использование одного обучающего множества для обучения всех моделей ансамбля. Для комбинирования результатов, выданных отдельными моделями, используют три способа: - голосование - выбирается тот класс, который был выдан простым большинством моделей ансамбля; - взвешенное голосование - для моделей ансамбля устанавливаются весы, с учетом которых выносится результат; - усреднение (взвешенной или невзвешенное) - выход всего ансамбля определяется как простое среднее значение выходов всех моделей, при взвешенном усреднении выходы всех моделей умножаются на соответствующие веса. К настоящему времени разработано множество различных методов и алгоритмов формирования ансамблей. Среди них наибольшее распространение получили такие методы, как беггинг (bagging), бустинг (boosting) и стэкинг (stacking). Алгоритм Bagging Главная идея алгоритма Bagging в реализации параллельного обучения на нескольких различных выборках одинакового размера, полученных путем случайного отбора наблюдений из исходного набора данных. Исходные данные D, состоящие из N строк, разделяются на t подмножеств Каждая запись из D имеет одинаковую вероятность быть выбранной в множество Разница между бэггингом и идеальной процедурой обучения моделей на независимых выборках, заключается в способе формирования обучающих множеств. Вместо получения независимых множеств из предметной области бэггинг просто производит перевыборку исходного множества данных. Такие множества отличаются друг от друга, но не являются независимыми, поскольку все они основаны на одном и том же множестве. Тем не менее бэггинг позволяет создавать комбинированные модели, которые, как правило, работают значительно лучше, чем отдельная модель. На практике алгоритм Bagging дает хорошее улучшение точности результатов (5-40\% при использовании базового алгоритма CART) по сравнению с индивидуальными базовыми классификаторами в случае, если алгоритм, используемый базовым классификатором достаточно точен, но нестабилен. Улучшение точности прогноза происходит за счет уменьшения разброса нестабильных прогнозов индивидуальных классификаторов. Преимуществом алгоритмаBagging является простота реализации, а также возможность распараллеливания вычислений по обучению каждого базового классификатора по различным вычислительным узлам. Недостатками являются: отсутствие строгого математического обоснования условий улучшения прогноза ансамбля; недетерминированность результата (обучающие выборки формируются случайно); сложность интерпретации результатов по сравнению с индивидуальными моделями.
Алгоритм Boosting Основная идея алгоритма Boosting заключается в построении цепочки моделей, при этом каждая следующая обучается на наблюдениях, на которых предыдущая допустила ошибку. По сравнению с алгоритмом Bagging алгорити Boosting является более сложной процедурой, но во многих случаях работает эффективнее. Boosting начинает создание ансамбля на основе единственного исходного множества, но в отличии от алгоритмаBagging каждая новая модель строится на основе результатов предыдущей, т. е. модели строятся последовательно. Boosting создает новые модели таким образом, чтобы они дополняли ранее построенные, выполняли ту работу, которую другие модели сделать не смогли на предыдущих шагах. И, наконец, последнее отличие алгоритма Boosting от алгоритмаBagging заключается в том, что всем построенным моделям в зависимости от их точности присваиваются веса. Алгоритм Boosting относится к итерационным алгоритмам. Он учится распознавать примеры на границах классов. Каждой записи данных на каждой итерации алгоритма присваивается вес. Первый классификатор обучается на всех примерах с равными весами. На каждой последующей итерации веса расставляются соответственно классифицированным примерам, т. е. веса правильно классифицированных примеров уменьшаются, а неправильно классифицированных - увеличиваются. Следовательно, приоритетными для следующего классификатора станут неправильно распознанные примеры, обучаясь на которых новый классификатор будет исправлять ошибки классификатора на прошлой итерации. В алгоритме Boosting базовые классификаторы обучаются последовательно, а не параллельно, как в алгоритме Bagging. Набор данных, на которых обучается каждый последующий базовый алгоритм в Boosting, зависит от точности прогнозирования предыдущего базового классификатора. Важным понятием в алгоритме Boosting является вес строки данных, который обновляется после каждой итерации (выполнения обучения базового классификатора). Значение веса строки описывает ее важность для обучения следующего базового классификатора и основывается на величине ошибки прогноза предыдущего классификатора на этой строке. Вес строки можно интерпретировать как вероятность ее выбора для обучения следующего классификатора или как число, пропорциональное относительной доли этой строки в следующей обучающей выборке. Второй подход представляется предпочтительней, так как является детерминистическим. Различные модификации алгоритма Boosting имеют одинаковую структуру: 1. Присвоить всем N строкам обучающей выборки одинаковые веса 2. В цикле от m=1 до M: Обучить базовый классификатор Вычислить взвешенную ошибку прогноза классификатора Пересчитать веса каждой строки в соответствии с ошибкой прогноза на этой строке: для правильно классифицированных строк вес уменьшается, для неправильных -- увеличивается. 3. Прогноз ансамбля вычисляется по (взвешенному) среднему или (взвешенному) большинству прогнозов базовых классификаторов. В случае использования весов, их значения больше у более точных базовых классификаторов. Одной из реализаций алгоритма Boosting является алгоритм AdaBoost (Adaptive Boosting). Алгоритм AdaBoost является адаптивным в том смысле, что каждый следующий классификатор строится по объектам, неверно классифицированным предыдущими классификаторами. Рассмотрим алгоритм построения бинарного классификатора для ансамбля из Пусть имеется выборка Для каждого наблюдения инициализируются веса: Для каждого базового классификатора Шаг 1. Находится классификатор
где Шаг 2. Если величина Шаг 3. Задается параметр
Шаг 4. Пересчитываются веса наблюдений:
где Параметр Результирующий классификатор строится следующим образом:
Отметим, что выражение для обновления распределения весов
Таким образом, после выбора оптимального классификатора Преимущества алгоритма Boosting: Алгоритм Boosting основывается на вероятностной модели и является аналогом хорошо исследованной логистической регрессии. Каждая итерация любой модификации алгоритма Boosting представляет собой шаг по минимизации функции взвешенного штрафа ошибки или шаг по максимизации функции условного ожидаемого правдоподобия данных. Экстремумы этих функций являются истинными значениями классификационной функции модели. Т.е. алгоритм Boosting имеет статистическое обоснование. Ошибка классификационной функции ансамбля на обучающей выборке при достаточно слабых условиях на точность базовых классификаторов стремится к нулю при увеличении числа итераций. Всё это делает алгоритм Boosting теоретически исследованным и обоснованным методом из существующих. Недостатки алгоритма Boosting: Так как на каждой итерации алгоритм уделяет все большее внимание неправильно классифицированным строкам, то в случае зашумления данных, алгоритм на больших итерациях будет полностью сконцентрирован на попытках получить прогноз на имеющихся ошибочных записях, а не на выявлении объективных закономерностей. Последовательность выполнения обучения базовых классификаторов не позволяет использовать распараллеливание вычислительных мощностей. Результаты классификации ансамбля трудны для интерпретации. Алгоритм Stacking Алгоритм Stacking не основывается на математической модели. Его идея заключается в использовании в качестве базовых моделей различных классификационных алгоритмов, обучаемых на одинаковых данных. Затем, мета-классификатор обучается на исходных данных, дополненных результатами прогноза базовых алгоритмов. Иногда мета-классификатор использует при обучении не результаты прогноза базовых алгоритмов, а полученные ими оценки параметров распределения, например, оценки вероятностей каждого класса. Идея алгоритма Stacking заключается в том, что мета-алгоритм учится различать какому из базовых алгоритмов следует «доверять» на каких областях входных данных. АлгоритмStacking обучается с использованием перекрестной валидации (cross-validation): данные случайным образом n раз делятся на две части:
Метод случайного леса Метод основан на построении большого числа (ансамбля) деревьев решений (это число является параметром метода), каждое из которых строится по выборке, получаемой из исходной обучающей выборки с помощью бутстрепа (т. е. выборки с возвращением). В отличие от классических алгоритмов построения деревьев решений в методе случайных Метод «случайный лес» обладает следующими особенностями: для построения случайного леса по обучающей выборке требуется задание всего двух параметров, которые требуют минимальной настройки; метод Out-Of-Bag (OOB) обеспечивает получение естественной оценки вероятности ошибочной классификации случайных лесов на основе наблюдений, не входящих в обучающие бутстреп выборки, используемые для построения деревьев (эти наблюдения называются OOB выборками); случайные леса могут использоваться не только для задач классификации и регрессии, но и для задач выявления наиболее информативных признаков, кластеризации, выделения аномальных наблюдений и определения прототипов классов; обучающая выборка для построения случайного леса может содержать признаки, измеренные в разных шкалах: числовой, порядковой и номинальной, что недопустимо для многих других классификаторов; cлучайные леса обеспечивают существенное повышение точности, так как деревья в ансамбле слабо коррелированны вследствие двойной инъекции случайности в индуктивный алгоритм — посредством баггинга и использования метода случайных подпространств при расщеплении каждой вершины; алгоритмически сложная задача усечения полного дерева решений снимается, поскольку деревья в случайном лесу не усекаются (это также приводит к высокой вычислительной эффективности);
Алгоритм случайного леса Алгоритм построения случайного леса может быть представлен в следующем виде. • По бутстреп выборке (в) расщепить выборку, соответствующую обрабатываемой вершине, на две подвыборки;
Оценка вероятности ошибочной классификации случайного леса Одно из достоинств случайных лесов состоит в том, что для оценки вероятности ошибочной классификации нет необходимости использовать кросс–проверку или экзаменационную выборку‘. Оценка вероятности ошибочной классификации случайного леса осуществляется методом "Out–Of–Bag" (OOB), состоящем в следующем. Известно, что каждая бутстреп выборка не содержит примерно 37 %наблюдений исходной обучающей выборки (поскольку выборка с возвращением, то некоторые наблюдения в нее не попадают, а некоторые попадают несколько раз). Классифицируем некоторый вектор |
||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 493. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |
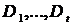 с тем же числом строк в каждом при помощи равномерной случайной выборки с возвратом. Затем, t базовых классификаторов, используя один и тот же алгоритм, обучаются на этих подмножествах. Результаты прогнозирования базовых классификаторов усредняются или выбирается класс на основании большинства голосов.
с тем же числом строк в каждом при помощи равномерной случайной выборки с возвратом. Затем, t базовых классификаторов, используя один и тот же алгоритм, обучаются на этих подмножествах. Результаты прогнозирования базовых классификаторов усредняются или выбирается класс на основании большинства голосов.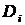 , т.е.
, т.е. 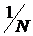 , значит, вероятность не быть выбранной равна
, значит, вероятность не быть выбранной равна 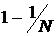 . Так как каждое из множеств
. Так как каждое из множеств 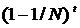 , следовательно, вероятность, что запись хотя бы раз будет выбрана, равна
, следовательно, вероятность, что запись хотя бы раз будет выбрана, равна 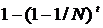 .
. на данных, распределение строк в которых соответствует весам этих строк.
на данных, распределение строк в которых соответствует весам этих строк. базовых классификаторов.
базовых классификаторов.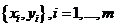 , где
, где 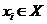 ,
, 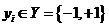 ,
, 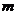 - число наблюдений, каждое наблюдение которой относится к одному из двух классов.
- число наблюдений, каждое наблюдение которой относится к одному из двух классов.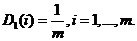
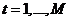 выполняются следующие шаги.
выполняются следующие шаги. , который минимизирует взвешенную ошибку классификации:
, который минимизирует взвешенную ошибку классификации: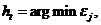

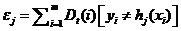 .
.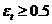 , то алгоритм прекращает работу.
, то алгоритм прекращает работу.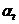 следующим образом:
следующим образом: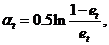
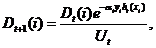
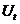 - нормализующий параметр.
- нормализующий параметр.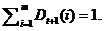
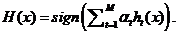
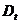 должно быть сконструировано таким образом, чтобы выполнялось условие:
должно быть сконструировано таким образом, чтобы выполнялось условие: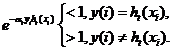 (1)
(1)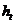 для распределения весов
для распределения весов 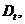 наблюдения
наблюдения 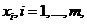 которые классификатор
которые классификатор 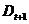 согласно (1), то алгоритм будет выбирать классификатор, который лучше идентифицирует наблюдения неверно распознанные предыдущим классификатором.
согласно (1), то алгоритм будет выбирать классификатор, который лучше идентифицирует наблюдения неверно распознанные предыдущим классификатором. 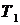 и
и 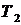 . Базовые алгоритмы обучаются на данных из
. Базовые алгоритмы обучаются на данных из 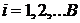 = 1, 2,...,B (здесь
= 1, 2,...,B (здесь 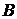 — количество деревьев в ансамбле) выполнить
— количество деревьев в ансамбле) выполнить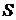 размера
размера 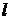 по исходной обучающей выборке
по исходной обучающей выборке 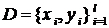
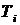 с минимальным количеством наблюдений в терминальных вершинах равным
с минимальным количеством наблюдений в терминальных вершинах равным 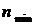 , рекурсивно следуя следующему подалгоритму:
, рекурсивно следуя следующему подалгоритму: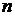 признаков случайно выбрать
признаков случайно выбрать 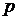 признаков;
признаков;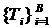 .
.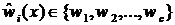 – класс, предсказанный деревом решений
– класс, предсказанный деревом решений 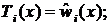 ; тогда
; тогда 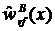 — класс, наиболее часто встречающийся в множестве
— класс, наиболее часто встречающийся в множестве 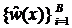 .
.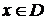 . Для классификации используются только те деревья случайного леса, которые строились по бутстреп выборкам, не содержащим
. Для классификации используются только те деревья случайного леса, которые строились по бутстреп выборкам, не содержащим 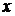 , и как обычно используется метод голосования. Частота ошибочно классифицированных векторов обучающей выборки при таком способе классификации и представляет собой оценку вероятности ошибочной классификации случайного леса методом OOB. Практика применения оценки OOB показала, что в случае, если количество деревьев достаточно велико, эта оценка обладает высокой точностью. Если число деревьев мало, то оценка имеет положительное смещение.
, и как обычно используется метод голосования. Частота ошибочно классифицированных векторов обучающей выборки при таком способе классификации и представляет собой оценку вероятности ошибочной классификации случайного леса методом OOB. Практика применения оценки OOB показала, что в случае, если количество деревьев достаточно велико, эта оценка обладает высокой точностью. Если число деревьев мало, то оценка имеет положительное смещение.