|
Студопедия КАТЕГОРИИ: АвтоАвтоматизацияАрхитектураАстрономияАудитБиологияБухгалтерияВоенное делоГенетикаГеографияГеологияГосударствоДомЖурналистика и СМИИзобретательствоИностранные языкиИнформатикаИскусствоИсторияКомпьютерыКулинарияКультураЛексикологияЛитератураЛогикаМаркетингМатематикаМашиностроениеМедицинаМенеджментМеталлы и СваркаМеханикаМузыкаНаселениеОбразованиеОхрана безопасности жизниОхрана ТрудаПедагогикаПолитикаПравоПриборостроениеПрограммированиеПроизводствоПромышленностьПсихологияРадиоРегилияСвязьСоциологияСпортСтандартизацияСтроительствоТехнологииТорговляТуризмФизикаФизиологияФилософияФинансыХимияХозяйствоЦеннообразованиеЧерчениеЭкологияЭконометрикаЭкономикаЭлектроникаЮриспунденкция |
Классификация новых наблюденийСтр 1 из 2Следующая ⇒ Деревья решений Деревья решений – один из методов автоматического анализа данных. Построение деревьев классификации– один из наиболее важных приемов, используемых при проведении "добычи данных и разведывательного анализа" (Data Mining), реализуемый как совокупность методов аналитической обработки больших массивов информации с целью выявить в них значимые закономерности и/или систематические связи между предикторными переменными, которые затем можно применить к новым совокупностям измерений. Есть целый ряд причин, делающих деревья классификации более гибким средством, чем традиционные методы анализа: · схема одномерного ветвления, которая позволяет изучать эффект влияния отдельных предикторных переменных и проводить последовательный анализ их вклада; · возможность одновременно работать с переменными различных типов, измеренных в непрерывных и порядковых шкалах, либо осуществлять любое монотонное преобразование признаков; · отсутствие предварительных предположений о законах распределения данных. Терминология
Деревья решений представляют собой последовательные иерархические структуры, состоящие из узлов, которые содержат правила, т.е. логические конструкции вида "если … то …". Конечными узлами дерева являются "листья", соответствующие найденным решениям и объединяющие некоторое количество объектов классифицируемой выборки. Это похоже на то, как положение листа на дереве можно задать, указав ведущую к нему последовательность ветвей, начиная от корня и кончая самой последней веточкой, на которой лист растет. 
Область применения деревья решений: · Описание данных: Деревья решений позволяют хранить информацию о данных в компактной форме, вместо них мы можем хранить дерево решений, которое содержит точное описание объектов. · Классификация: Деревья решений отлично справляются с задачами классификации, т.е. отнесения объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения. · Регрессия: Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых (входных) переменных. Например, к этому классу относятся задачи численного прогнозирования (предсказания значений целевой переменной). Построение дерева решений Основная идея построения деревьев решений из некоторого обучающего множества Х, сформулированная в интерпретации Р. Куинлена, состоит в следующем. Пусть в некотором узле дерева сконцентрировано некоторое множество наблюдений Х*, Х*ÌХ. Тогда существуют три возможные ситуации. 1. Множество Х* содержит одно или более наблюдений, относящихся к одному классу yk. Тогда дерево решений для Х* – это "лист", определяющий класс yk . 2. ·Множество Х* не содержит ни одного наблюдения, т.е. представляет пустое множество. Тогда это снова "лист", и класс, ассоциированный с "листом", выбирается из другого множества, отличного от Х* (скажем, из множества, ассоциированного с родителем). 3. Множество Х* содержит наблюдения, относящиеся к разным классам. В этом случае следует разбить множество Х* на некоторые подмножества. Для этого выбирается один из признаков j, имеющий два и более отличных друг от друга значений и Х* разбивается на новые подмножества, где каждое подмножество содержит все наблюдения, имеющие определенный диапазон значений выбранного признака. Это процедура будет рекурсивно продолжаться до тех пор, пока любое подмножество Х* не будет состоять из наблюдений, относящихся к одному и тому же классу. Описанная процедура построения дерева решений сверху вниз, называемая схемой "разделения и захвата" (divide and conquer), лежит в основе многих современных методов построения деревьев решений. Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction). На сегодняшний день существует значительное число алгоритмов, реализующих построение деревьев решений, из которых наибольшее распространение и популярность получили следующие: · CART (Classification and Regression Tree), разработанный Л. Брейманом с соавторами [Breiman et al., 1984], представляет собой алгоритм построения бинарного дерева решений – дихотомической классификационной модели; каждый узел дерева при разбиении имеет только двух потомков; как видно из его названия, алгоритм решает задачи как классификации, так и регрессии; · C4.5 – алгоритм построения дерева решений с неограниченным количеством потомков у узла, разработанный Р. Куинленом [Quinlan, 1993]; не умеет работать с непрерывным целевым полем, поэтому решает только задачи классификации; · QUEST (Quick, Unbiased, Efficient Statistical Trees) – программа, разработанная В. Ло и И. Ши [Loh, Shih,1997], в которой используются улучшенные варианты метода рекурсивного квадратичного дискриминантного анализа, позволяющие реализовать многомерное ветвление по линейным комбинациям порядковых предикторов; содержит ряд новых средств для повышения надежности и эффективности индуцируемых деревьев классификации. Этапы построения деревьев решений При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия признака, по которому пойдет разбиение, остановки обучения и отсечения ветвей. Правило разбиения Для построения дерева c одномерным ветвлением, находясь на каждом внутреннем узле, необходимо найти такое условие проверки, связанное с одной из переменных j, которое бы разбивало множество, ассоциированное с этим узлом на подмножества. Общее правило для выбора опорного признака можно сформулировать следующим образом: «выбранный признак должен разбить множество Х* так, чтобы получаемые в итоге подмножества Х*k , k = 1, 2, …, p, состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество чужеродных объектов из других классов в каждом из этих множеств было как можно меньше». Были разработаны различные критерии, например, теоретико-информационный критерий:
где H(Х*) и H(Х*k ) – энтропия подмножеств, разбитых на классы, рассчитанная по формуле Шеннона. Выбирается признак, дающий максимальное значение по критерию (1). Алгоритм CART использует так называемый индекс Gini (в честь итальянского экономиста Corrado Gini), который оценивает "расстояние" между распределениями классов.
где c – текущий узел, а pj – вероятность (относительная частота) класса j в узле c. Если набор Т разбивается на две части Т1 и Т2 с числом примеров в каждом N1 и N2 соответственно, тогда показатель качества разбиения будет равен:
Наилучшим считается то разбиение, для которого Ginisplit(T) минимально. Большинство из известных алгоритмов являются "жадными алгоритмами": если один раз был выбран атрибут и по нему произведено разбиение на подмножества, то алгоритм не может вернуться назад и выбрать другой атрибут, который дал бы лучшее разбиение. И поэтому на этапе построения дерева нельзя сказать даст ли выбранный атрибут, в конечном итоге, оптимальное разбиение. Правило остановки В дополнение к основному методу построения деревьев решений были предложены следующие правила: · Использование статистических методов для оценки целесообразности дальнейшего разбиения. В конечном счете "ранняя остановка" процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна. · Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение. · Разбиение должно быть нетривиальным, т.е. получившиеся в результате узлы должны содержать не менее заданного количества наблюдений. Правило отсечения Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые "переполнены данными", имеют много узлов и ветвей. Такие "ветвистые" деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из все меньшего количества объектов. Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и в целях анализа данных такое правило практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки. Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей. Пусть под точностью дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных. Предположим, что нам известен способ оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило: · построить дерево; · отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки. В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом.
Классификация новых наблюдений После индукции дерева решений его можно использовать для распознавания класса нового объекта. Обход дерева решений начинается с корня дерева. На каждом внутреннем узле проверяется значение объекта Xт по атрибуту, который соответствует алгоритму проверки в данном узле, и, в зависимости от полученного ответа, находится соответствующее ветвление, и по этой дуге осуществляется движение к узлу, находящему на уровень ниже и т.д. Обход дерева заканчивается, как только встретится узел решения, который и дает название класса объекта Xт.
|
||||||||||||||||||
|
|
Последнее изменение этой страницы: 2018-04-12; просмотров: 310. stydopedya.ru не претендует на авторское право материалов, которые вылажены, но предоставляет бесплатный доступ к ним. В случае нарушения авторского права или персональных данных напишите сюда... |

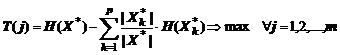 , (1)
, (1)

